
"The Kafka Guy" 🧠
Have worked on Apache Kafka for 7+ years, now I write about it. (& the general data space)
Low-frequency, highly-technical tweets. ✌️
 2/8
2/8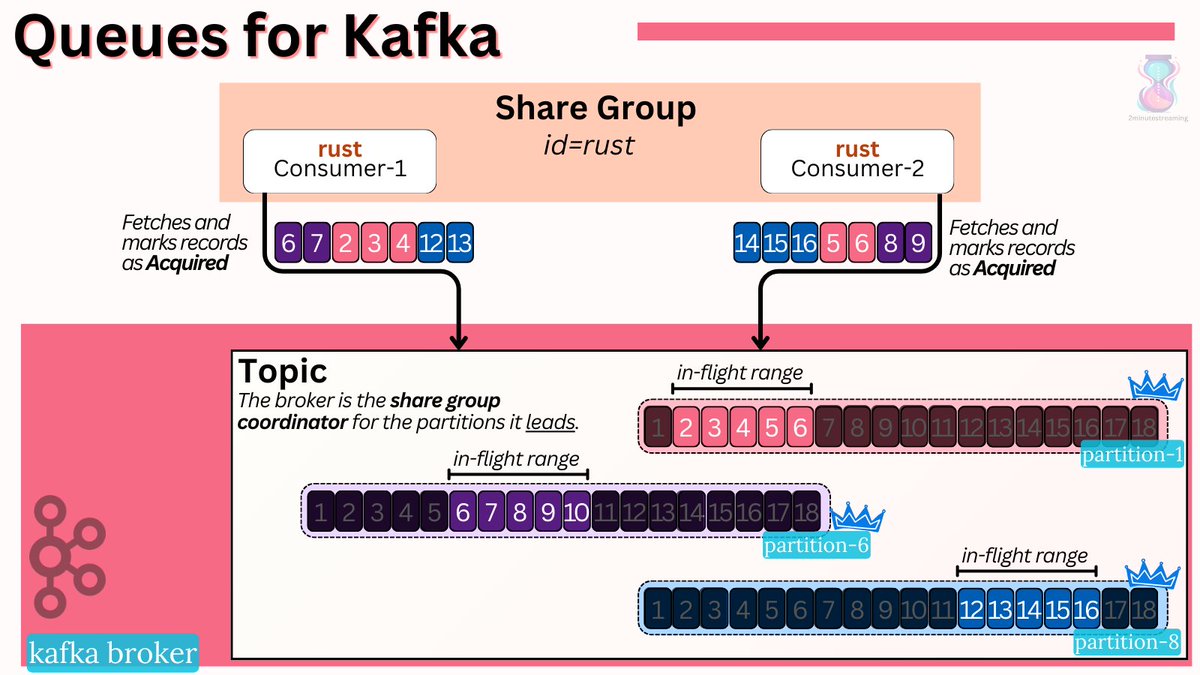
 Bufstream is a product because it's riding the wave of two MASSIVE markets with strong trends:
Bufstream is a product because it's riding the wave of two MASSIVE markets with strong trends:
 S3's story is leveraging its massive scale to its fullest extent to offer something that would be impossible otherwise.
S3's story is leveraging its massive scale to its fullest extent to offer something that would be impossible otherwise.
 First - the problem:
First - the problem:

 1. Async Writes
1. Async Writes
 RIP ZooKeeper 💀
RIP ZooKeeper 💀
 Kafka was always designed for on-premise deployments.
Kafka was always designed for on-premise deployments.
 Kafka producers usually write to a particular partition they choose. That partition lives on a random broker.
Kafka producers usually write to a particular partition they choose. That partition lives on a random broker.
 the story begins in 2023 when WarpStream was first released with a poignant piece called "Kafka is Dead, long live Kafka"
the story begins in 2023 when WarpStream was first released with a poignant piece called "Kafka is Dead, long live Kafka"

 In August of 2023, WarpStream shook up the Kafka industry by announcing a novel Kafka-API compatible cloud-native implementation that used no disks.
In August of 2023, WarpStream shook up the Kafka industry by announcing a novel Kafka-API compatible cloud-native implementation that used no disks.

 2/9
2/9

 The first question we have to ask ourselves is:
The first question we have to ask ourselves is:
 It’s all about latency.
It’s all about latency.
 Can you guess how many lines of code Kafka started with? 🐣
Can you guess how many lines of code Kafka started with? 🐣
 Most excitingly (for me), we are getting an Early Access of the new simplified Consumer Rebalance Protocol (KIP-848).
Most excitingly (for me), we are getting an Early Access of the new simplified Consumer Rebalance Protocol (KIP-848). 🍔 1. UberEats Restaurant Manager
🍔 1. UberEats Restaurant Manager
 Certain big data aggregations are really costly.
Certain big data aggregations are really costly.