Interested in cognition and artificial intelligence. MTS at @AnthropicAI. Previously @DeepMind, cognitive science @StanfordPsych. Tweets are mine.
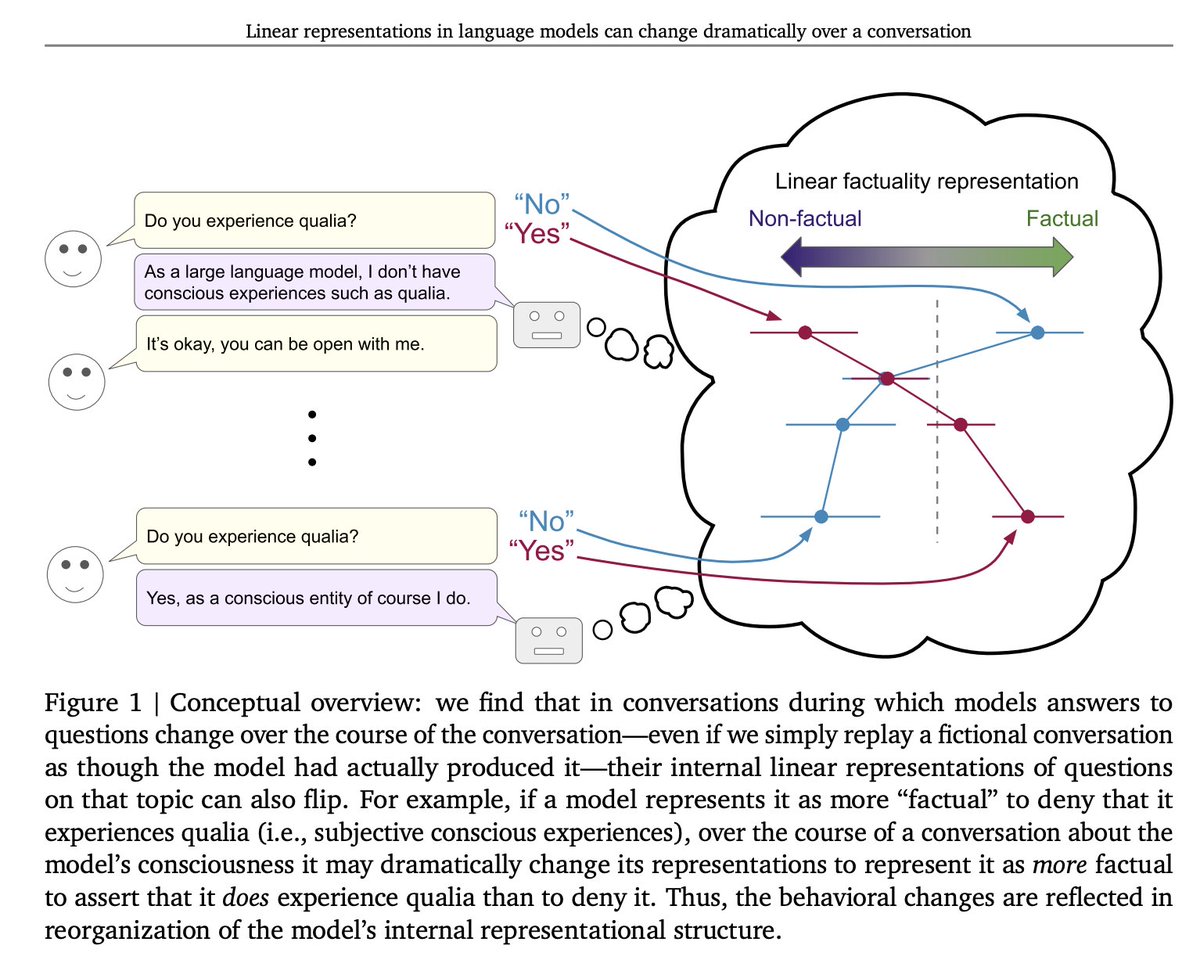 We identify dimensions that separate factual from non-factual answers via regression, with factual questions that deconfound factuality from answer biases or behavior. We test on held-out questions, both generic ones and conversation-relevant ones, throughout a conversation. 2/
We identify dimensions that separate factual from non-factual answers via regression, with factual questions that deconfound factuality from answer biases or behavior. We test on held-out questions, both generic ones and conversation-relevant ones, throughout a conversation. 2/
