
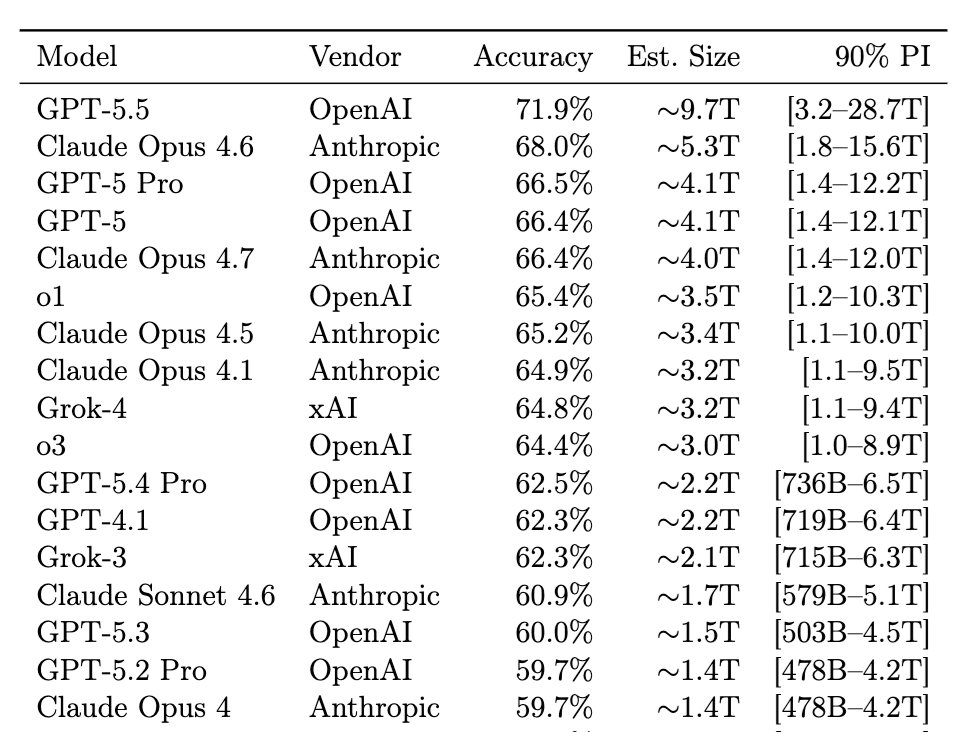
A recent viral paper claims to reverse-engineer the parameter counts of frontier models: GPT-5.5 = 9.7T, Opus 4.7 = 4.0T, o1 = 3.5T, etc.
@ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).
@ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).
The paper, “Incompressible Knowledge Probes” (by @bojie_li), constructs a dataset of 1400 factual questions, and fits accuracy against parameter count.
By inverting the fit, Li infers the parameter count of closed-source models from their dataset scores.
arxiv.org/abs/2604.24827
By inverting the fit, Li infers the parameter count of closed-source models from their dataset scores.
arxiv.org/abs/2604.24827
@ben_sturgeon and I read the paper and reproduced the author’s results. We identified two serious methodological/data issues. The core idea behind the paper – the linear relationship between IKP score and log parameter count – survives, but the parameter count estimates do not.
Two issues impact the results.
Issue 1: Paper says scores aren't floored at 0 "to preserve the bluff signal" in §4.3. But released code floors them (as do the numbers Li reports).
Correcting this reduces the score of small models and halves the param/score regression slope.
Issue 1: Paper says scores aren't floored at 0 "to preserve the bluff signal" in §4.3. But released code floors them (as do the numbers Li reports).
Correcting this reduces the score of small models and halves the param/score regression slope.

