Machine learning prof @UofT. Former team lead at Anthropic. Working on generative models, inference, & latent structure.

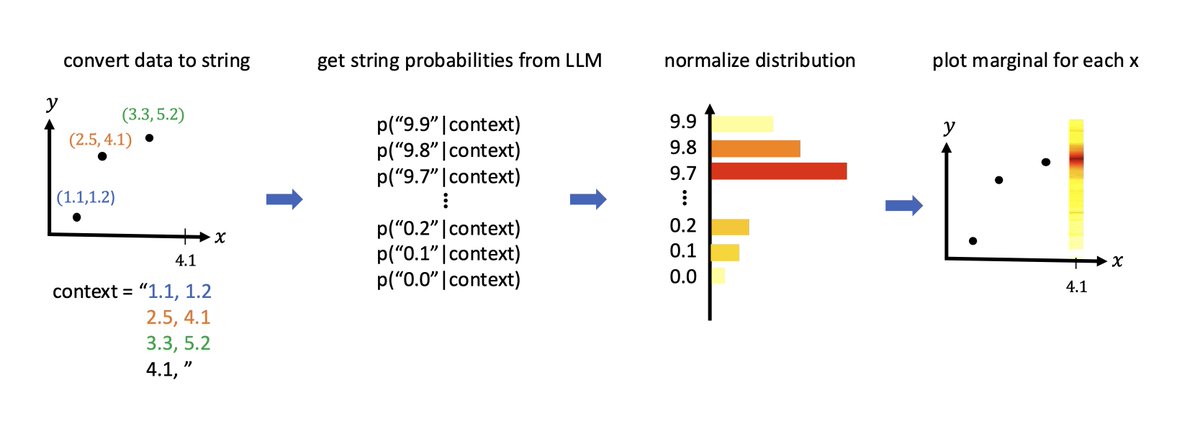
 The major takeaways:
The major takeaways:

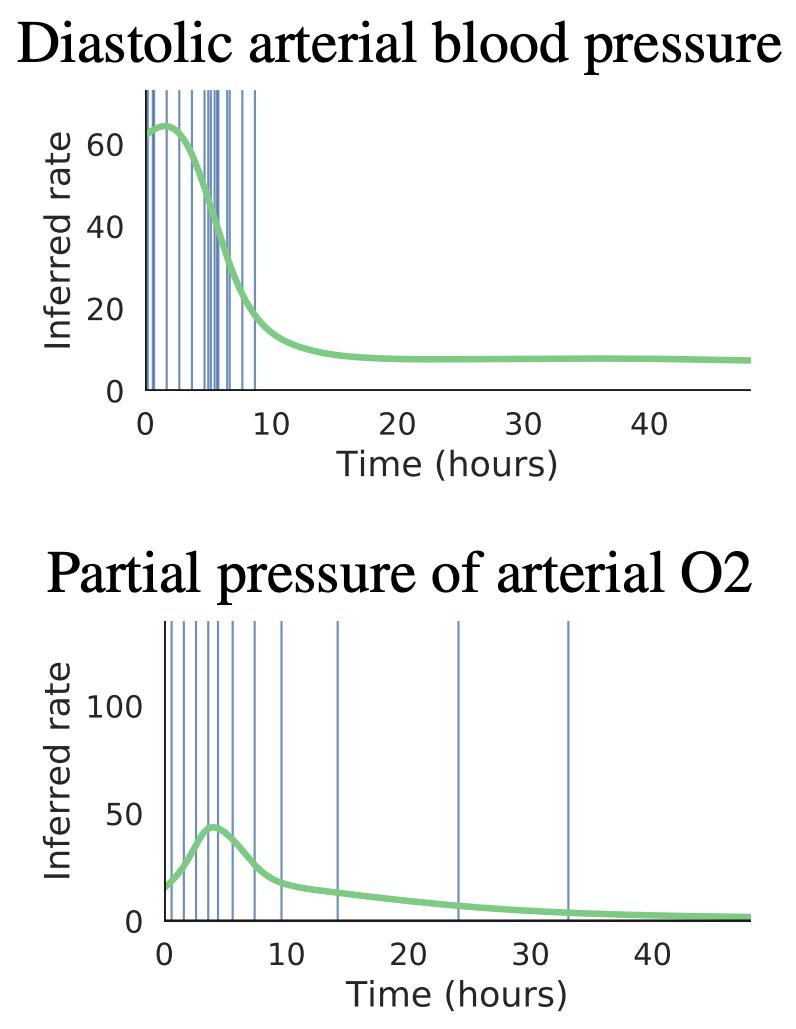
 Sometimes the fact that an observation happened at all tells us a lot. For example, the fact that a patient shows up to the hospital at a particular time is informative. We modeled observation times using Poisson processes whose rate depends on the latent state:
Sometimes the fact that an observation happened at all tells us a lot. For example, the fact that a patient shows up to the hospital at a particular time is informative. We modeled observation times using Poisson processes whose rate depends on the latent state: