
📊 PhD. Bioestadística | stats + Data Science + Machine Learning | Directora académica y Docente |#RStats y #Python | Stats is the grammar of science
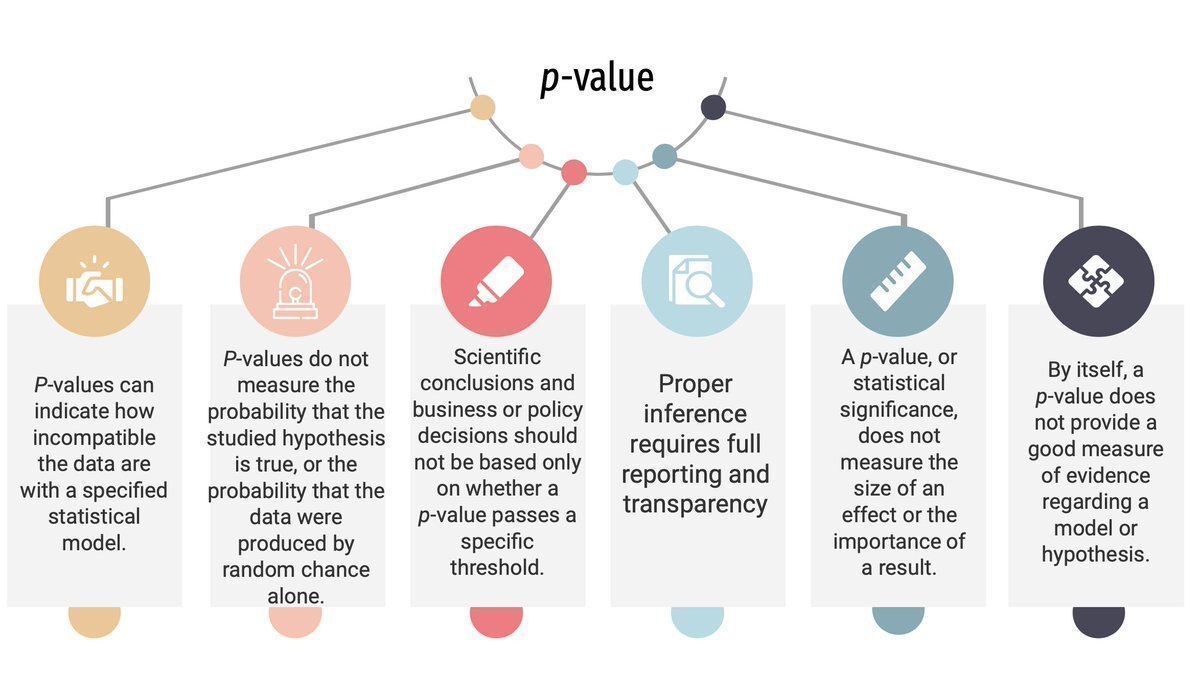 Cuando un investigador dice que un resultado es "estadísticamente significativo" (o discernible, habitualmente p < 0.05), no está certificando la verdad, sino señalando que, si el mundo fuera como asume nuestra H0 (y sus supuestos), lo que acabamos de observar sería muy inusual.
Cuando un investigador dice que un resultado es "estadísticamente significativo" (o discernible, habitualmente p < 0.05), no está certificando la verdad, sino señalando que, si el mundo fuera como asume nuestra H0 (y sus supuestos), lo que acabamos de observar sería muy inusual. 
 Un test de hipótesis no es un ejercicio de búsqueda de la verdad, sino una estrategia para gestionar el riesgo bajo incertidumbre.
Un test de hipótesis no es un ejercicio de búsqueda de la verdad, sino una estrategia para gestionar el riesgo bajo incertidumbre.
 No fuerces tus datos en modelos inadecuados, ni te pierdas en el laberinto de las siglas (LM, GLM, GAMM, GLMM). Utiliza esta guía rápida para elegir el modelo adecuado.