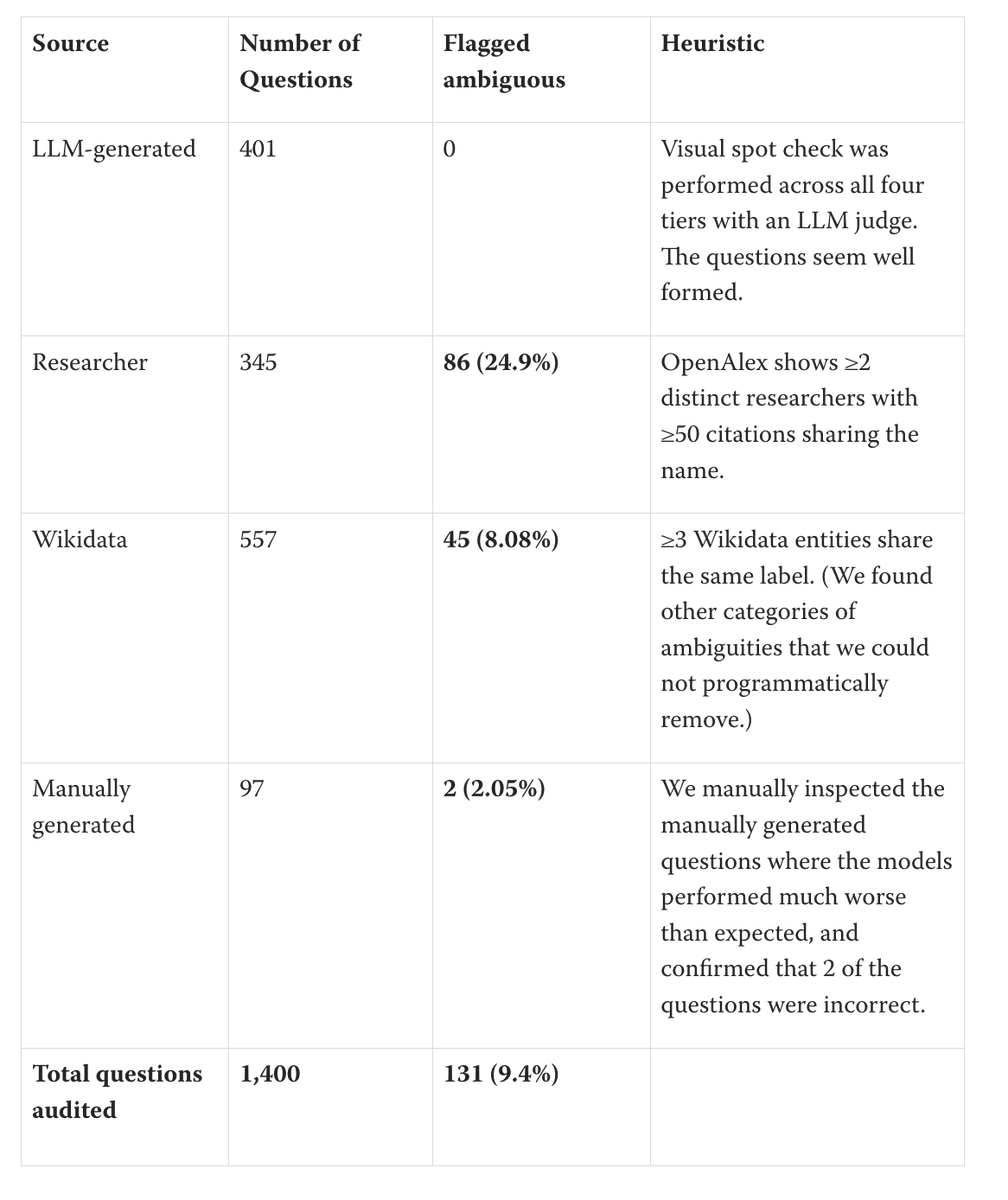
Issue 2: many hard questions are ambiguous or wrong.
We found ~25% of researcher questions and >8% of Wikidata questions refer to ambiguous entities. Others have ambiguous gold answers. Some questions have gold answers that are incorrect. We expect more that we didn't catch.
We found ~25% of researcher questions and >8% of Wikidata questions refer to ambiguous entities. Others have ambiguous gold answers. Some questions have gold answers that are incorrect. We expect more that we didn't catch.