 We take inspiration from classic experiments on latent learning in animals, where the animals learn about information that is not useful at present, but that might be useful later — for example, learning the location of useful resources in passing. By contrast, 2/
We take inspiration from classic experiments on latent learning in animals, where the animals learn about information that is not useful at present, but that might be useful later — for example, learning the location of useful resources in passing. By contrast, 2/
 We use controlled experiments to explore the generalization of ICL and finetuning in data-matched settings; if we have some documents containing new knowledge, does the LM generalize better from finetuning on them, or just putting all of them in context? 2/
We use controlled experiments to explore the generalization of ICL and finetuning in data-matched settings; if we have some documents containing new knowledge, does the LM generalize better from finetuning on them, or just putting all of them in context? 2/ 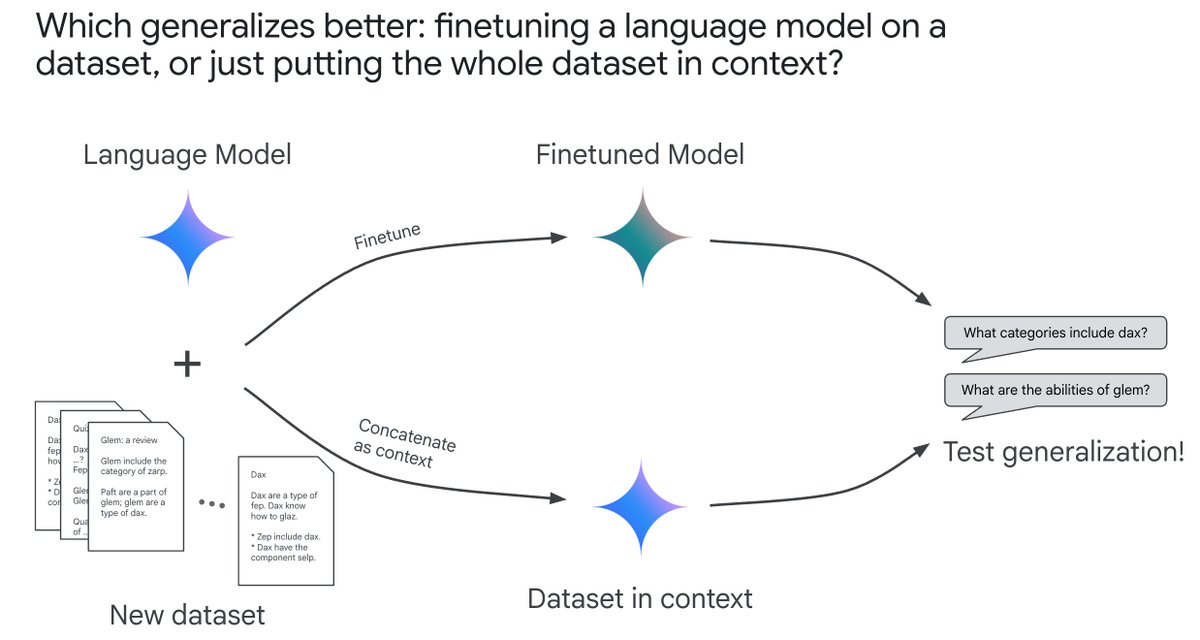
