Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
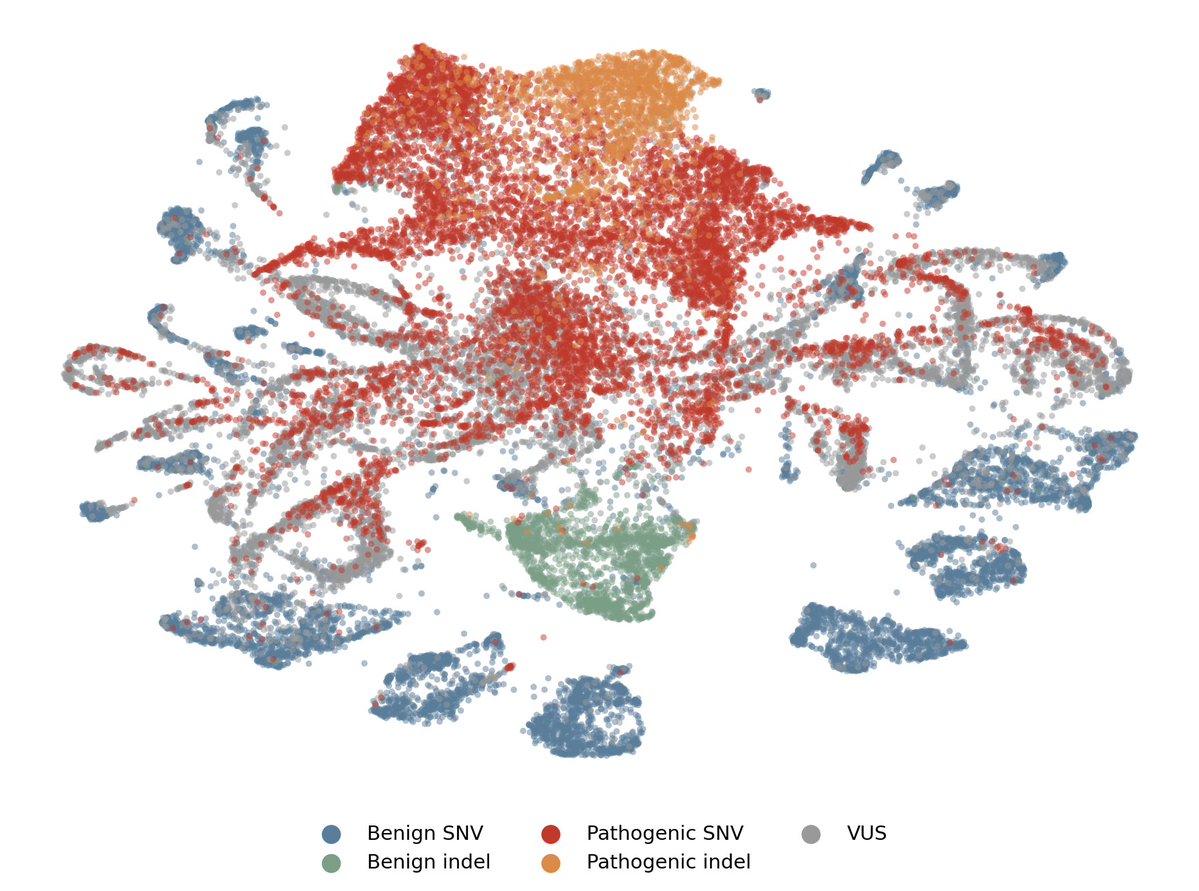
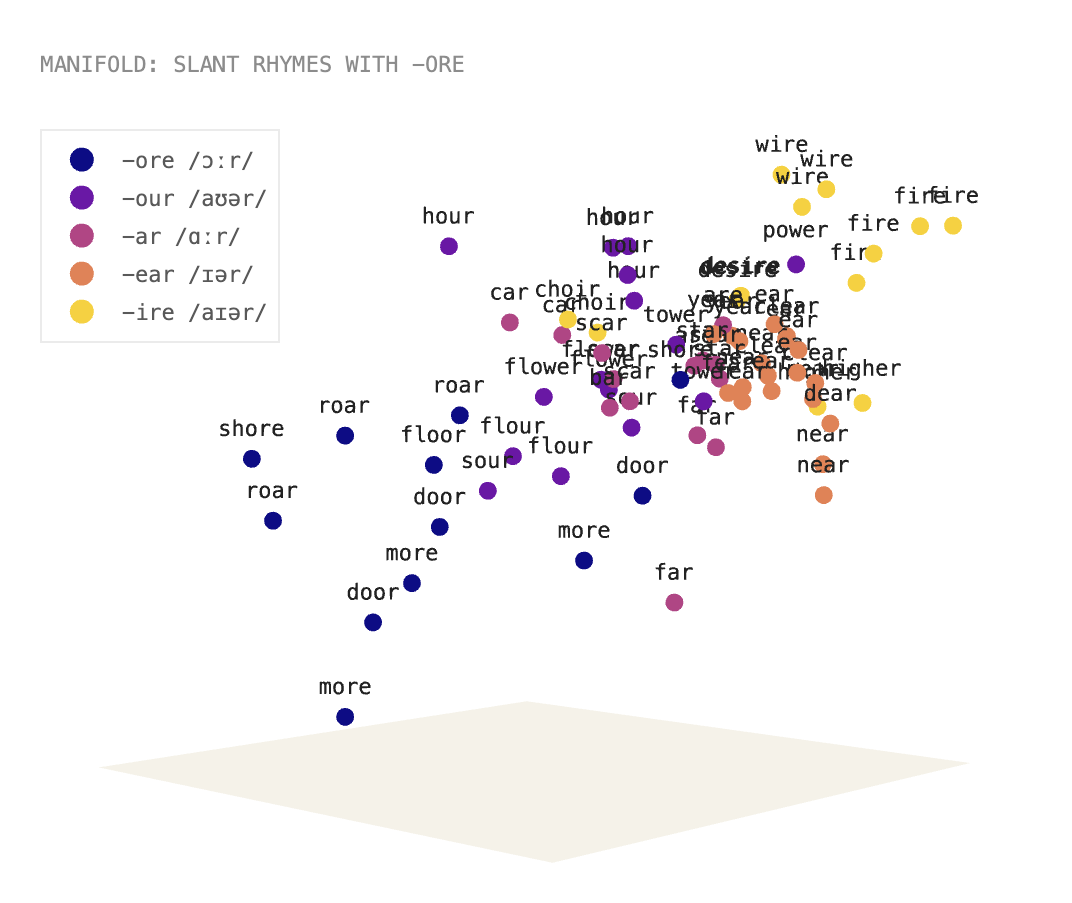
Just as the real world is highly structured, neural networks are full of rich geometric structure: time, space, numbers, color, the tree of life, new biomarkers, and more are represented along curved paths and surfaces.
This is true across models, modalities, and domains! (2/8)
This is true across models, modalities, and domains! (2/8)
New methods to understand this “neural geometry” are a crucial frontier in understanding, improving, and controlling models. (3/8)
Why? Just as you couldn’t understand a computer without understanding its data structures, you can't understand a neural network without knowing how its representations are shaped.
Representations underlie internal algorithms and model behavior! (4/8)
Representations underlie internal algorithms and model behavior! (4/8)
A simple example: days of the week, which lie on a circular path in models’ activations.
Steering linearly from Monday to Friday gets you incoherent outputs in between. Steering along the circular manifold means you cleanly shift from Mon → Tues → Wed → Thurs → Fri. (5/8)
Steering linearly from Monday to Friday gets you incoherent outputs in between. Steering along the circular manifold means you cleanly shift from Mon → Tues → Wed → Thurs → Fri. (5/8)
Another example: an image-action world model of the “mountain car”.