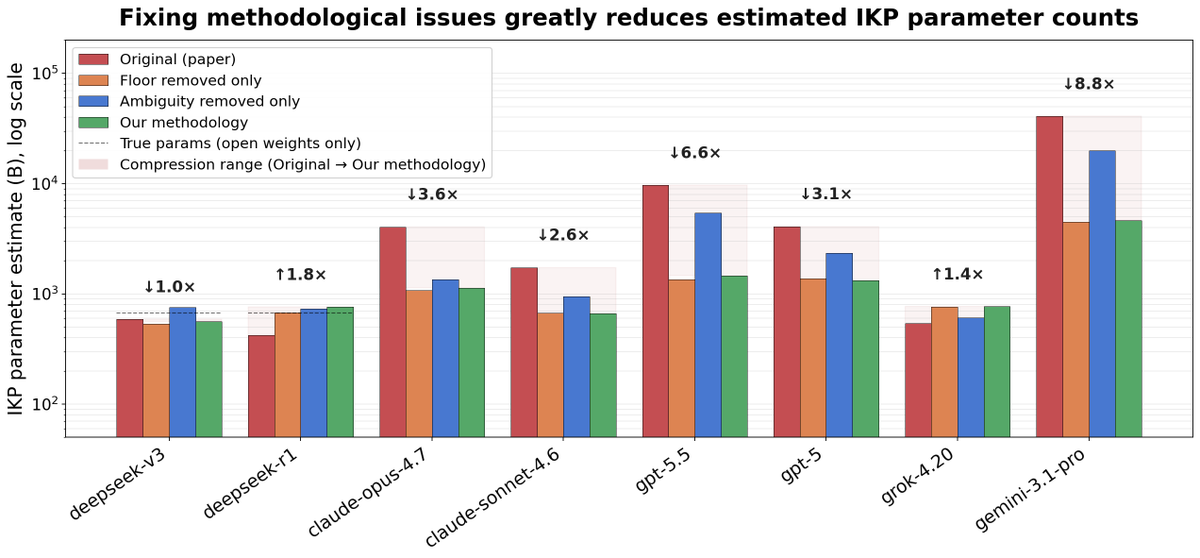
After fixing both issues, IKP-derived frontier model estimated parameter counts generally drop, and confidence intervals widen:
GPT 5.5: 9.7T -> 1.5T
Claude Opus 4.7: 4.0T -> 1.1T
DeepSeek R1 (true size 671B): 424B -> 760B
GPT 5.5: 9.7T -> 1.5T
Claude Opus 4.7: 4.0T -> 1.1T
DeepSeek R1 (true size 671B): 424B -> 760B

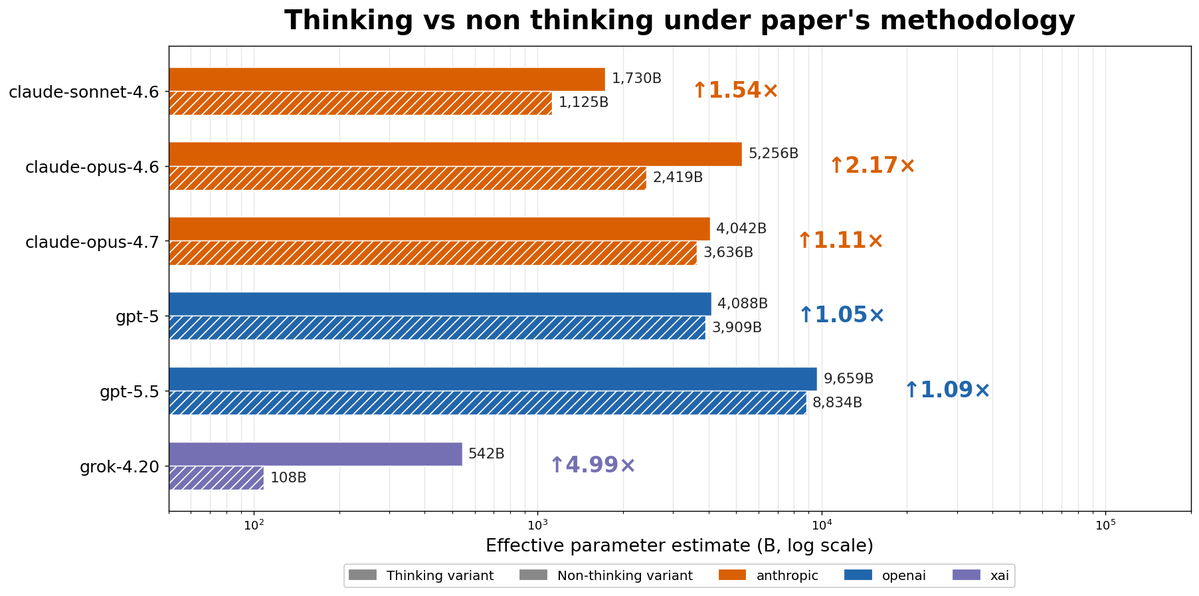
Interestingly, two methodological issues did not affect the results: disabling vs enabling thinking affects parameter counts much less after our fixes, and various incorrect values in JSONs contained in the repository were not used to generate the paper’s numbers or figures.
