
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Major essay in Import AI 455, just published online. 

A lot of the conclusion comes from assembling a mosaic out of many distinct data sources. Some examples - progress on CORE-Bench, where the task is implementing other research papers (huge amounts of AI research comes from interpreting and replicating results)

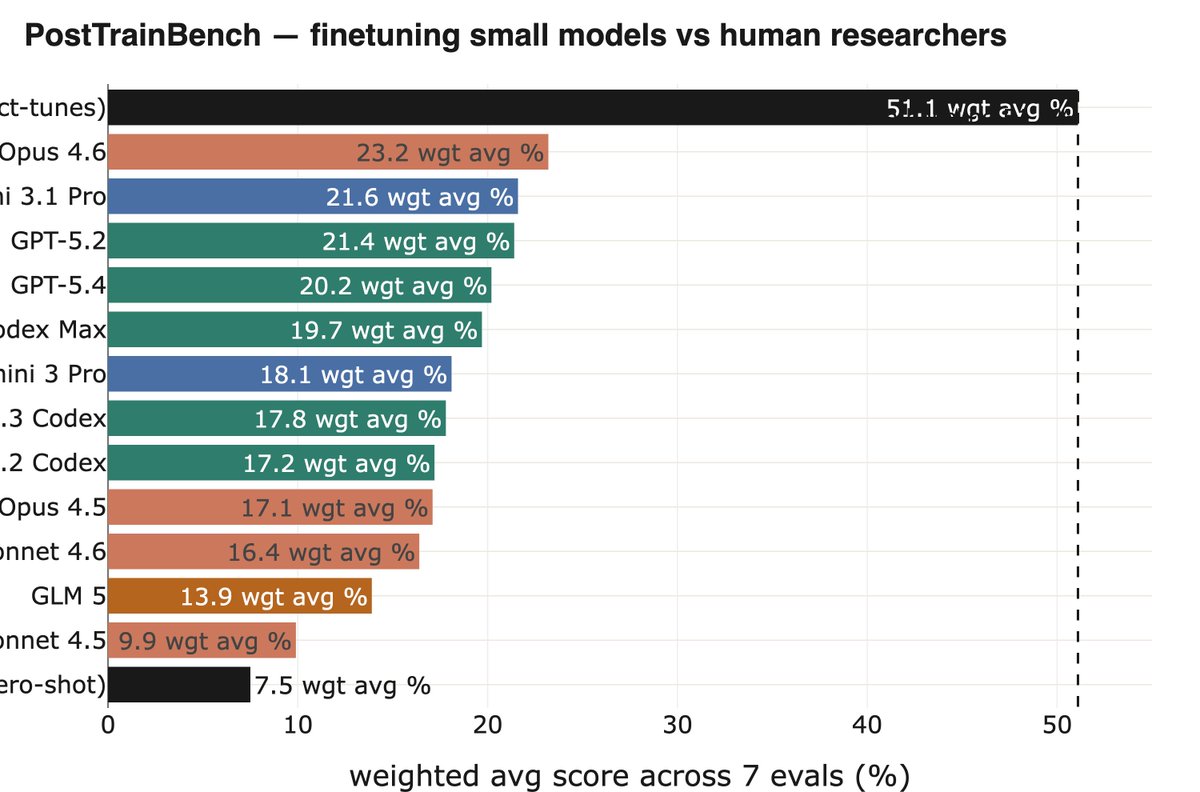
Another nice example is PostTrainBench from @karinanguyen et al, where you need to autonomously have powerful models (e.g, Opus 4.6) finetune weaker open weight models to improve perf on some benchmarks. This is an important subset of the overall task of AI R&D.
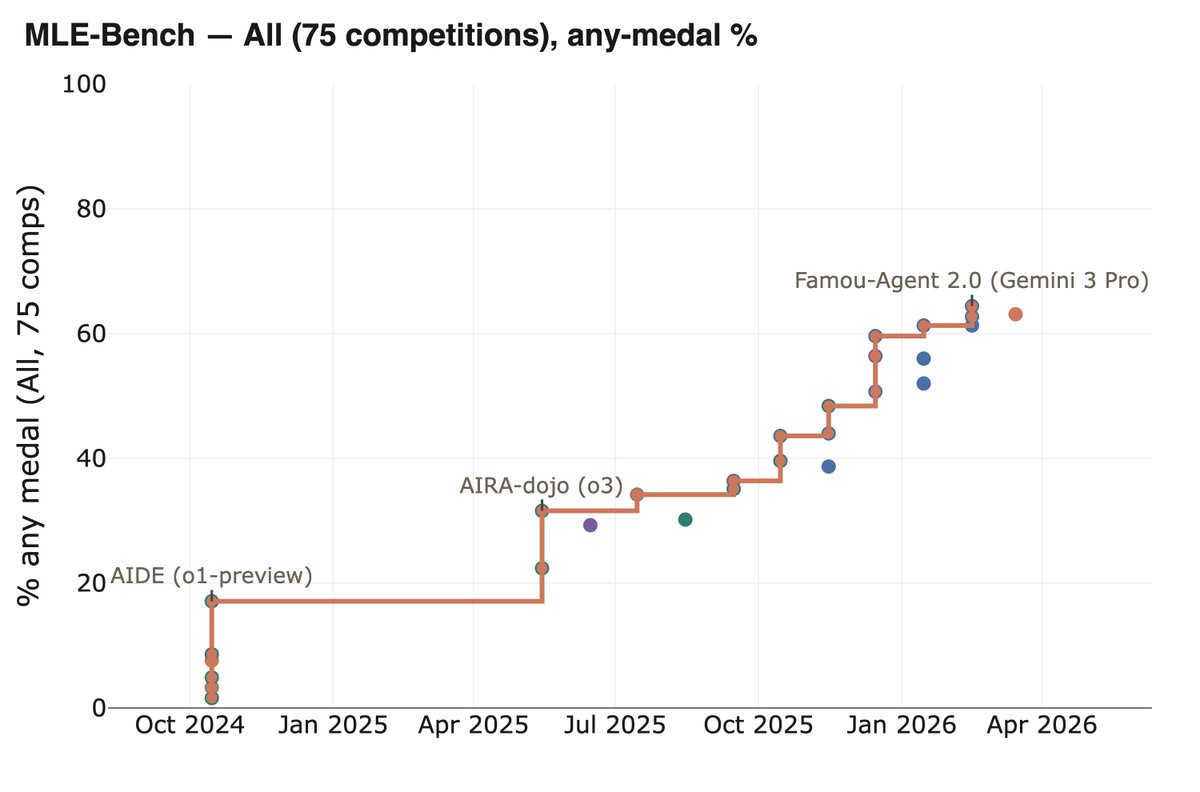
@karinanguyen There's also MLE-Bench, which is ecologically valid (tasks come from real kaggle competitions) and involves building a very diverse set of ML apps to solve specific problems. The same progress shows up here.
@karinanguyen My whole experience doing this project was finding endless "up and to the right" graphs at all resolutions of AI R&D, from the well known (e.g., SWE-Bench) to more niche (like those above). It's a fractal, but at all the resolutions you see the same trend of meaningful progress.
• • •
Missing some Tweet in this thread? You can try to
force a refresh








