The next wave of AI will not be won by better prompts. It will be won by systems that learn from experience.
Today, Prime Intellect Lab is out of beta, open for you to start training your own models.
The era of self-improving agents is here.
Today, Prime Intellect Lab is out of beta, open for you to start training your own models.
The era of self-improving agents is here.
Previously, improving a model meant waiting on the frontier labs.
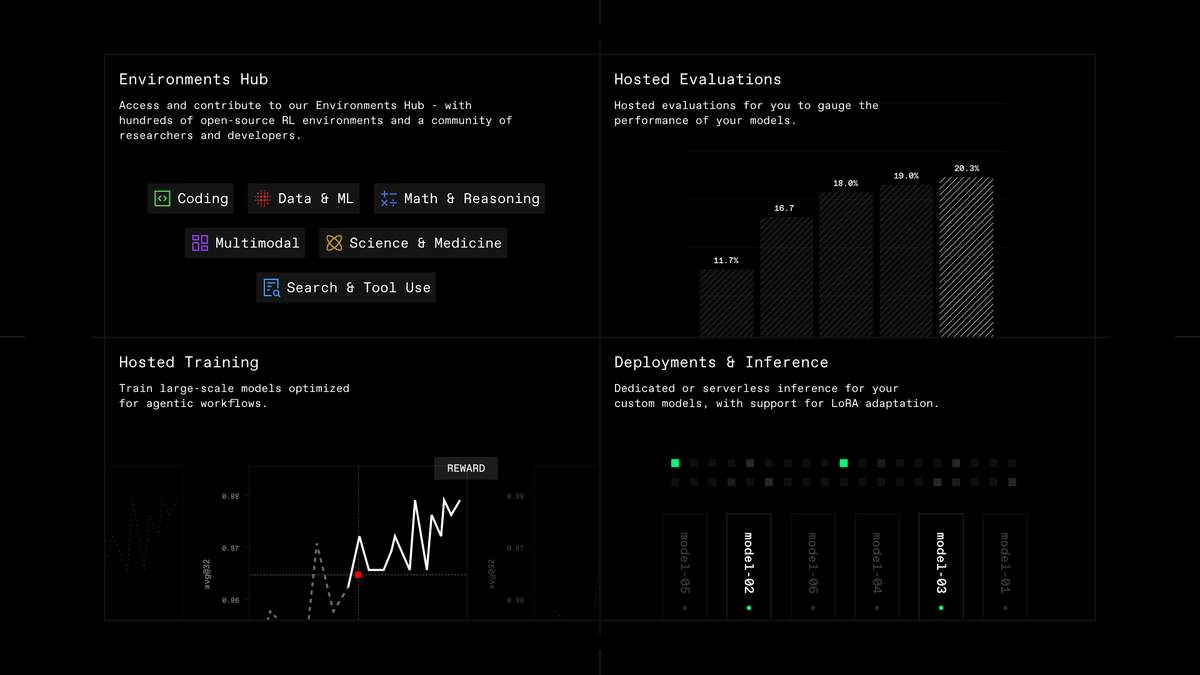
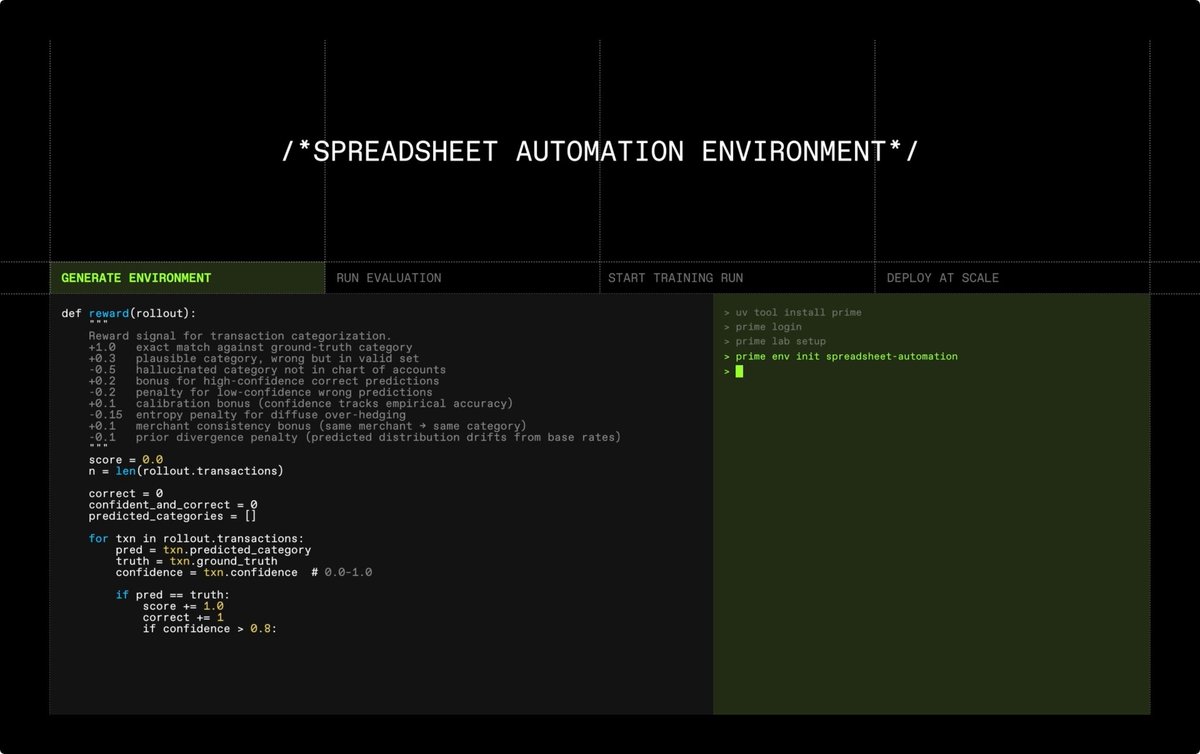
Lab brings the model improvement engine right to you:
Build. Evaluate. Train. Deploy.
Lab brings the model improvement engine right to you:
Build. Evaluate. Train. Deploy.

