Helping you master AI daily with step-by-step AI guides, latest news, & practical tools • DM for Collabs
 1/The readability gap by race.
1/The readability gap by race.
 1/ Imagine you take a test at one company. You fail. That is fine. You move on and apply to the next company.
1/ Imagine you take a test at one company. You fail. That is fine. You move on and apply to the next company.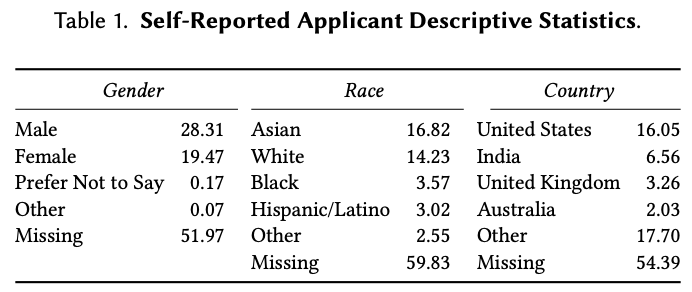
 1/ The math in one chart.
1/ The math in one chart.
 Raymond Hill lives in Quebec.
Raymond Hill lives in Quebec. 1/ The word "delve" tells the whole story.
1/ The word "delve" tells the whole story.
 1/ The growth curve.
1/ The growth curve.
 1/ The amplification effect in one chart.
1/ The amplification effect in one chart.
 1. Reflexivity Detection
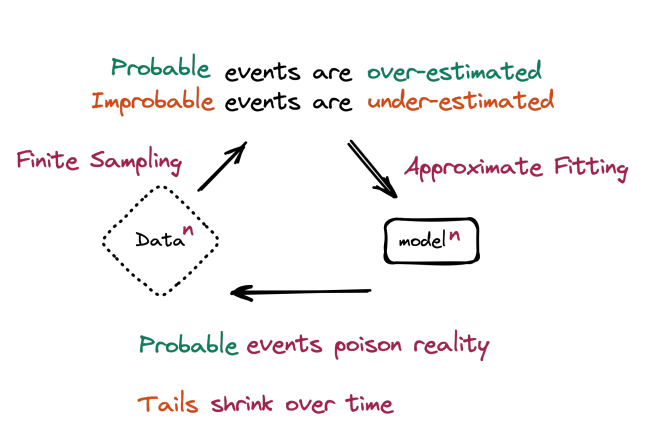
1. Reflexivity Detection 1/ The death spiral in one chart.
1/ The death spiral in one chart.