No fuerces tus datos en modelos inadecuados, ni te pierdas en el laberinto de las siglas (LM, GLM, GAMM, GLMM). Utiliza esta guía rápida para elegir el modelo adecuado. A menudo, los investigadores evitan el cálculo de potencia con la excusa de que "no conocen el tamaño del efecto". Mi consejo: 𝐧𝐨 𝐩𝐥𝐚𝐧𝐢𝐟𝐢𝐪𝐮𝐞𝐬 𝐩𝐚𝐫𝐚 𝐥𝐨 𝐪𝐮𝐞 𝐞𝐬𝐩𝐞𝐫𝐚𝐬, 𝐩𝐥𝐚𝐧𝐢𝐟𝐢𝐜𝐚 𝐩𝐚𝐫𝐚 𝐥𝐨 𝐪𝐮𝐞 𝐧𝐨 𝐪𝐮𝐢𝐞𝐫𝐞𝐬 𝐩𝐚𝐬𝐚𝐫 𝐩𝐨𝐫 𝐚𝐥𝐭𝐨.
A menudo, los investigadores evitan el cálculo de potencia con la excusa de que "no conocen el tamaño del efecto". Mi consejo: 𝐧𝐨 𝐩𝐥𝐚𝐧𝐢𝐟𝐢𝐪𝐮𝐞𝐬 𝐩𝐚𝐫𝐚 𝐥𝐨 𝐪𝐮𝐞 𝐞𝐬𝐩𝐞𝐫𝐚𝐬, 𝐩𝐥𝐚𝐧𝐢𝐟𝐢𝐜𝐚 𝐩𝐚𝐫𝐚 𝐥𝐨 𝐪𝐮𝐞 𝐧𝐨 𝐪𝐮𝐢𝐞𝐫𝐞𝐬 𝐩𝐚𝐬𝐚𝐫 𝐩𝐨𝐫 𝐚𝐥𝐭𝐨. 
 En 2011, el experimento OPERA anunció un hallazgo que parecía revolucionario: los neutrinos habrían viajado más rápido que la luz. Y con un nivel de 6 sigma, algo extraordinariamente exigente en física.
En 2011, el experimento OPERA anunció un hallazgo que parecía revolucionario: los neutrinos habrían viajado más rápido que la luz. Y con un nivel de 6 sigma, algo extraordinariamente exigente en física.
 Muchos celebran un p<0,05 como si fuese la meta final, y no se preguntan:
Muchos celebran un p<0,05 como si fuese la meta final, y no se preguntan:
 La elección de α es una decisión de diseño estadístico: α es un criterio que controla la probabilidad de cometer un error de tipo I bajo H₀. Fija el umbral a partir del cual consideramos un resultado "suficientemente inusual" bajo H₀ (y los supuestos del modelo).
La elección de α es una decisión de diseño estadístico: α es un criterio que controla la probabilidad de cometer un error de tipo I bajo H₀. Fija el umbral a partir del cual consideramos un resultado "suficientemente inusual" bajo H₀ (y los supuestos del modelo).
 ¿Qué puedes hacer con él?
¿Qué puedes hacer con él? ¿Qué paso de este flujo crees que se pasa más por alto en las publicaciones actuales? Te leo en los comentarios. 👇
¿Qué paso de este flujo crees que se pasa más por alto en las publicaciones actuales? Te leo en los comentarios. 👇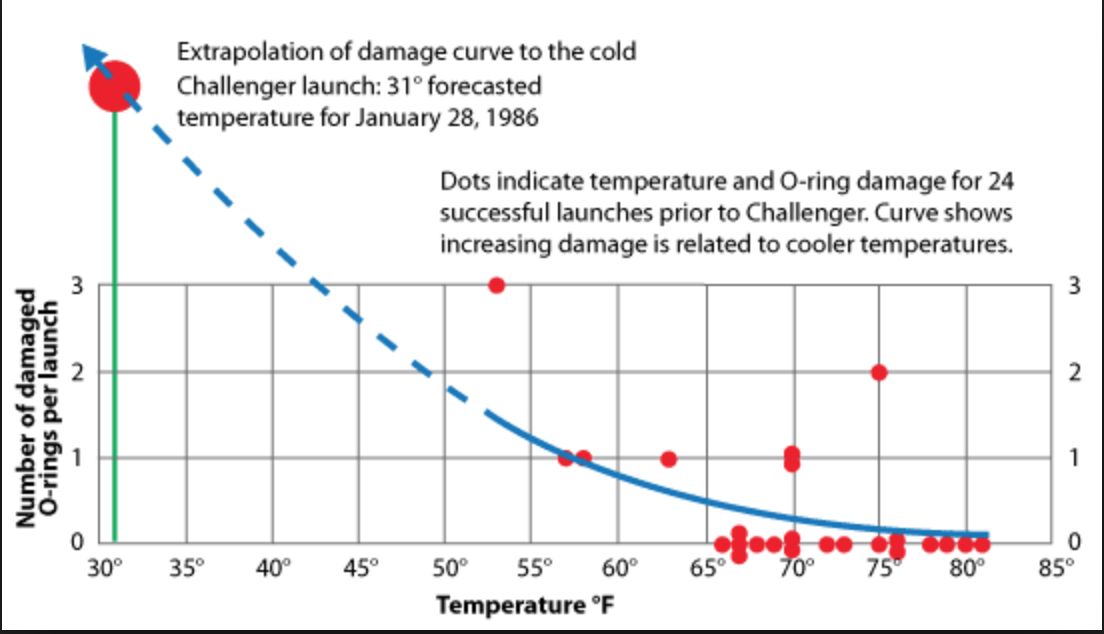 El 28 de enero de 1986, el transbordador Challenger se desintegró a los 73 segundos de su lanzamiento. No fue solo una falla de ingeniería física sino un trágico error en el análisis y la visualización de datos.
El 28 de enero de 1986, el transbordador Challenger se desintegró a los 73 segundos de su lanzamiento. No fue solo una falla de ingeniería física sino un trágico error en el análisis y la visualización de datos.
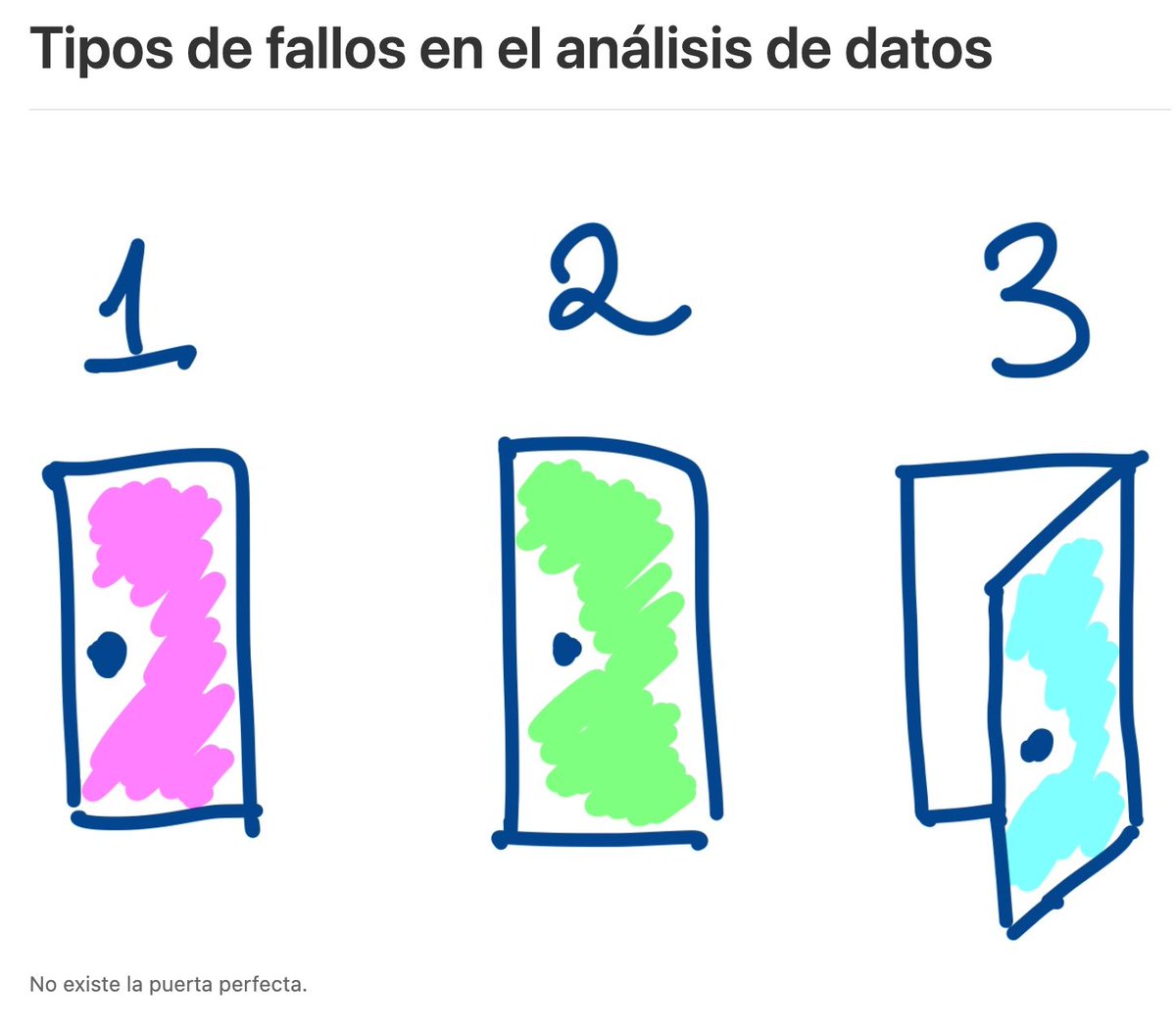 El fallo ocurre cuando hay lagunas lógicas en tu estudio que obligan al lector a preguntarse "¿Por qué no hicieron X?"
