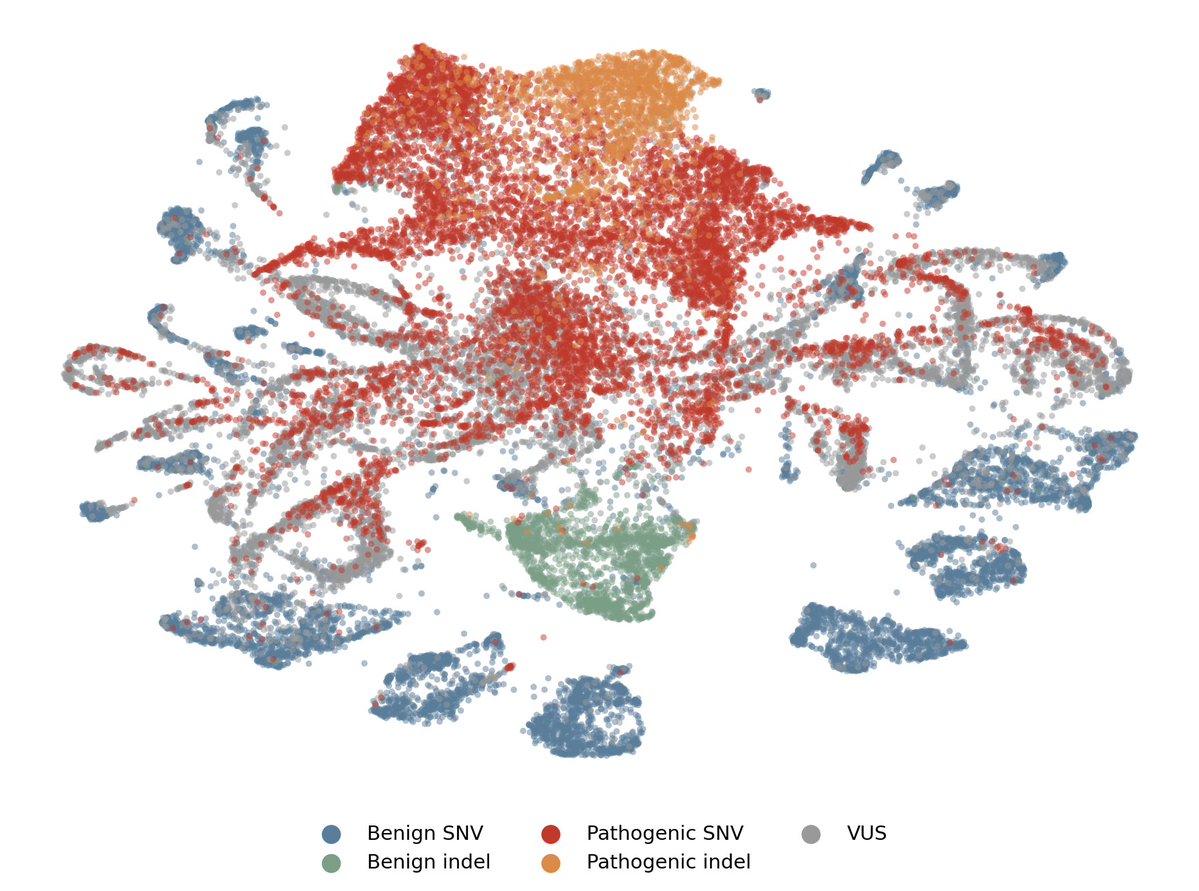
We removed an LM's ability to speak German by fine-tuning on only 4 German tokens.
As part of a 1-day hackathon with our product Silico, we removed a 67M-parameter language model's ability to predict German text, by tuning only a scalar factor on one subcomponent of the weights. (1/6)
As part of a 1-day hackathon with our product Silico, we removed a 67M-parameter language model's ability to predict German text, by tuning only a scalar factor on one subcomponent of the weights. (1/6)

This was an early exploration in fine-tuning with *parameter decomposition* (see quote), our method which divides a model's weight matrices into interpretable, sparsely-activating components.