Position turns out to be represented by a spaghetti-like path in activations. While steering along the manifold moves the car neatly (left), linear steering smears and teleports it incoherently (middle). (6/8)
Position turns out to be represented by a spaghetti-like path in activations. While steering along the manifold moves the car neatly (left), linear steering smears and teleports it incoherently (middle). (6/8)
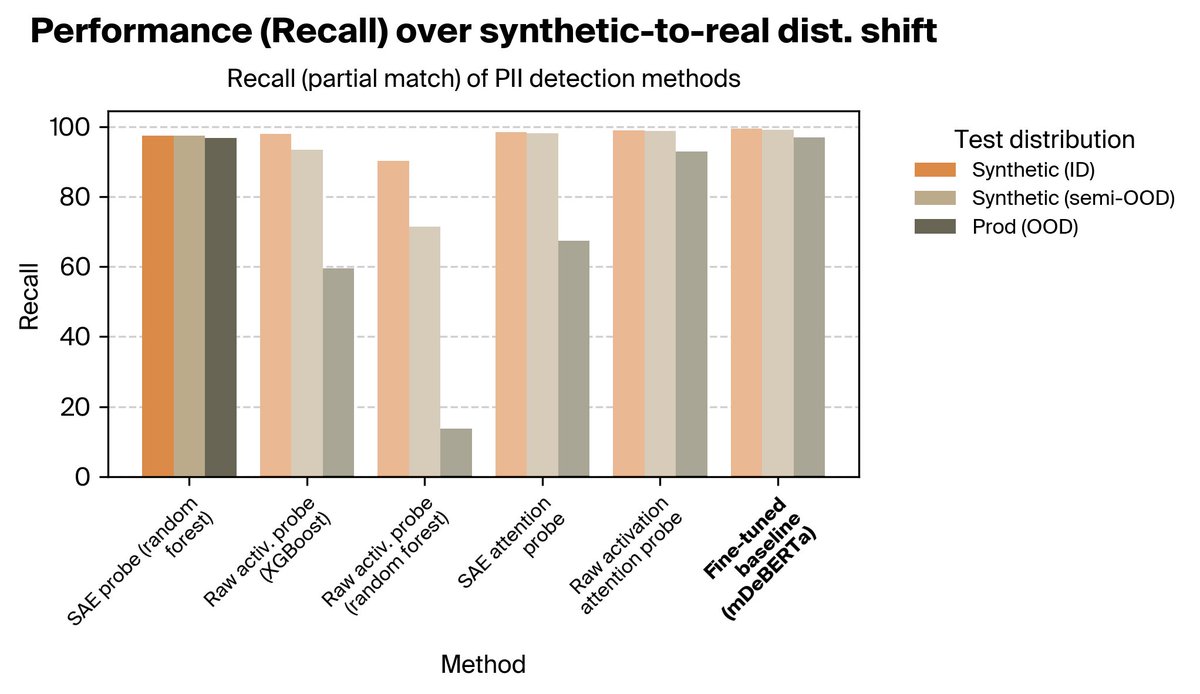
In contrast to this view, popular interpretability methods like SAEs tend to “shatter” concept manifolds into many small and apparently-unrelated pieces, obscuring the overarching semantic structure that becomes clear when a manifold is viewed as a whole. (7/8) 

Read the first 2 posts in the series:
Forthcoming posts will go into more detail on:
- an example mechanism that operates on manifolds
- unsupervised discovery of manifolds + the connection to SAE features
- in-context geometrygoodfire.ai/research/the-w…
Forthcoming posts will go into more detail on:
- an example mechanism that operates on manifolds
- unsupervised discovery of manifolds + the connection to SAE features
- in-context geometrygoodfire.ai/research/the-w…
• • •
Missing some Tweet in this thread? You can try to
force a refresh