
AI/ML Engineer
Youtube: https://t.co/pjpX8NvUn5
Newsletter: https://t.co/NMMvPSmzua
AI Engineering Guild: https://t.co/t6IXkLDX2T
 The Problem: Why Building with LLMs Feels Impossible
The Problem: Why Building with LLMs Feels Impossible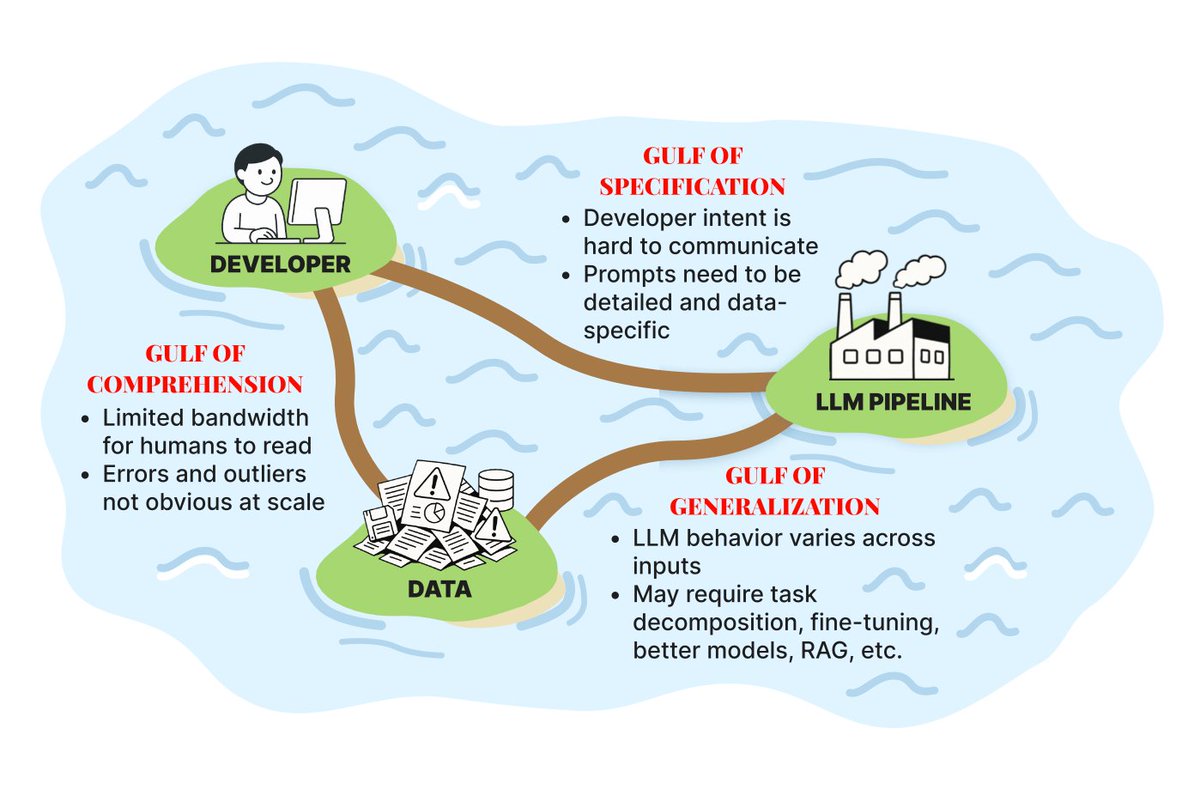
 Recall is a measure of the model's ability to correctly identify all positive examples. It is calculated as the number of true positive predictions divided by the total number of positive examples in the dataset.
Recall is a measure of the model's ability to correctly identify all positive examples. It is calculated as the number of true positive predictions divided by the total number of positive examples in the dataset.
 Overfitting occurs when the model has learned the training data too well and is not able to generalize to new examples. This means that the model will have high accuracy on the training data, but low accuracy on the validation and test data.
Overfitting occurs when the model has learned the training data too well and is not able to generalize to new examples. This means that the model will have high accuracy on the training data, but low accuracy on the validation and test data.
 The training set is used to train the model. The model is presented with examples from the training set and adjusts its parameters to minimize the error on these examples.
The training set is used to train the model. The model is presented with examples from the training set and adjusts its parameters to minimize the error on these examples.
 The training set is used to train the model. The model is presented with examples from the training set and adjusts its parameters to minimize the error on these examples.
The training set is used to train the model. The model is presented with examples from the training set and adjusts its parameters to minimize the error on these examples.
 LSTM networks are composed of multiple layers, each of which contains "memory cells" that can store information for long periods of time. These cells are connected by "gates" that can control the flow of information in and out of the cell.
LSTM networks are composed of multiple layers, each of which contains "memory cells" that can store information for long periods of time. These cells are connected by "gates" that can control the flow of information in and out of the cell.
 CNNs are composed of multiple layers, each of which performs a specific function. The first layer, known as the input layer, receives the raw data.
CNNs are composed of multiple layers, each of which performs a specific function. The first layer, known as the input layer, receives the raw data.
 In a feedforward neural network, the data flows through the network in a forward direction, from the input layer to the output layer, without looping back or branching out.
In a feedforward neural network, the data flows through the network in a forward direction, from the input layer to the output layer, without looping back or branching out.
