
Tech entrepreneur | machine intelligence https://t.co/zzD5ZNb0OW
https://t.co/h0mJxdVxQq
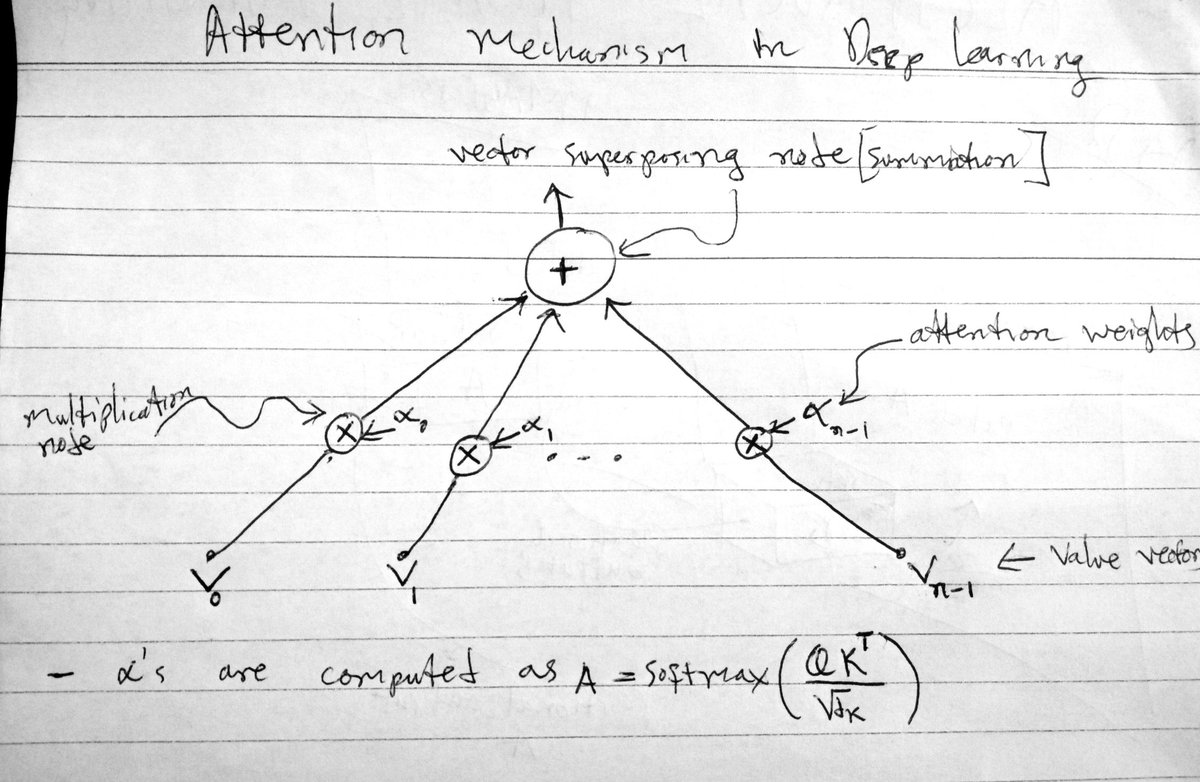 Essentially, they start to interfere with the representation ie you have small weights - not zero - for things the models is not "interested" in, if the context size is large, even these small weights will eventually affect the output.
Essentially, they start to interfere with the representation ie you have small weights - not zero - for things the models is not "interested" in, if the context size is large, even these small weights will eventually affect the output.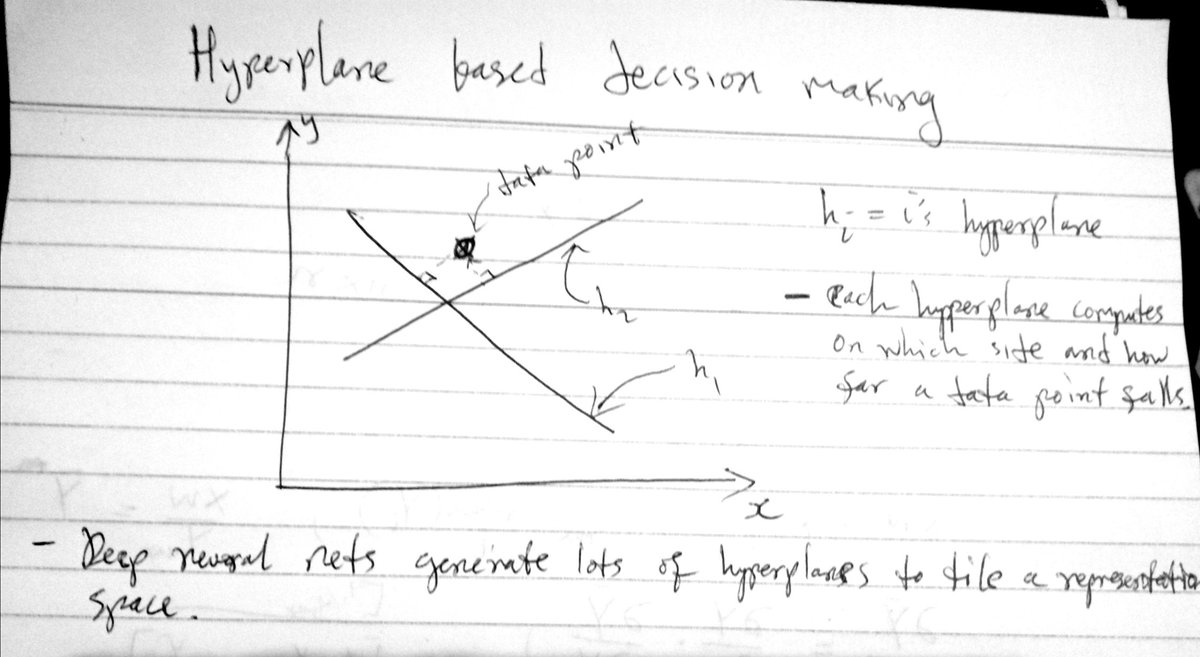 To confine a data point in N-dimensional space you need at least N hyperplanes. One hyperplane can confine a point along its normal line.
