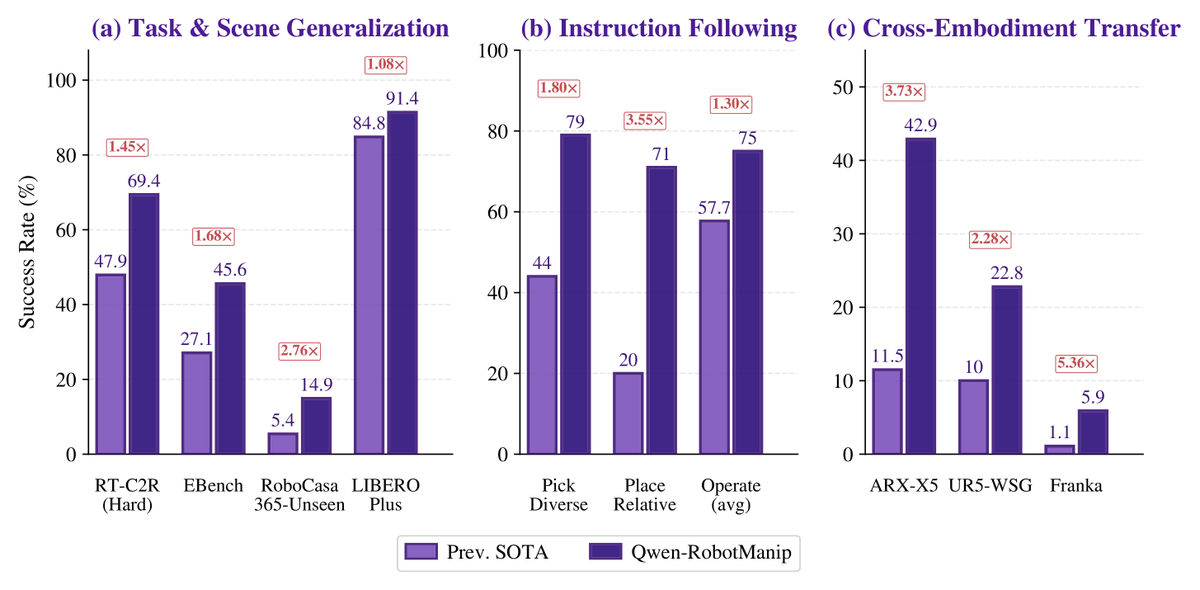
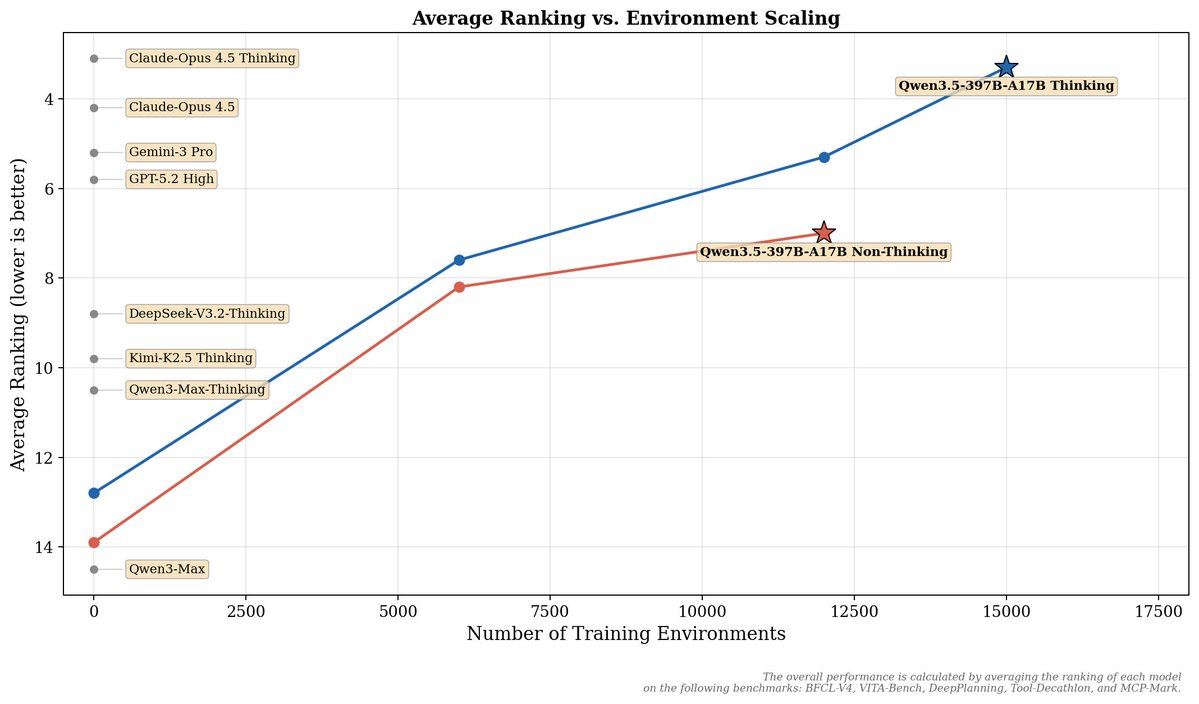
🚀🚀Qwen3.7 Preview lands on Arena !
Here come Qwen3.7-Max-Preview & Qwen3.7-Plus-Preview. Alibaba now #6 lab in Text, #5 in Vision.⚡️⚡️
Can't wait to release Qwen3.7 series models!Stay tuned! @arena
Here come Qwen3.7-Max-Preview & Qwen3.7-Plus-Preview. Alibaba now #6 lab in Text, #5 in Vision.⚡️⚡️
Can't wait to release Qwen3.7 series models!Stay tuned! @arena
https://twitter.com/arena/status/2056400044862111757
• • •
Missing some Tweet in this thread? You can try to
force a refresh