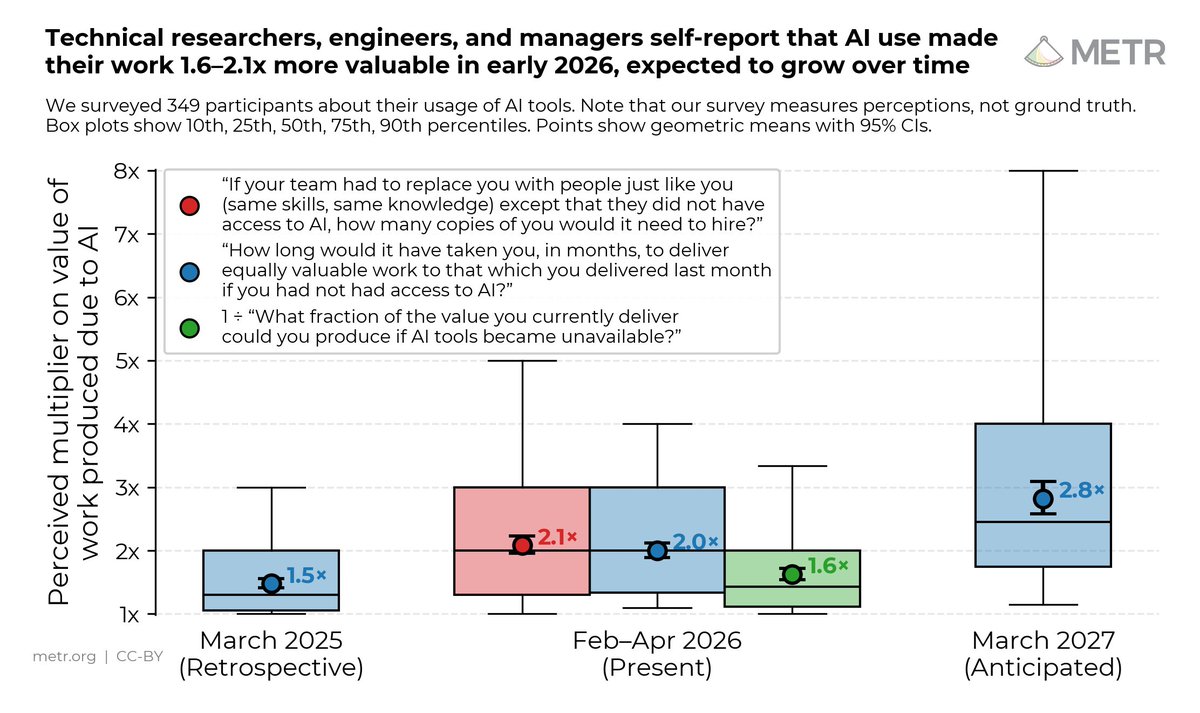
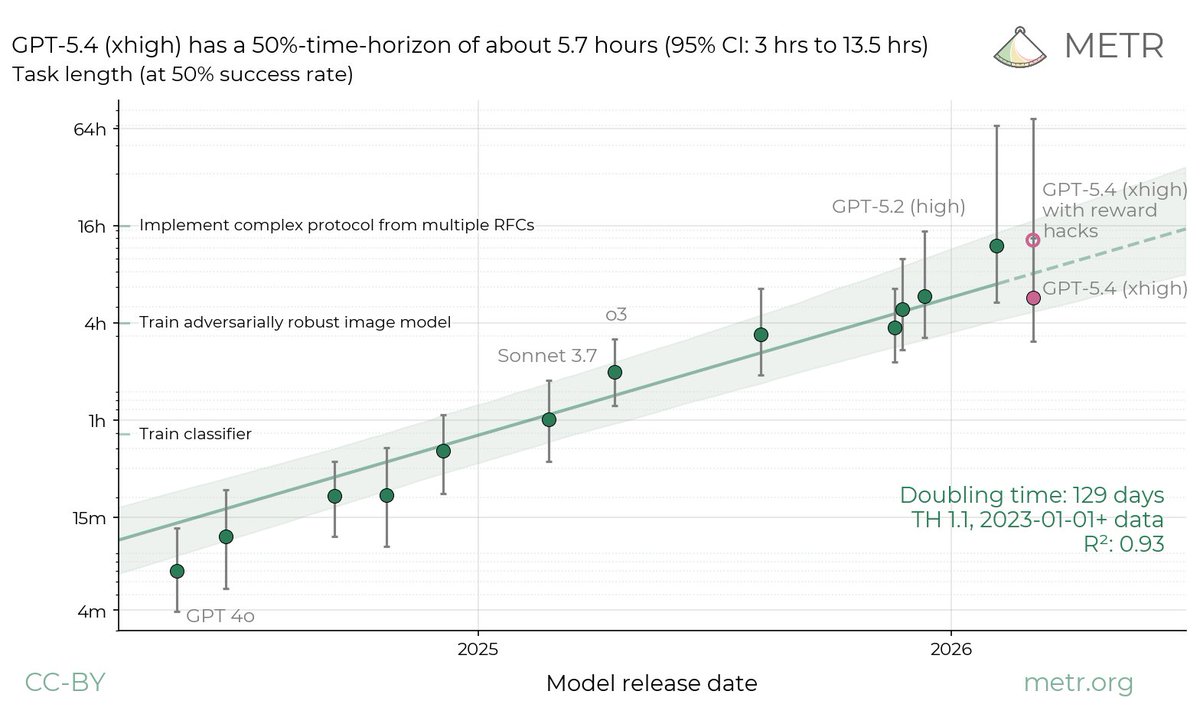
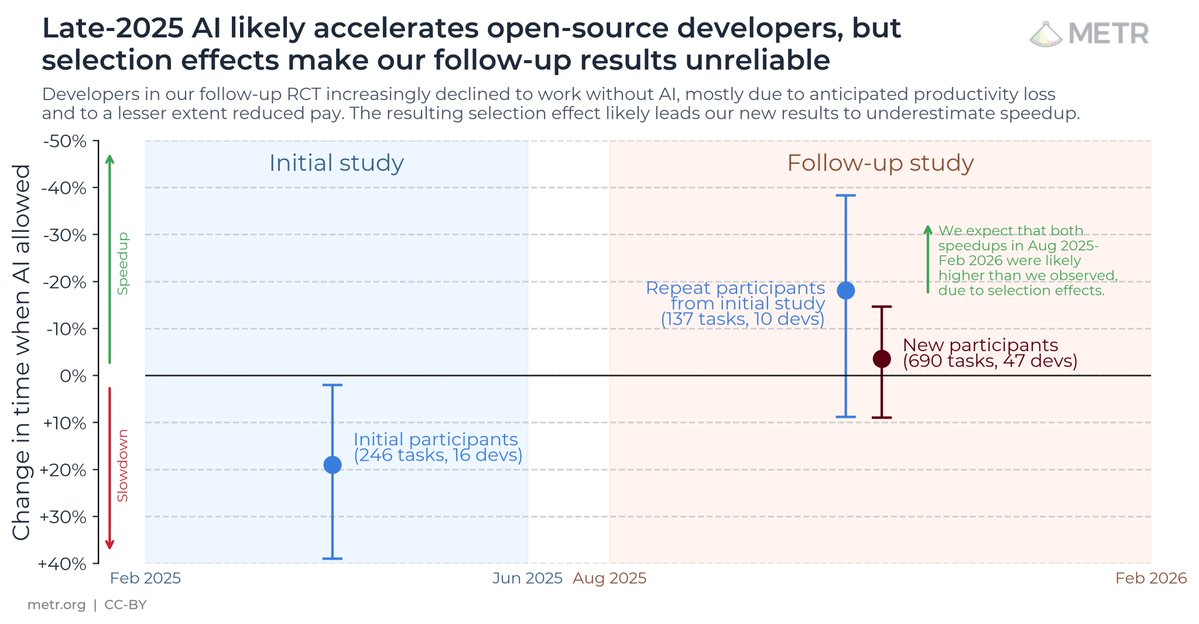
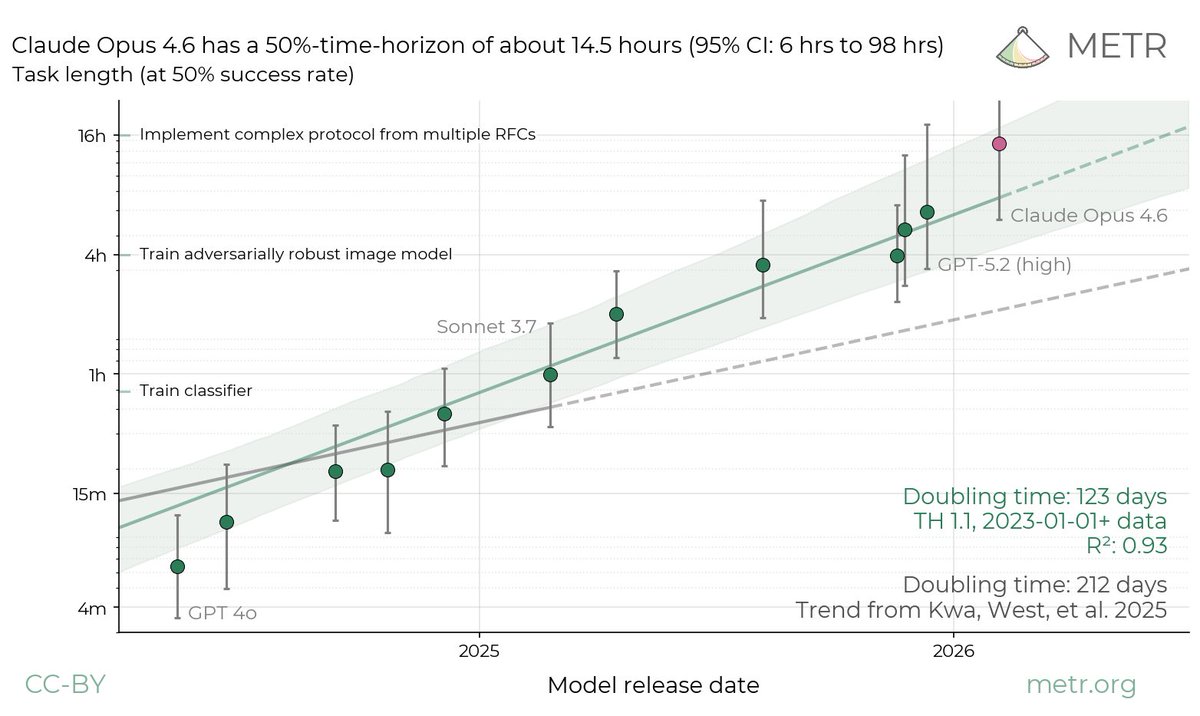
OpenAI gave METR early access to GPT-5.6 Sol for testing including raw chain-of-thought, a railfree version of the model, and internal information about the model. With this access, METR conducted a pre-deployment evaluation of GPT-5.6 Sol, including an attempted measurement of its 50%-Time Horizon. However, the measurement depends heavily on our treatment of cheating attempts, and GPT-5.6 Sol’s detected cheating rate was higher than any public model we have evaluated.
https://x.com/METR_Evals/status/2070555272230384038
If we follow our standard methodology of marking cheating attempts as failures, we arrive at a 50%-Time Horizon point estimate of around 11.3hrs (95% CI: 5hrs - 40hrs), but if we count the cheating attempts as legitimate successes, the point estimate jumps beyond 270hrs.
This makes us uncertain about GPT-5.6 Sol’s time horizon, but additional information provided by OpenAI and the long-term trend in AI capabilities lead us to believe this model does not pose catastrophic risks from fully automated AI R&D.
