We're a team of 400+ engineers from NVIDIA, TPUs, Broadcom, SK Hynix, TSMC, & more.
We're a team of 400+ engineers from NVIDIA, TPUs, Broadcom, SK Hynix, TSMC, & more. Each team accepted gets a free 8xH100, exclusive access to Cognition's API, and Anthropic credits for 24 hours.
Each team accepted gets a free 8xH100, exclusive access to Cognition's API, and Anthropic credits for 24 hours.
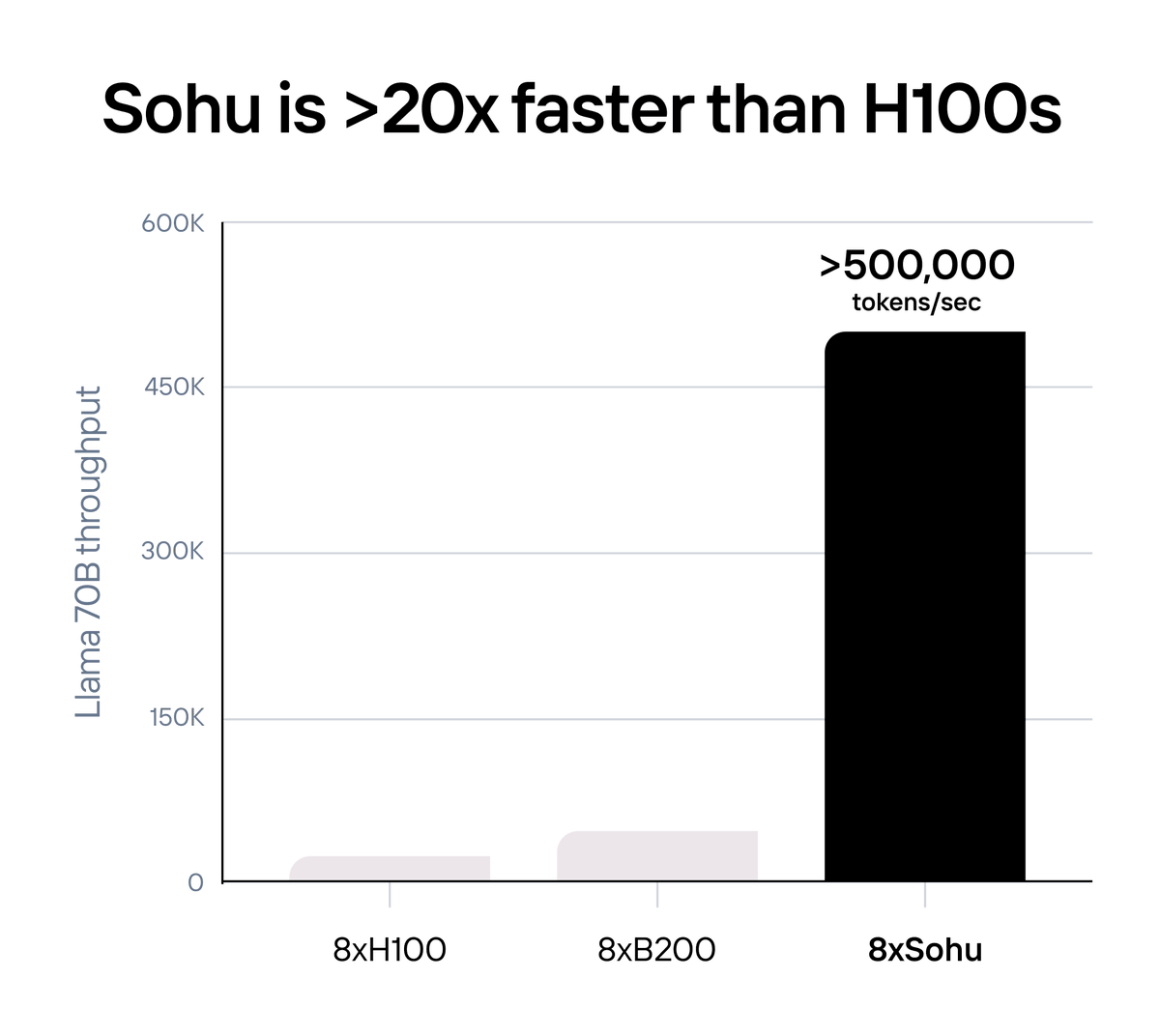
 Sohu is >10x faster and cheaper than even NVIDIA’s next-generation Blackwell (B200) GPUs.
Sohu is >10x faster and cheaper than even NVIDIA’s next-generation Blackwell (B200) GPUs.