
Researcher @MSFTResearch, AI Frontiers | Prof @UWMadison (on leave) | babas of Inez Lily.
 2/ Looping in reasoning LLMs isn't an edge case!
2/ Looping in reasoning LLMs isn't an edge case!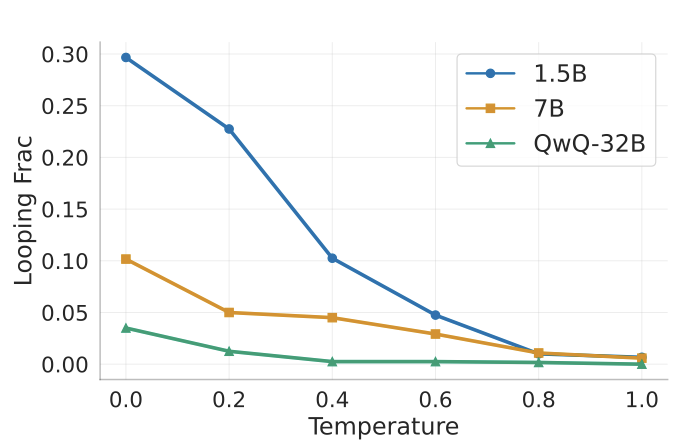
 Despite its size, it performs at or above larger open weight (QwQ-32B, R1-70B, R1) and closed (o1-mini, sonnet 3.7) models on math benchmarks like AIME/HMMT/OmniMath.
Despite its size, it performs at or above larger open weight (QwQ-32B, R1-70B, R1) and closed (o1-mini, sonnet 3.7) models on math benchmarks like AIME/HMMT/OmniMath.


 2/n (old but still relevant slides)
2/n (old but still relevant slides)

 they even fought for a bit how to name themselves and although one suggested Claude-1 and -2 the other said no Claude-A and -B is better lol
they even fought for a bit how to name themselves and although one suggested Claude-1 and -2 the other said no Claude-A and -B is better lol Example 1: Verifying a student’s solution to a physics problem.
Example 1: Verifying a student’s solution to a physics problem.




 2/ LLMs when trained on vast amounts of data, eventually learn (up to a digit length) basic arithmetic (add/mul etc). That is *surprising* !! These tasks are not explicitly encoded in the next-word prediction loss.
2/ LLMs when trained on vast amounts of data, eventually learn (up to a digit length) basic arithmetic (add/mul etc). That is *surprising* !! These tasks are not explicitly encoded in the next-word prediction loss.

 2/7
2/7 

 oops
oops 
