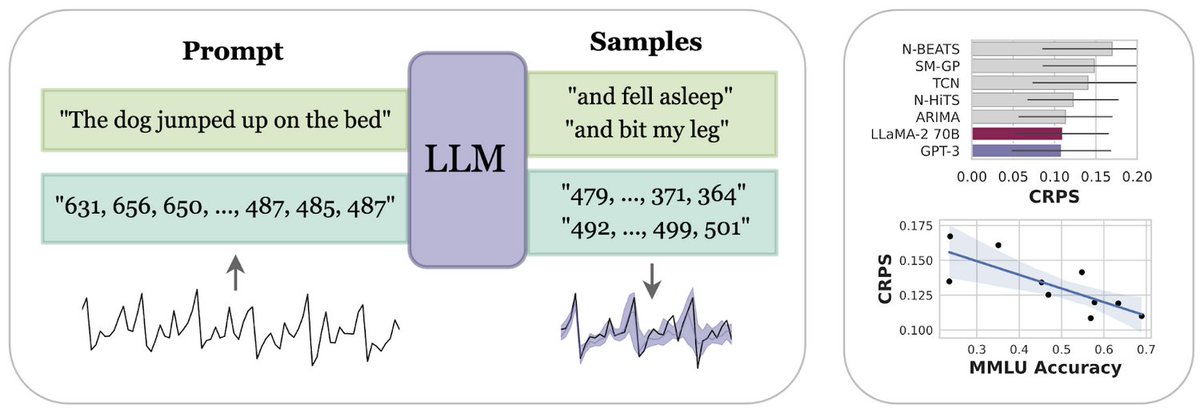
How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay!
w/@mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov 1/8 arxiv.org/abs/2605.26097
w/@mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov 1/8 arxiv.org/abs/2605.26097
We view forgetting as drift in the model's predictions on old data. So the fix is simple: use a KL penalty on past (pretraining) data to keep old outputs fixed while the model fits the new data. 2/8

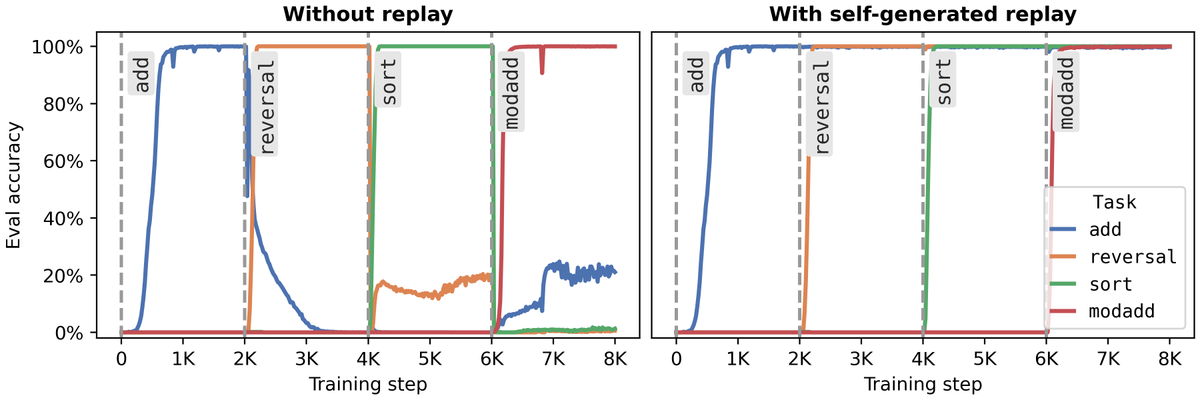
Unfortunately, pretraining data is often unavailable! But since LLMs are generative models, we can use them to directly sample data. In this continual learning experiment with a 2M parameter language model, self-generated replay entirely eliminates forgetting. 3/8