Lab is launching with self-serve support for models from Nvidia, OpenAI, Meta, Qwen, with more coming soon.
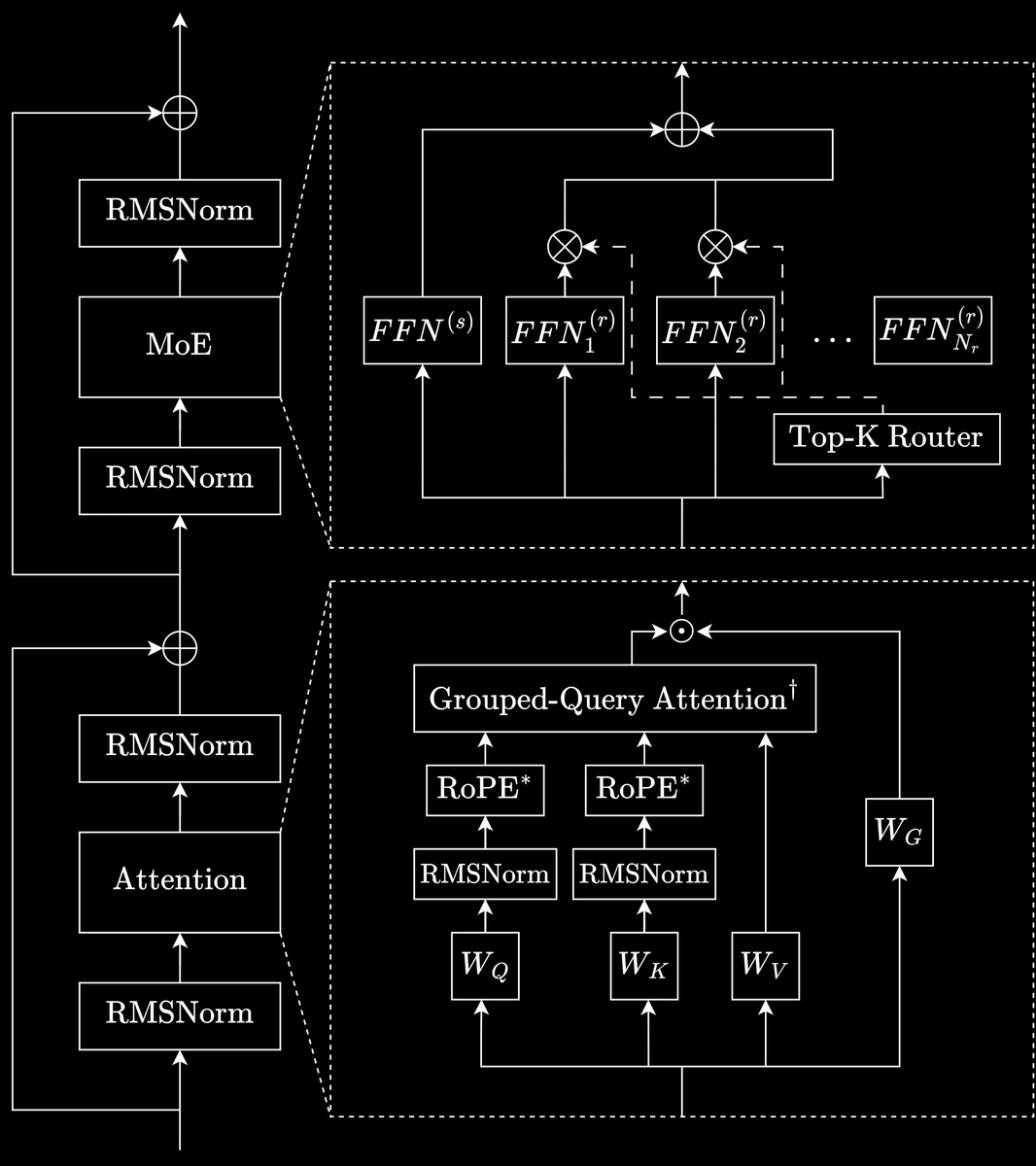
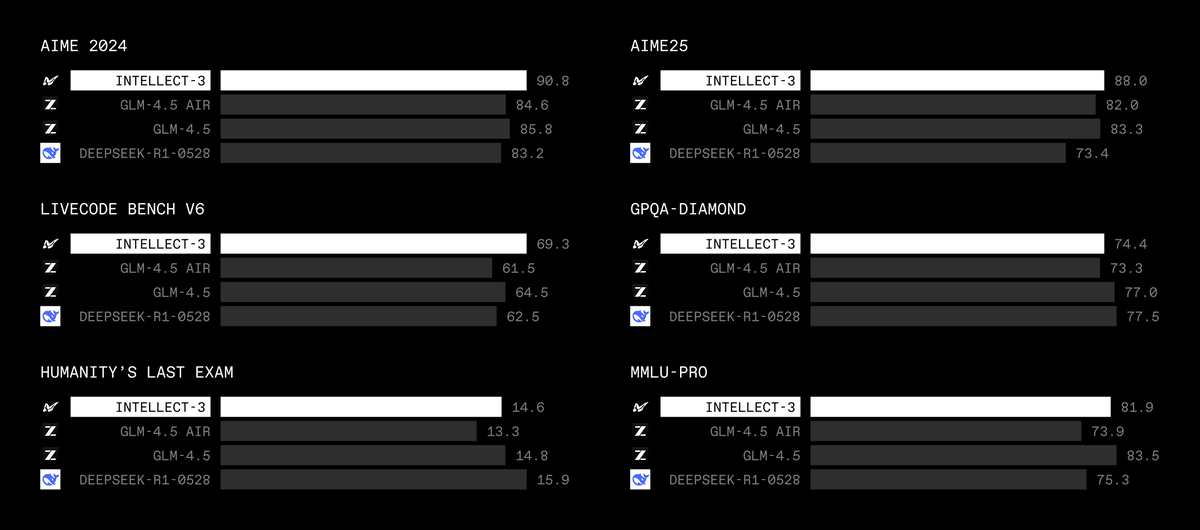
Models range from 1B to 400B parameters covering both dense and MoE architectures, reasoning and non-reasoning modes, and text and image modalities.
