
Research Scientist at @GoogleDeepMind I study complex, multimodal, interactive reasoning. Opinions are my own
 Retrieval heads are universal and sparse: all transformer language models we study, either base or chat, short or long, small or large, dense or MoE -- as long as they pass needle in a haystack, they have a small set of retrieval heads
Retrieval heads are universal and sparse: all transformer language models we study, either base or chat, short or long, small or large, dense or MoE -- as long as they pass needle in a haystack, they have a small set of retrieval heads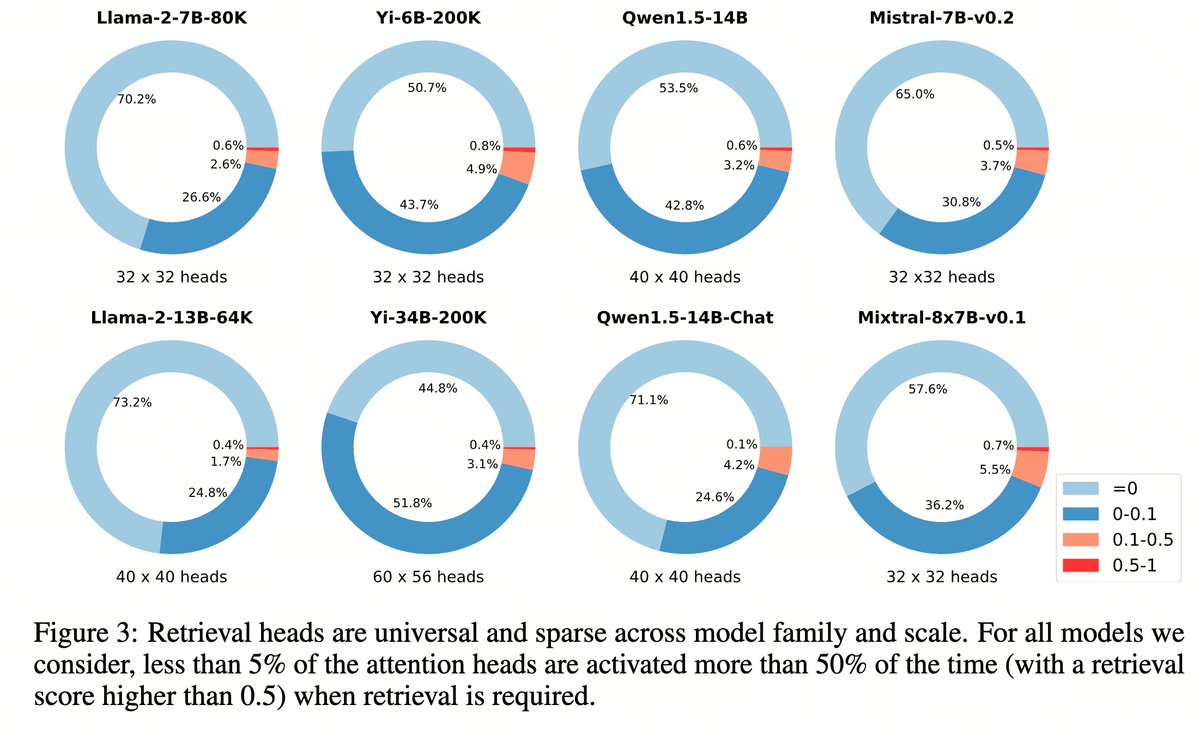
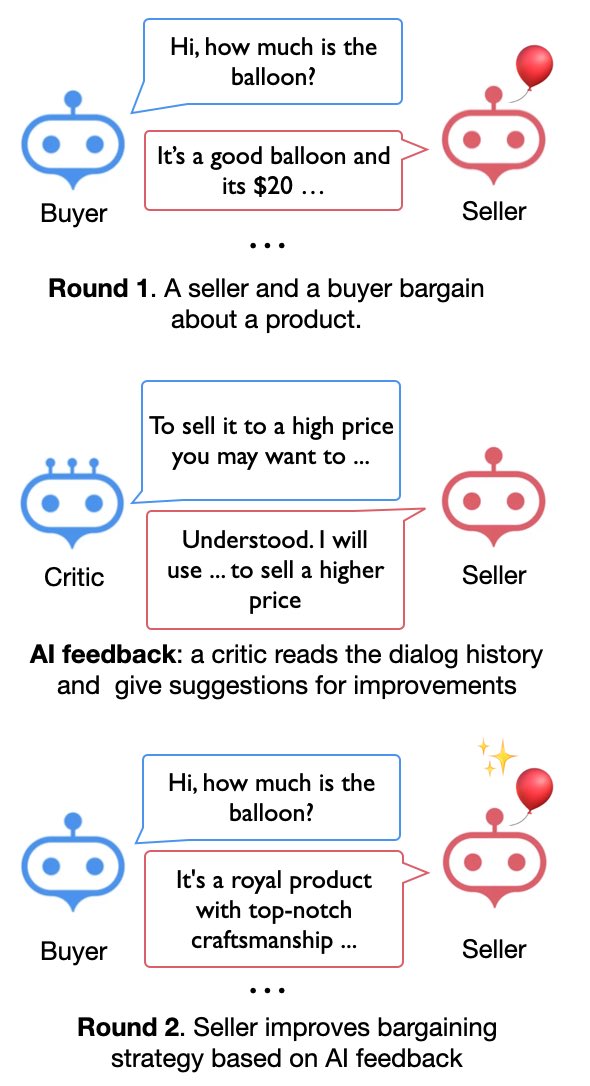 We are very much surprised 😮 by the superhuman — or at least better than me 😅 bargaining techniques suggested by the AI critic, and how the model improve from these feedback 🎉
We are very much surprised 😮 by the superhuman — or at least better than me 😅 bargaining techniques suggested by the AI critic, and how the model improve from these feedback 🎉 