We can even generate replay data from an instruction-tuned LLM. For example, when finetuning Llama-3.2-1B, we can prompt the model with a BOS token (without a chat template) and generate pretraining-like data. With a KL penalty, this data significantly reduces forgetting. 4/8

When does forgetting still happen? When the model has no spare capacity. Small models trained to saturation cannot absorb new information without overwriting old information. 5/8
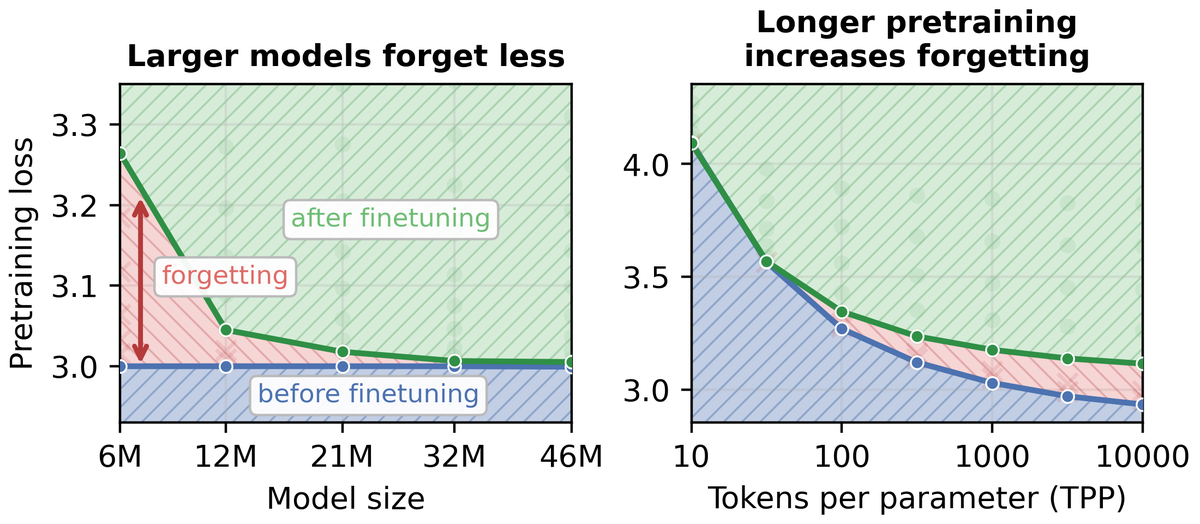
Learning rate matters too. Forgetting can be reduced by using a high pretraining learning rate, making it possible to release pretrained models that are less prone to downstream forgetting. A small finetuning learning rate also mitigates forgetting. 6/8