El fallo ocurre cuando hay lagunas lógicas en tu estudio que obligan al lector a preguntarse "¿Por qué no hicieron X?"
 Advertencia: 𝗰𝗼𝗿𝗿𝗲𝗴𝗶𝗿 𝗲𝗹 𝗱𝗲𝘀𝗯𝗮𝗹𝗮𝗻𝗰𝗲 de clases 𝗱𝗲 𝗳𝗼𝗿𝗺𝗮 𝗮𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝘀𝘂𝗲𝗹𝗲 𝘀𝗲𝗿 𝘂𝗻 𝗲𝗿𝗿𝗼𝗿
Advertencia: 𝗰𝗼𝗿𝗿𝗲𝗴𝗶𝗿 𝗲𝗹 𝗱𝗲𝘀𝗯𝗮𝗹𝗮𝗻𝗰𝗲 de clases 𝗱𝗲 𝗳𝗼𝗿𝗺𝗮 𝗮𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝘀𝘂𝗲𝗹𝗲 𝘀𝗲𝗿 𝘂𝗻 𝗲𝗿𝗿𝗼𝗿
 La IA es, fundamentalmente, estadística.
La IA es, fundamentalmente, estadística.
 La clave es entender:
La clave es entender: Fuera de ese contexto, empieza a fallar.
Fuera de ese contexto, empieza a fallar. 1️⃣ Lee la validación como evidencia parcial, no como garantía global. Antes de asumir que "funciona", pregúntate si tu contexto (pacientes, procesos, datos) se parece al de esa validación. Si no, estarías extrapolando, no aplicando.
1️⃣ Lee la validación como evidencia parcial, no como garantía global. Antes de asumir que "funciona", pregúntate si tu contexto (pacientes, procesos, datos) se parece al de esa validación. Si no, estarías extrapolando, no aplicando.
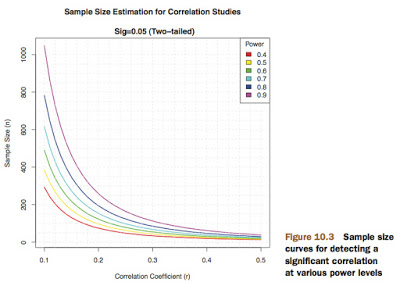 1️⃣ Sobre la elección de la potencia (¿80%, 90%, 70%?)
1️⃣ Sobre la elección de la potencia (¿80%, 90%, 70%?)
