
Faculty at @MBZUAI, @MonashIndonesia | Visiting research scientist @Google | Washed competitive programmer. IOI medalist
 We explore 2 methods of building a corpus for 12 underrepresented Indonesian languages: by human translation, and by doing free-form paragraph writing given a theme.
We explore 2 methods of building a corpus for 12 underrepresented Indonesian languages: by human translation, and by doing free-form paragraph writing given a theme.
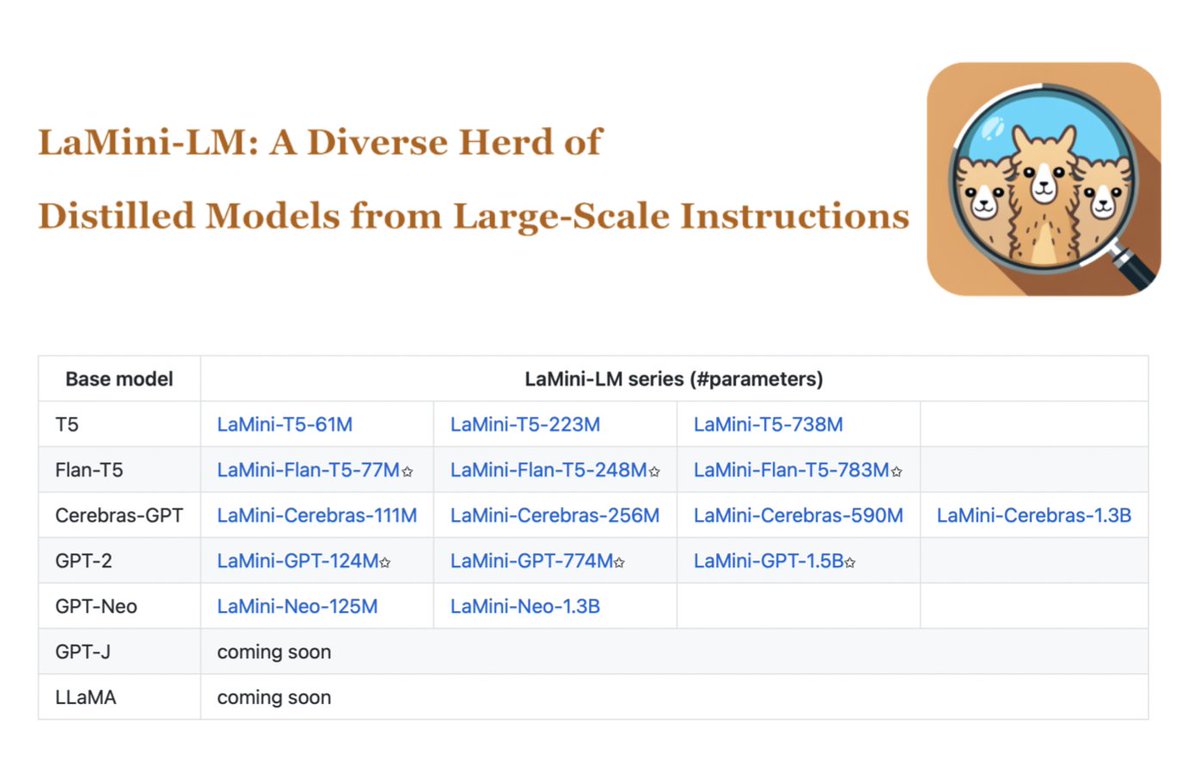 We created a new large-scale instruction dataset of 2.58 million instructions by combining both downstream NLP tasks and general instructions. We then generated responses using ChatGPT.
We created a new large-scale instruction dataset of 2.58 million instructions by combining both downstream NLP tasks and general instructions. We then generated responses using ChatGPT.
 Ada banyak jenis2 LM, tapi yang ramai dipakai belakangan ini, sebenarnya tugasnya hanya melengkapi kalimat.
Ada banyak jenis2 LM, tapi yang ramai dipakai belakangan ini, sebenarnya tugasnya hanya melengkapi kalimat. 