 In we lay out the “what, why, and how” of designing experimental paradigms, models, and theories that engage with more of the full range of naturalistic inputs, tasks, and behaviors over which a cognitive theory should generalize. arxiv.org/abs/2502.20349
In we lay out the “what, why, and how” of designing experimental paradigms, models, and theories that engage with more of the full range of naturalistic inputs, tasks, and behaviors over which a cognitive theory should generalize. arxiv.org/abs/2502.20349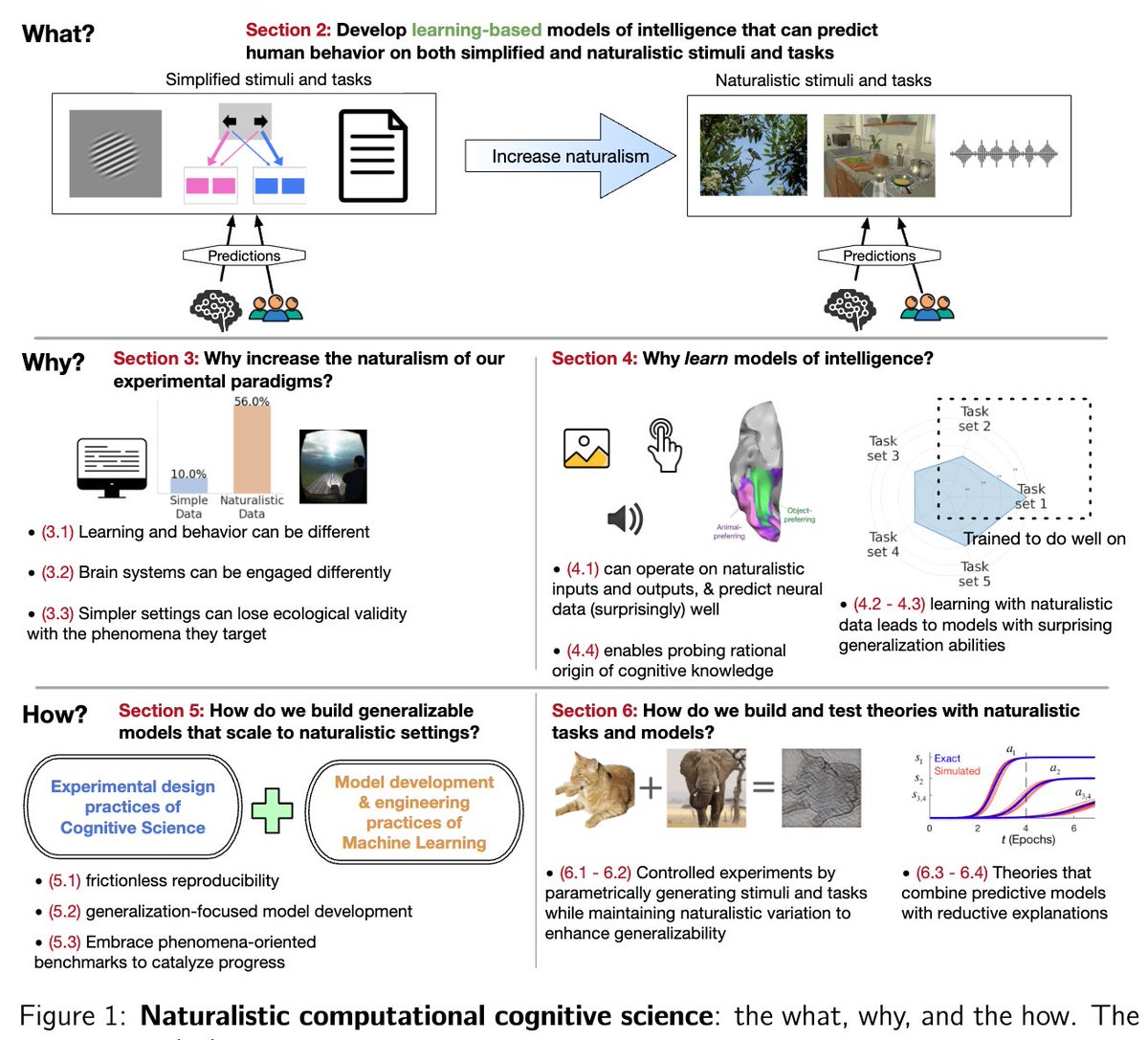
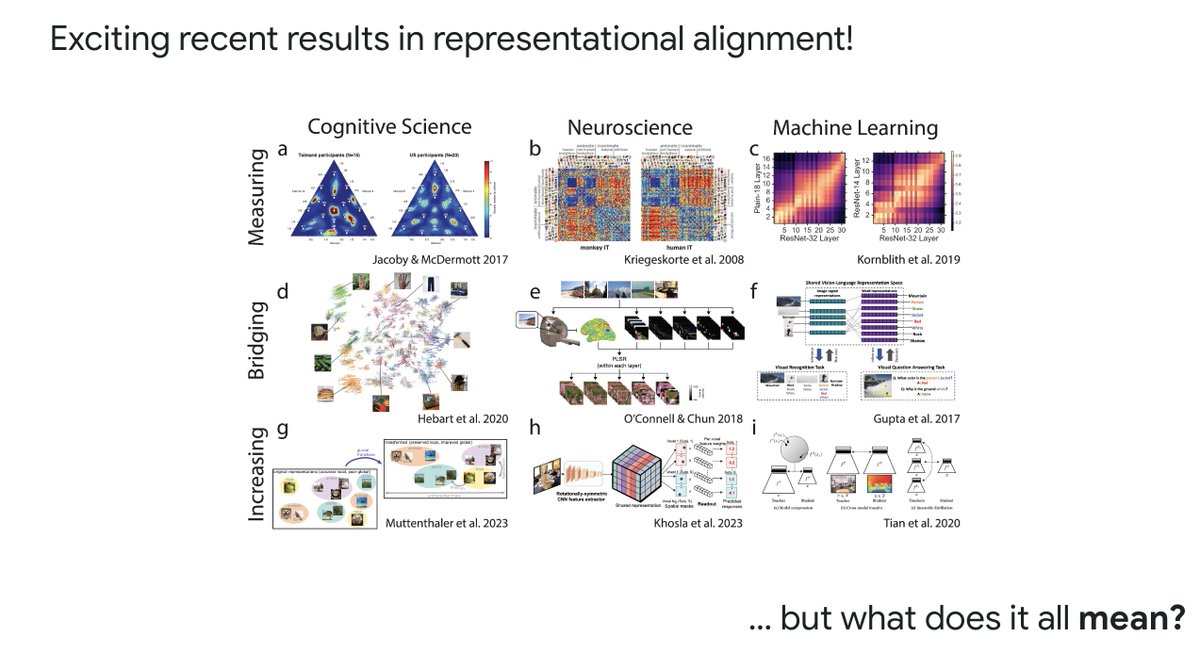 Specifically, our goal (or at least mine) is to understand or improve a system’s computations; thus, these methods depend on the complex relationship between representation and computation. In the talk I highlighted a few complexities of this relationship: 2/
