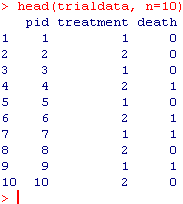
@yudapearl @robertwplatt Suppose we are studying patients with severe aortic stenosis that are planning to undergo transcatheter aortic valve replacement.
@yudapearl @robertwplatt Suppose there are two different "approaches" that may be used for TAVR. We wish to know if one of them is better than the other.
Suppose I want to know if a particular medication is effective in preventing hospitalization of newly diagnosed COVID patients.
@ztownsend@rabois@MaartenvSmeden Suppose that there are 100,000 new cases in a given week, and by some miracle I have a rich data source that includes a) their date of positive test, b) whether they were hospitalized in the next 30 days after the test, and c) whether they received the medication for all 100K.
Feb 10, 2023 • 8 tweets • 2 min read
Time for my annual love letter to @CritCareReviews and why you should consider going if combination of (location, dates, times, personal circumstances, and other considerations) permit
1. The format is like no other conference I've attended. Instead of 12 concurrent sessions , with a bunch of 10 minute talks that allow 1 question at the end, there's one main stage.
Jul 14, 2022 • 13 tweets • 5 min read
Tongue-in-cheek post from @mikejohansenmd, but this is a pedantic point that increasingly bothers me when I see it: researchers wrongly identifying studies as "case-control" studies that are nothing of the sort.
@mikejohansenmd (It doesn't invalidate the work, really, it's just odd to see how many researchers don't seem to understand what a "case-control study" actually is)
Inspired by this & some other recent discussions of the win ratio approach, here comes a little tutorial on the "win ratio" approach to analysis of RCT data.
In our typical RCT's, we expect investigators to choose one variable as the "primary endpoint" to test whether the treatment has a benefit.
Jan 26, 2022 • 16 tweets • 3 min read
Noninferiority trials: a musing thread that I may regret.
NI trials are fickle & unsatisfying. Sometimes there's a legitimately good reason to do them (discussed below); the stats are maddening (also discussed below).
Suppose we have a particular group of patients that need to undergo a certain procedure. The procedure has a theoretical, biologically plausible risk of causing a particular complication; we generally give patients some prophylactic therapy against that complication.
Nov 18, 2021 • 5 tweets • 5 min read
@sim0ngates@chrisdc77@hafetzj@eturnermd1 Yeah, I thought about (and should have said something about) the distinction between industry funded vs academic sponsored trials. The exact process is a bit different but the challenges would be similar-ish. Agree that industry/regulatory bodies would have to be on board.
@sim0ngates@chrisdc77@hafetzj@eturnermd1 Of course the easiest way to make this happen would be for the major regulators to make it happen. But as Chris (I think?) said a little while ago, this was evidently part of the original discussion for clinical trials dot gov but they didn’t go all the way to RRs.
Nov 15, 2021 • 31 tweets • 5 min read
Thread on relationships between researchers and statistical consultants. Prompted by a few recent tweets, but not only those as this is a recurring and always-relevant conversation.
On the "researcher seeking stats help" side, there is an often-justified feeling that statistical consultants are difficult to work with (even those in good faith) and sometimes downright unhelpful or unpleasant.
Sep 1, 2021 • 7 tweets • 1 min read
Riddle me this, stats/medicine people.
I know about Justify Your Alpha.
Has anyone in *medicine* (or otherwise, but particularly interested in US academic medicine) actually proposed a study where they said they'd use an alpha threshold above 0.05? How was it received? (cont)
(Also, please do me a favor, spare me the arguments about NHST being a flawed paradigm on this particular thread)
Aug 22, 2021 • 20 tweets • 15 min read
@Jabaluck@_MiguelHernan@aecoppock I think (perhaps unsurprisingly) that this shows “different people from different fields see things differently because they work in different contexts” - the scenario you painted here is not really possible with how most *medical* RCTs enroll patients & collect baseline data
@Jabaluck@_MiguelHernan@aecoppock The workflow for most medical RCTs (excepting a few trial designs…which I’ll try to address at the end if I have time) is basically this:
Jul 16, 2021 • 6 tweets • 1 min read
Amusing Friday thoughts: I've been reading Stuart Pocock's 1983 book Clinical Trials: A Practical Approach (do not concern yourself with the reason).