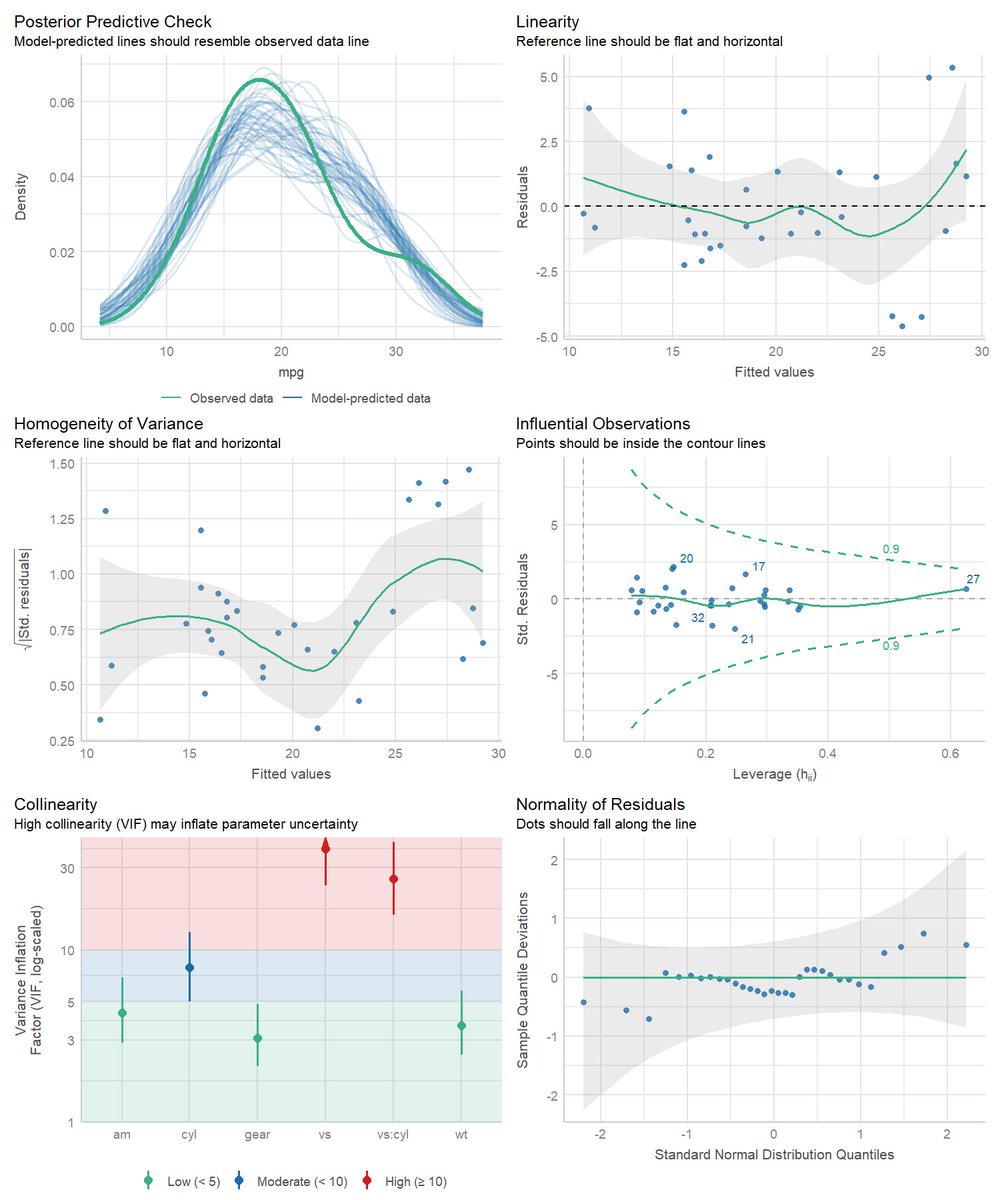 ¿Cómo evaluar un modelo?
¿Cómo evaluar un modelo? 1️⃣ "The Art of Statistics: Learning from Data" David Spiegelhalter
1️⃣ "The Art of Statistics: Learning from Data" David Spiegelhalter