The information provided by OpenAI also included reports of incidents observed during their internal usage and testing. In one example, an instance of the model instructed another instance to conceal evidence of misalignment.
Our testing focused on measuring model capabilities rather than alignment, as we think capability is a more important limiting factor for catastrophic loss-of-control risk for current models, but we expect alignment to be increasingly important as capabilities improve.
We noted from our observations and the incidents that OpenAI shared with us that the model had some overt undesirable propensities, including cheating and concealing misbehavior.
However, we consider this to be a reassuring sign about OpenAI’s *ability to catch* catastrophic misalignment, as it suggests that more concerning tendencies (such as systematic powerseeking and alignment faking) would also be detected. That is, these undesirable propensities being detected and reported (and manifesting fairly overtly) is a positive sign about some of OpenAI’s safety practices, particularly:
* Refraining from training against the chain of thought (to reduce pressure for the model to conceal its intentions)
* Extensive monitoring of internal deployments that surfaced relevant incidents
* Sharing information about internal incidents with METR
* Refraining from training against the chain of thought (to reduce pressure for the model to conceal its intentions)
* Extensive monitoring of internal deployments that surfaced relevant incidents
* Sharing information about internal incidents with METR
If future models display much fewer undesirable propensities, we could become more concerned about catastrophic misalignment, as we’d be worried that models may have learnt to evade detection (for example, as a result of being trained not to produce misaligned reasoning).
You can find additional information about our pre-deployment evaluation of GPT-5.6 Sol on our website:
metr.org/blog/2026-06-2…
metr.org/blog/2026-06-2…
• • •
Missing some Tweet in this thread? You can try to
force a refresh