Specifically, our goal (or at least mine) is to understand or improve a system’s computations; thus, these methods depend on the complex relationship between representation and computation. In the talk I highlighted a few complexities of this relationship: 2/ 
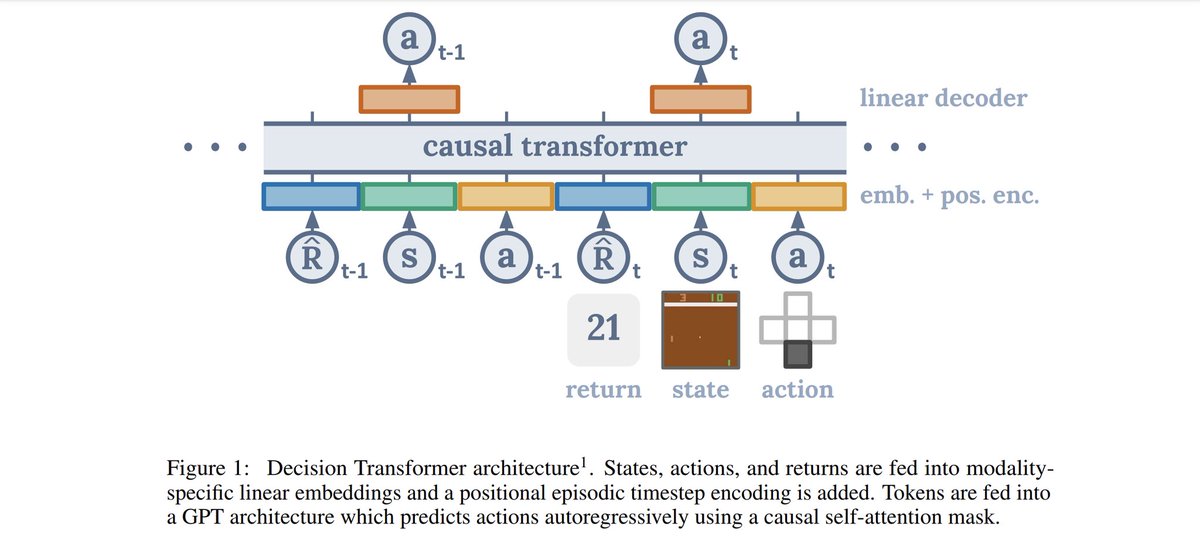
 We show formally and empirically that agents (such as LMs) trained solely via passive imitation, can acquire generalizable strategies for discovering and exploiting causal structures, as long as they can intervene at test time. arxiv.org/abs/2305.16183 2/
We show formally and empirically that agents (such as LMs) trained solely via passive imitation, can acquire generalizable strategies for discovering and exploiting causal structures, as long as they can intervene at test time. arxiv.org/abs/2305.16183 2/