⚖️¿Falso positivo o falso negativo? El arte de tomar decisiones bajo incertidumbre
Cuando ponemos a prueba una hipótesis no solo buscamos respuestas, también gestionamos el riesgo. Eliminar el error es imposible, el objetivo es intentar comprenderlo, cuantificarlo y equilibrarlo.
Cuando ponemos a prueba una hipótesis no solo buscamos respuestas, también gestionamos el riesgo. Eliminar el error es imposible, el objetivo es intentar comprenderlo, cuantificarlo y equilibrarlo.

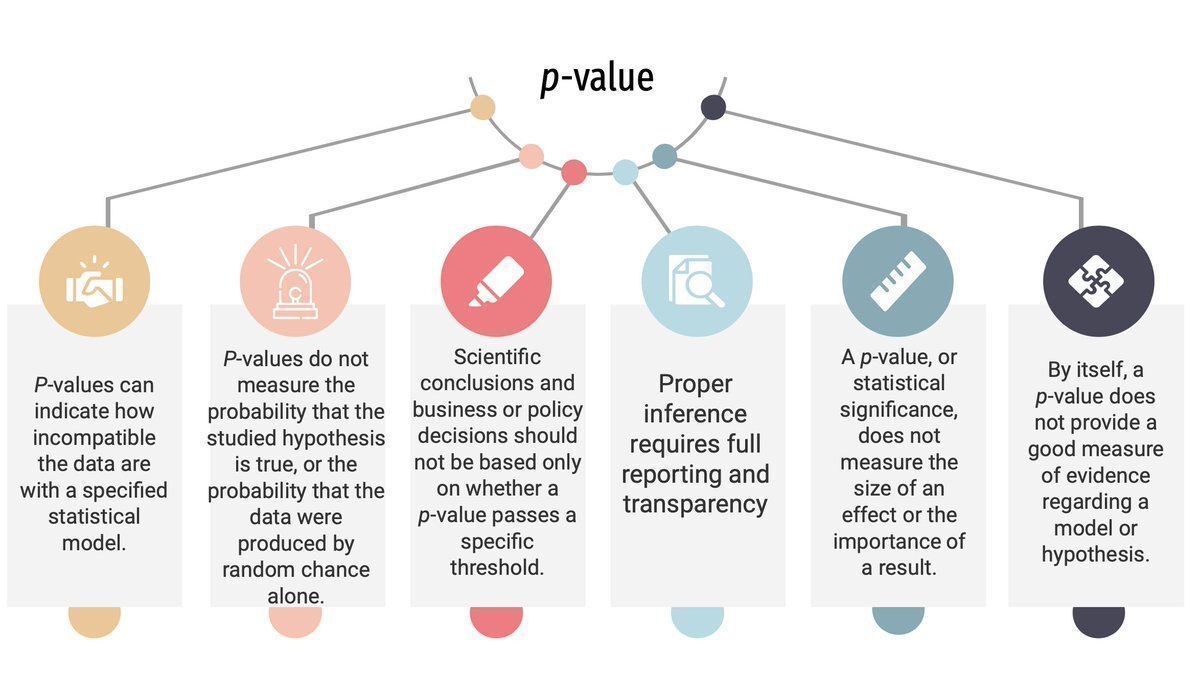
Entender la diferencia entre el Error Tipo I y II es fundamental para cualquier profesional que tome decisiones basadas en datos.
👉FAQs
¿Cómo se interpretan estos errores?
¿Cómo minimizar ambos errores a la vez?
¿Cómo decidir qué error priorizar?
¿Qué error es peor?
👉FAQs
¿Cómo se interpretan estos errores?
¿Cómo minimizar ambos errores a la vez?
¿Cómo decidir qué error priorizar?
¿Qué error es peor?

💥 El "trade-off" inevitable
Para un N fijo, reducir un tipo de error suele aumentar el otro. La clave es evaluar las consecuencias:
Para un N fijo, reducir un tipo de error suele aumentar el otro. La clave es evaluar las consecuencias:

Y tú, ¿Cómo gestionas tú este equilibrio en tus proyectos de análisis de datos? Te leo en los comentarios 👇
#stats #DataScience #Estadistica #cienciadedatos #AnalisisDeDatos #DataAnalytics #analytics #research
#stats #DataScience #Estadistica #cienciadedatos #AnalisisDeDatos #DataAnalytics #analytics #research

• • •
Missing some Tweet in this thread? You can try to
force a refresh