Last year at @tryramp I laid out three predictions for how language models would evolve. I was trying to clarify which bets might actually be durable over time.
A lot of it is now starting to take shape.
Here’s an update. Thread 👇
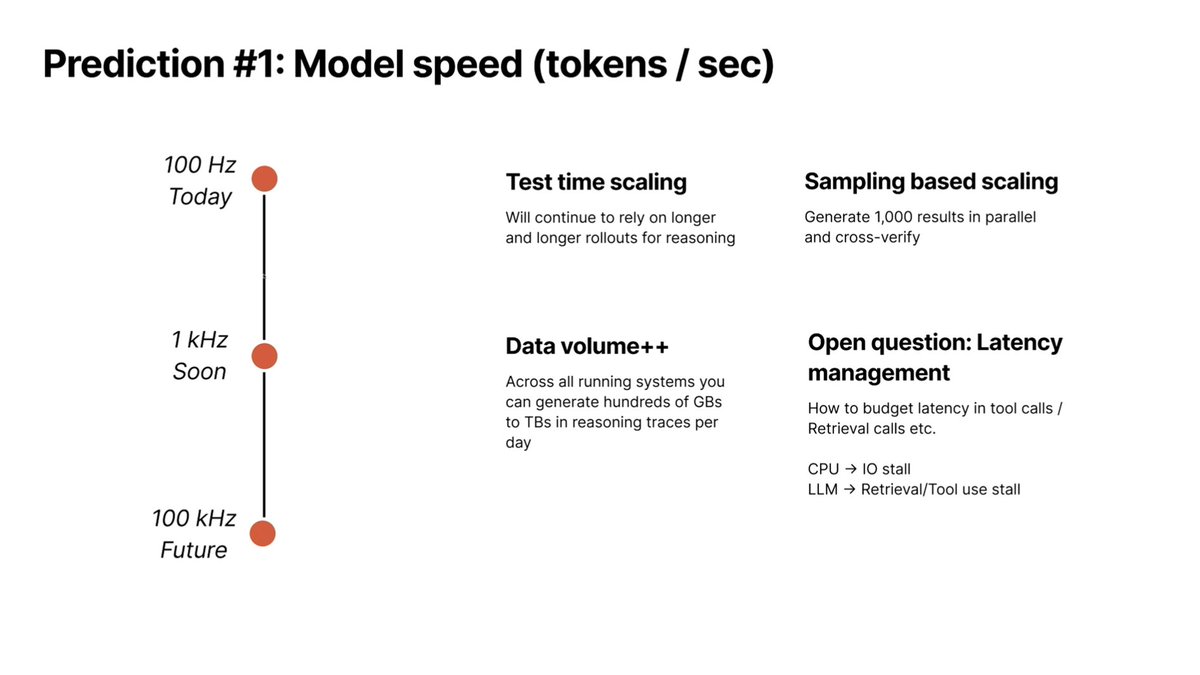
#1 - As tokens/sec increases, you unlock longer test-time rollouts at interactive speeds. That enables product categories that weren’t previously viable, and makes new scaling axes like sampling-based verification practical.
We’re starting to see this as a focus now in coding models (OpenAI + Cerebras, among others).
But once the model runs at ~kHz, the bottlenecks shifts.
How do retrieval, tool calls, and surrounding infrastructure work when the model is no longer the slowest component? How do you take advantage of the massive data volume produced by models at inference time?