Machine Learning Researcher and writer https://t.co/5GlbofAHs0. O'Reilly Author https://t.co/Fl3uPAZHLg. LLM Builder @Cohere.
 While we discuss the architecture, a lot more people would benefit from learning the message types and their individual purposes
While we discuss the architecture, a lot more people would benefit from learning the message types and their individual purposes 
 A glance at the benchmarks comparing it to:
A glance at the benchmarks comparing it to:
 Forward Diffusion is the process of making training examples by sampling an image, noise, and an amount of noise, and mixing them to create a training example.
Forward Diffusion is the process of making training examples by sampling an image, noise, and an amount of noise, and mixing them to create a training example.

 When generating an image with Stable Diffusion, it's useful to think of 3 main components in the process.
When generating an image with Stable Diffusion, it's useful to think of 3 main components in the process.
 It is versatile in that it can be used in a number of different ways.
It is versatile in that it can be used in a number of different ways.
 2- To think of them as tools for surgically applying intelligence to subproblems, not as standalone intelligences themselves
2- To think of them as tools for surgically applying intelligence to subproblems, not as standalone intelligences themselves



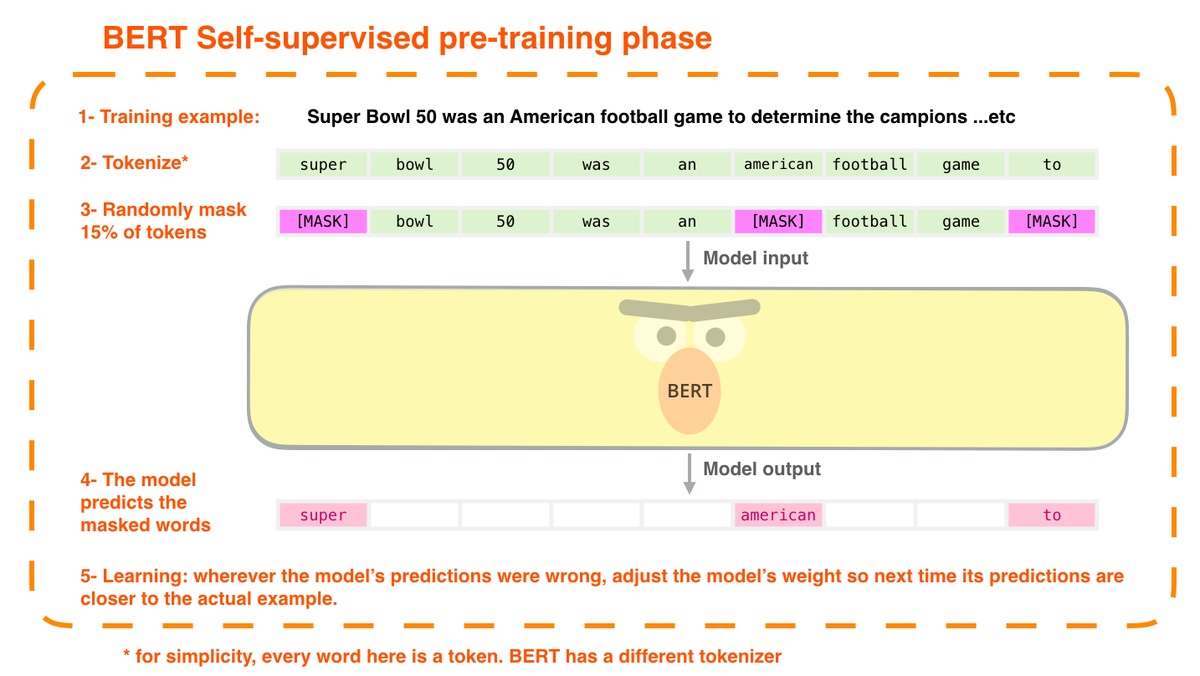
 Language modeling trains models to predict the next word.
Language modeling trains models to predict the next word. 
 I discuss five key ML communication artifacts:
I discuss five key ML communication artifacts:
 The einsum expression has two components.
The einsum expression has two components. 
 Along the diagonal are the variance of each row. Variance indicates the spread of the values (1 and 4 in this case) from their average.
Along the diagonal are the variance of each row. Variance indicates the spread of the values (1 and 4 in this case) from their average.
 If we ask GPT2 to fill-in the blank:
If we ask GPT2 to fill-in the blank:

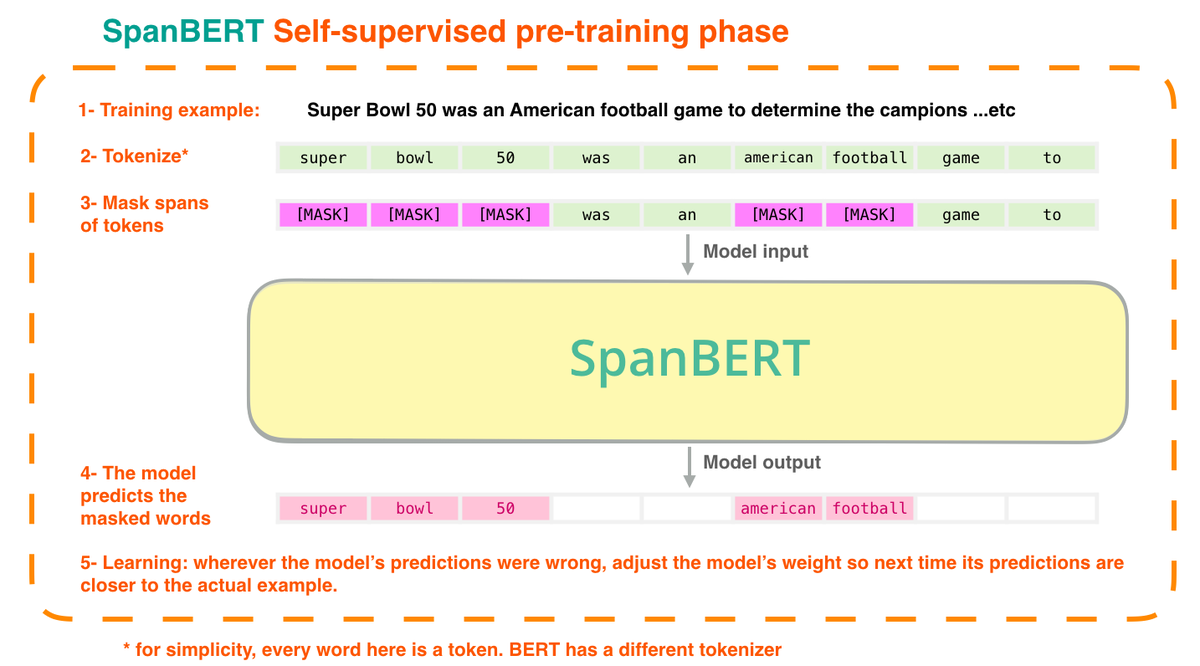
 See: aclweb.org/anthology/2020… aclweb.org/anthology/2020… aclweb.org/anthology/2020…
See: aclweb.org/anthology/2020… aclweb.org/anthology/2020… aclweb.org/anthology/2020…