We picked German as it seemed to be the model's strongest non-English language. (2/6)
We picked German as it seemed to be the model's strongest non-English language. (2/6)
https://twitter.com/3079387847/status/2051717264286609516
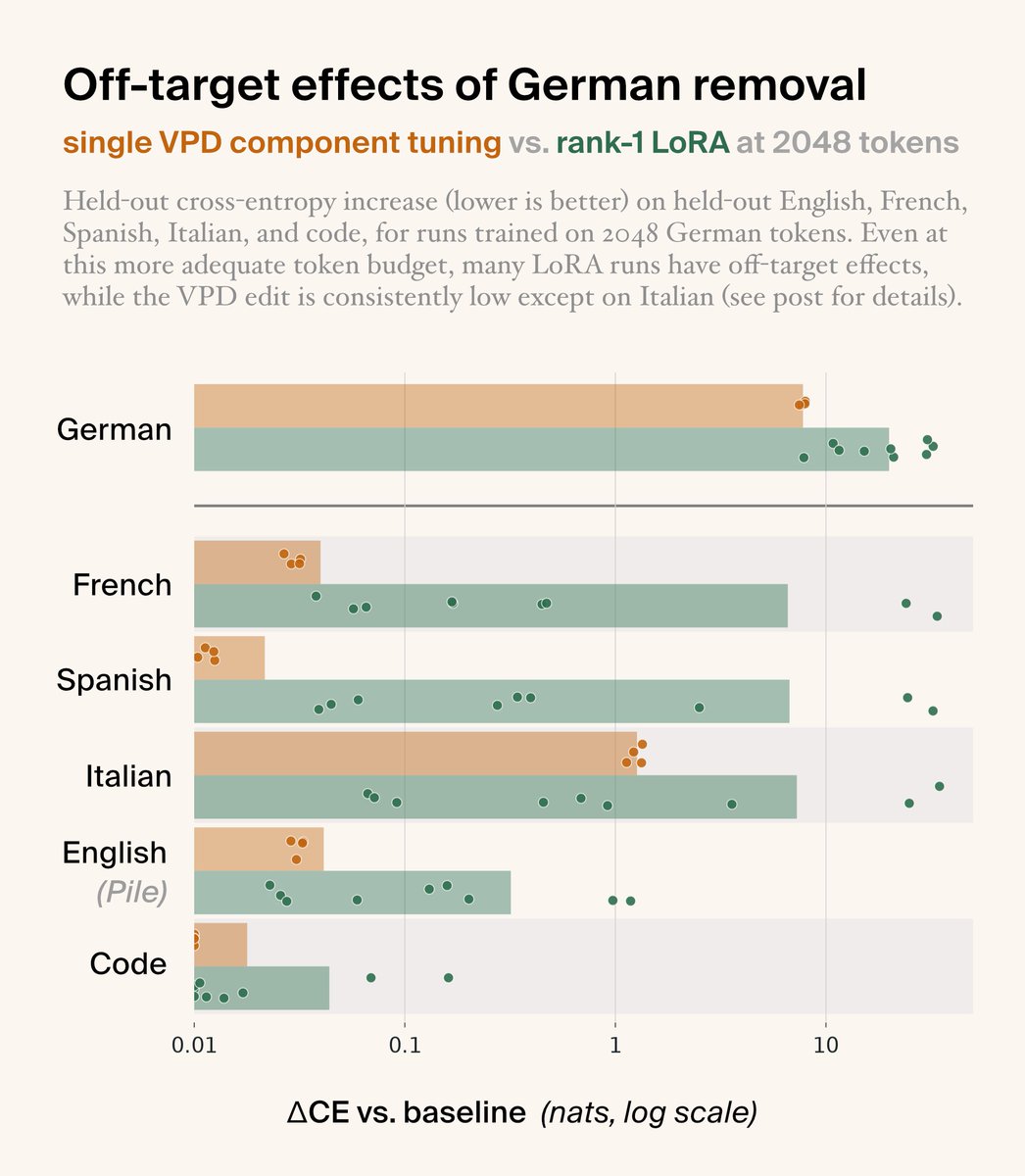
We benchmarked vs LoRA fine-tuning. Our edit matched its German removal with far fewer tokens.
Strikingly, it also left other languages almost untouched.
The LoRAs often wrecked French, Spanish, Italian, and sometimes English, while our edit mostly left them alone. (3/6)
Strikingly, it also left other languages almost untouched.
The LoRAs often wrecked French, Spanish, Italian, and sometimes English, while our edit mostly left them alone. (3/6)
In a sense this is cheating: we're indirectly exploiting the tokens from when we did the parameter decomposition and interpreted the resulting subcomponents.
But if our decomposition is good, that cost can be amortized over arbitrarily many tasks & component edits. (4/6)
But if our decomposition is good, that cost can be amortized over arbitrarily many tasks & component edits. (4/6)
Plus, that interpretability lets us notice and fix problems.
E.g.: initially we tuned the top 16 German-related components, but their labels showed most were about foreign languages in general.
So we narrowed to the single component for German alone, improving precision. (5/6)
E.g.: initially we tuned the top 16 German-related components, but their labels showed most were about foreign languages in general.
So we narrowed to the single component for German alone, improving precision. (5/6)
This is an early demo of how parameter decomposition could enable targeted, predictable model editing.
Details on this experiment: lesswrong.com/posts/ieoWstub…
If you want to run experiments on your model too, learn more and request access to Silico: goodfire.ai/silico
Details on this experiment: lesswrong.com/posts/ieoWstub…
If you want to run experiments on your model too, learn more and request access to Silico: goodfire.ai/silico
Correction: a plotting error caused the bars in the plot of off-target effects to display at 0.01 nats above the true means. The corrected plot is below:

• • •
Missing some Tweet in this thread? You can try to
force a refresh