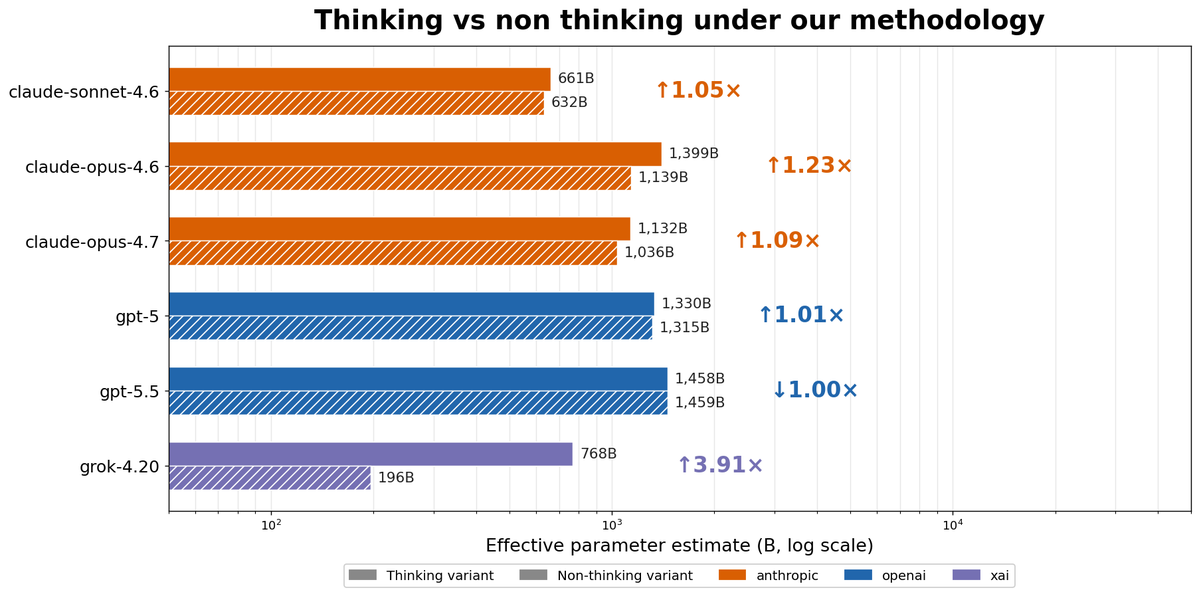
That being said, three of Li's claims survived every stress test:
1) IKP scores scales log-linearly with params
2) Xiao et al.’s “densing law” doesn't apply to IKP score over time
3) MoE total params predict knowledge better than active
Just not his frontier parameter counts.
1) IKP scores scales log-linearly with params
2) Xiao et al.’s “densing law” doesn't apply to IKP score over time
3) MoE total params predict knowledge better than active
Just not his frontier parameter counts.
The author claimed on Zhihu that this work was done by an AI agent in 4 days. It shows.
The website and codebase bear obvious hallmarks of careless vibe-coding: inconsistent definitions, silent failures, code that contradicts the paper text, etc.
zhihu.com/pin/2032769685…
The website and codebase bear obvious hallmarks of careless vibe-coding: inconsistent definitions, silent failures, code that contradicts the paper text, etc.
zhihu.com/pin/2032769685…
We wrote up our investigation in detail, including a full summary of the IKP paper, our updated methodology and resulting parameter counts, and the precautions we took to ensure that our AI agents produced real results.
You can find the full post here:
lesswrong.com/posts/veFMEzDD…
You can find the full post here:
lesswrong.com/posts/veFMEzDD…
• • •
Missing some Tweet in this thread? You can try to
force a refresh