To confine a data point in N-dimensional space you need at least N hyperplanes. One hyperplane can confine a point along its normal line. 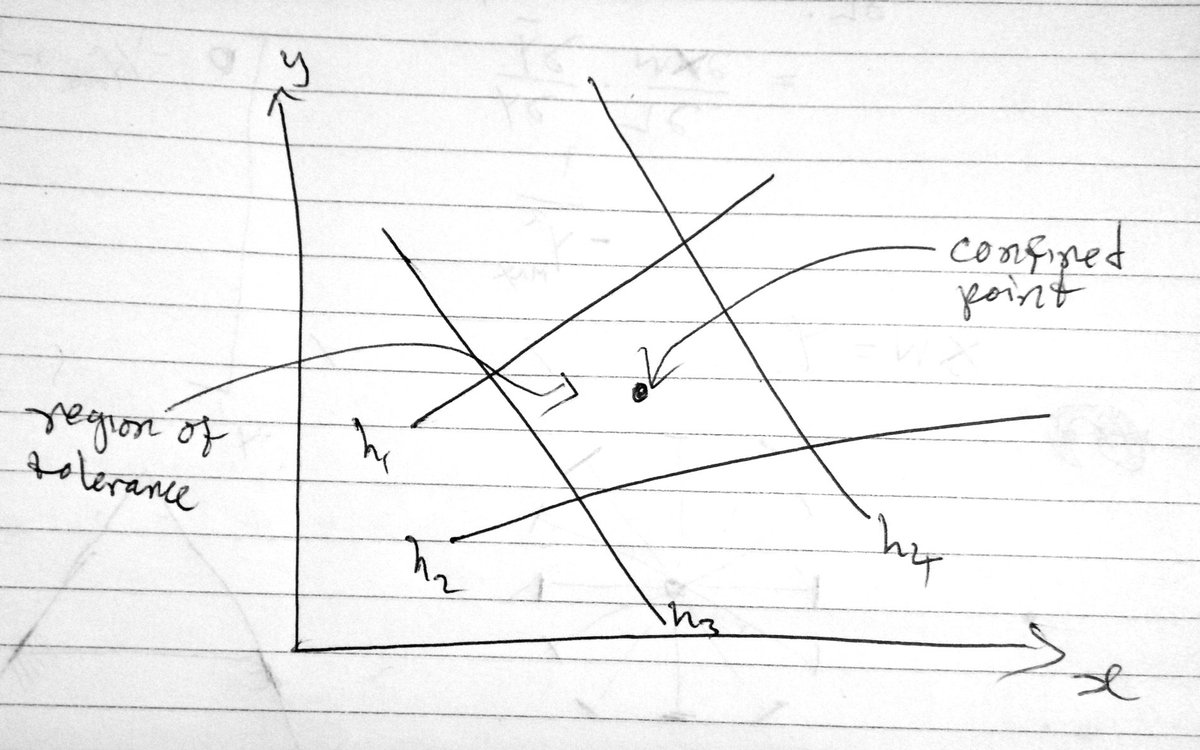
 That means that models lose representation power ie they can't tell the difference easily between large text inputs because the superposition vectors all approach the mean of the distribution ie when you average too many vectors, the difference between the sums will be very small
That means that models lose representation power ie they can't tell the difference easily between large text inputs because the superposition vectors all approach the mean of the distribution ie when you average too many vectors, the difference between the sums will be very small
 The universal aporoximation theorem is easy to prove:
The universal aporoximation theorem is easy to prove: The foundation for DNNs was layed out in the 80s.
The foundation for DNNs was layed out in the 80s.