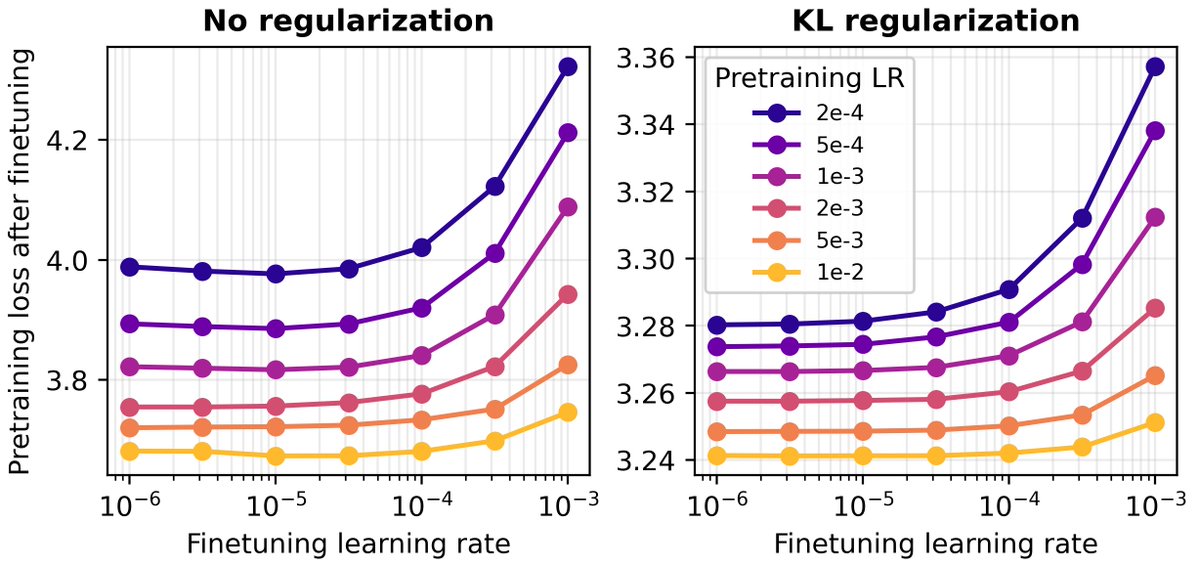
However, a small finetuning learning rate is expensive, increasing the optimizer steps required to reach a target loss. Using replay data in finetuning breaks this tradeoff, enabling the use of a high learning rate while minimizing forgetting! 7/8
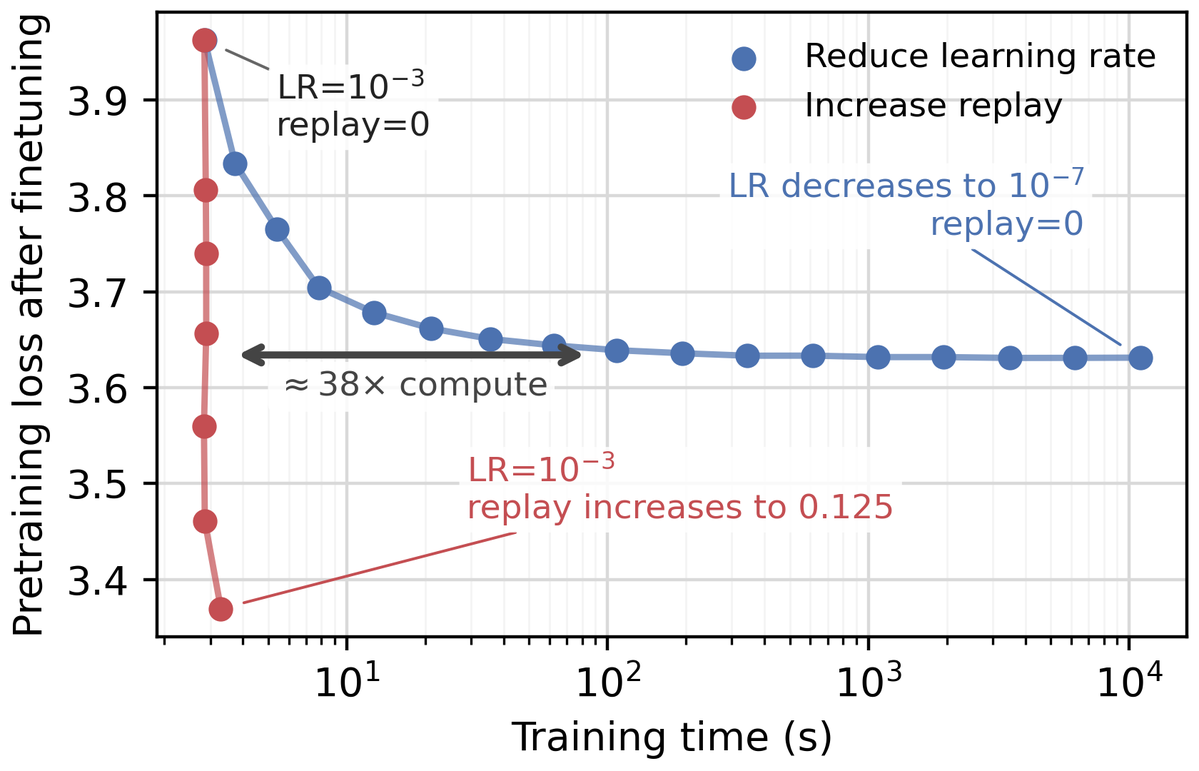
Much more in the paper! As models are increasingly being adapted to new settings, it’s especially crucial to understand forgetting. This was an incredible effort with an amazing team led by @mrtnm. Code is available at: . 8/8github.com/martin-marek/f…
• • •
Missing some Tweet in this thread? You can try to
force a refresh