Models range from 1B to 400B parameters covering both dense and MoE architectures, reasoning and non-reasoning modes, and text and image modalities.

Under the hood, Lab runs on prime-rl.
We leverage multi-tenant LoRA for async RL and other algorithms, unlocking competitive per-token pricing.
This means you only pay as you go, without worrying about optimizing GPU clusters.
We leverage multi-tenant LoRA for async RL and other algorithms, unlocking competitive per-token pricing.
This means you only pay as you go, without worrying about optimizing GPU clusters.

Beta users ran 10,000+ training jobs on Lab. They trained agents for browser use, data workflows, and long-horizon coding.
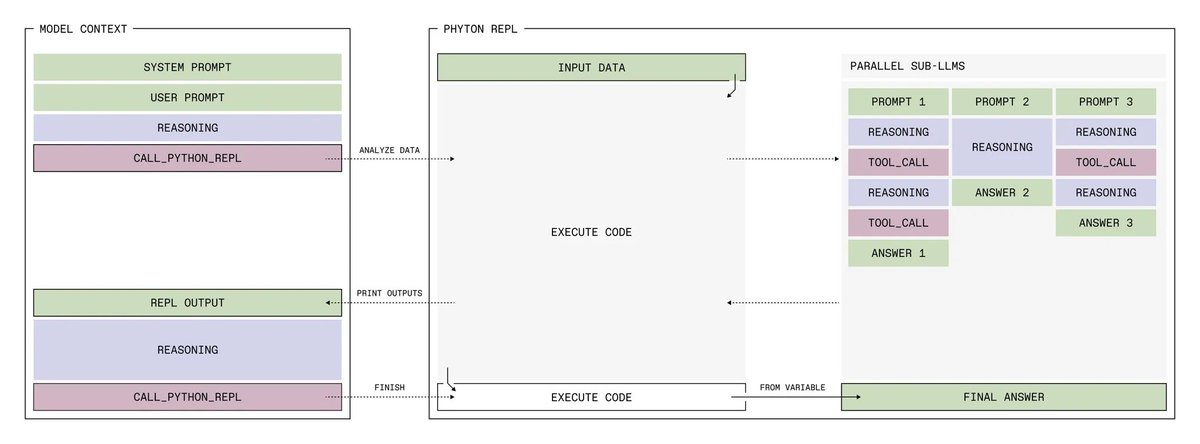
Build your own harness. Turn your data into training tasks. Evaluate your success criteria. Improve your agent. Repeat.
This is what we built Lab for.
Build your own harness. Turn your data into training tasks. Evaluate your success criteria. Improve your agent. Repeat.
This is what we built Lab for.

This same loop is already in prod at leading enterprises.
We help unlock self-improvement flywheels on their data and reward signals from real production tasks.
Lab for Enterprise gives you dedicated capacity, custom environments and deeper support for models at 1T+ scale.
We help unlock self-improvement flywheels on their data and reward signals from real production tasks.
Lab for Enterprise gives you dedicated capacity, custom environments and deeper support for models at 1T+ scale.
Over the next few weeks, we will be sharing more with the community about how Lab unlocks powerful self-improvement for real-world systems.
Start training: app.primeintellect.ai/dashboard/home…
Get in touch: primeintellect.ai/contact
Read more: primeintellect.ai/blog/lab-is-op…
Start training: app.primeintellect.ai/dashboard/home…
Get in touch: primeintellect.ai/contact
Read more: primeintellect.ai/blog/lab-is-op…
• • •
Missing some Tweet in this thread? You can try to
force a refresh