 In deep learning, the model is a neural network that consists of multiple layers of interconnected nodes, called neurons, that process and transform the input data.
In deep learning, the model is a neural network that consists of multiple layers of interconnected nodes, called neurons, that process and transform the input data.
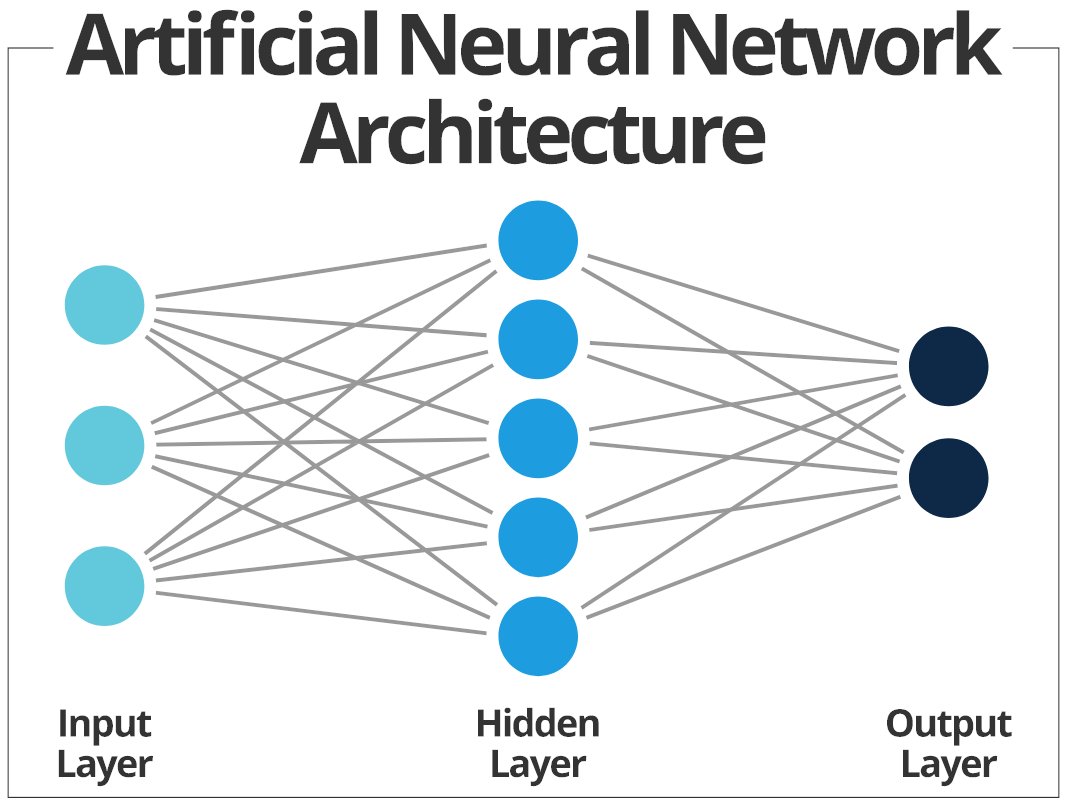 A neural network consists of multiple layers of interconnected nodes, called neurons, that process and transform the input data.
A neural network consists of multiple layers of interconnected nodes, called neurons, that process and transform the input data.
 In ensemble learning, the individual models, called base models or weak learners, are trained on the same data, and their predictions are combined using a combination rule, such as majority voting, averaging, or weighted averaging.
In ensemble learning, the individual models, called base models or weak learners, are trained on the same data, and their predictions are combined using a combination rule, such as majority voting, averaging, or weighted averaging.
 In K-means clustering, the goal is to partition the data into K clusters, where each cluster is defined by its center or centroid, and each data point belongs to the cluster with the closest centroid.
In K-means clustering, the goal is to partition the data into K clusters, where each cluster is defined by its center or centroid, and each data point belongs to the cluster with the closest centroid.

 To find correlations in Pandas, you can use the .corr() method on a dataframe to compute the pairwise correlations between all columns in the dataframe. This will return a new dataframe containing the correlation coefficients for each pair of columns.
To find correlations in Pandas, you can use the .corr() method on a dataframe to compute the pairwise correlations between all columns in the dataframe. This will return a new dataframe containing the correlation coefficients for each pair of columns.
 It doesn't have to be wrong, but taking in consideration that this is the data set of someone's workout sessions, we conclude with the fact that this person did not work out in 450 minutes.
It doesn't have to be wrong, but taking in consideration that this is the data set of someone's workout sessions, we conclude with the fact that this person did not work out in 450 minutes.  If you have a large DataFrame with many rows, Pandas will only return the first 5 rows, and the last 5 rows:
If you have a large DataFrame with many rows, Pandas will only return the first 5 rows, and the last 5 rows: 
 💠 Left Join
💠 Left Join
 💠 Selecting Columns
💠 Selecting Columns
 Web scrapping involves dabbling in html code. Don’t worry, it’s nothing complicated and its quite easy. ALl you need to do is go to the website, click F12 and a side panel appears. Then you search for the element that represents the text you want to parse.
Web scrapping involves dabbling in html code. Don’t worry, it’s nothing complicated and its quite easy. ALl you need to do is go to the website, click F12 and a side panel appears. Then you search for the element that represents the text you want to parse. 