There is a passage on "Statistical Computing" in Chapter 11 of the book which one might have expected would age poorly, but is in fact remarkable for how well several of the statements have held up.
Mar 11, 2021 • 45 tweets • 7 min read
Fun thread using some simulations modeled on the ARREST trial design (presented @CritCareReviews a few months ago) to talk through some potential features you might see when we talk about “adaptive” trials
DISCLAIMER: this is not just a “frequentist” versus “Bayesian” thread. Yes, this trial used a Bayesian statistical approach, but there are frequentist options for interim analyses & adaptive features, and that’s a longer debate for another day.
Jan 25, 2021 • 47 tweets • 7 min read
Here is a little intro thread on how to do simulations of randomized controlled trials.
This thread will take awhile to get all the way through & posted, so please be patient. Maybe wait a few minutes and then come back to it.
This can be quite useful if you’re trying to understand the operating characteristics (power, type I error probability, potential biases introduced by early stopping rules) of a particular trial design.
Oct 30, 2020 • 18 tweets • 3 min read
Here’s a brief follow-up thread answering a sidebar question to the last 2 weeks’ threads on interim analyses in RCT’s and stopping when an efficacy threshold is crossed
The “TL;DR” summary of the previous lesson(s): yes, an RCT that stops early based on an efficacy threshold will tend to overestimate the treatment effect a bit, but that doesn’t actually mean the “trial is more likely to be a false positive result”
Oct 16, 2020 • 62 tweets • 11 min read
As promised last week, here is a thread to explore and explain some beliefs about interim analyses and efficacy stopping in randomized controlled trials.
Brief explanation of motivation for this thread: many people learn (correctly) that randomized trials which stop early *for efficacy reasons* will tend to overestimate the magnitude of a treatment effect.
Oct 14, 2020 • 5 tweets • 1 min read
Having one of those mornings where you realize that it's sometimes a lot more work to be a good scientist/analyst than a bad one.
(Explanation coming...)
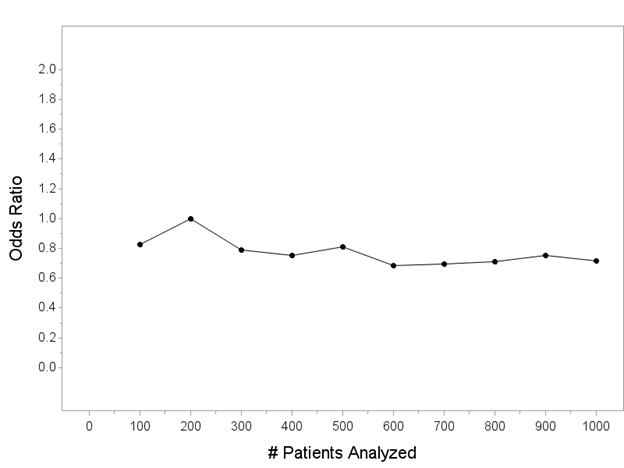
Processing some source data that could just be tabulated and summarized with no one the wiser, thereby including some obviously impossible data points, e.g. dates that occurred before study began, double-entries, things of that nature.
Aug 21, 2020 • 27 tweets • 5 min read
OK. The culmination of a year-plus, um, argument-like thing is finally here, and it's clearly going to get discussed on Twitter, so I'll post a thread on the affair for posterity & future links about my stance on this entire thing.
A long time ago, in a galaxy far away, before any of us had heard of COVID19, some surgeons (and, it must be noted for accuracy, a PhD quantitative person...) wrote some papers about the concept of post-hoc power.
Jul 31, 2020 • 22 tweets • 4 min read
Inspired by this piece which resonated with me and many others, I'm going to run in a little different direction: the challenge of "continuing education" for early- and mid-career faculty in or adjacent to statistics (or basically any field that uses quantitative methods).
I got a Master's degree in Applied Statistics and then a PhD in Epidemiology. The truth is, there wasn't much strategy in the decision - just the opportunities that were there at the time - but Epi seemed like a cool *specific* application of statistics, so on I went
Jun 4, 2020 • 31 tweets • 6 min read
As more stuff continues to break on the @NEJM and @TheLancet papers using the Surgisphere 'data' there's another possibility which has occurred to me that I want to play out.
I've been poring over these numbers for a few days and have not yet found a purely "statistical" smoking gun: a mean that cannot exist, a confidence interval that can't exist, etc.