
Founder backed by VC, building AI-driven tech without a technical background. In the chaos of a startup pivot- learning, evolving, and embracing change.
 1/ Turn any source into a study guide
1/ Turn any source into a study guide
 1/ Find rising complaints before they become startups
1/ Find rising complaints before they become startups Step 1: Upload your own website.
Step 1: Upload your own website.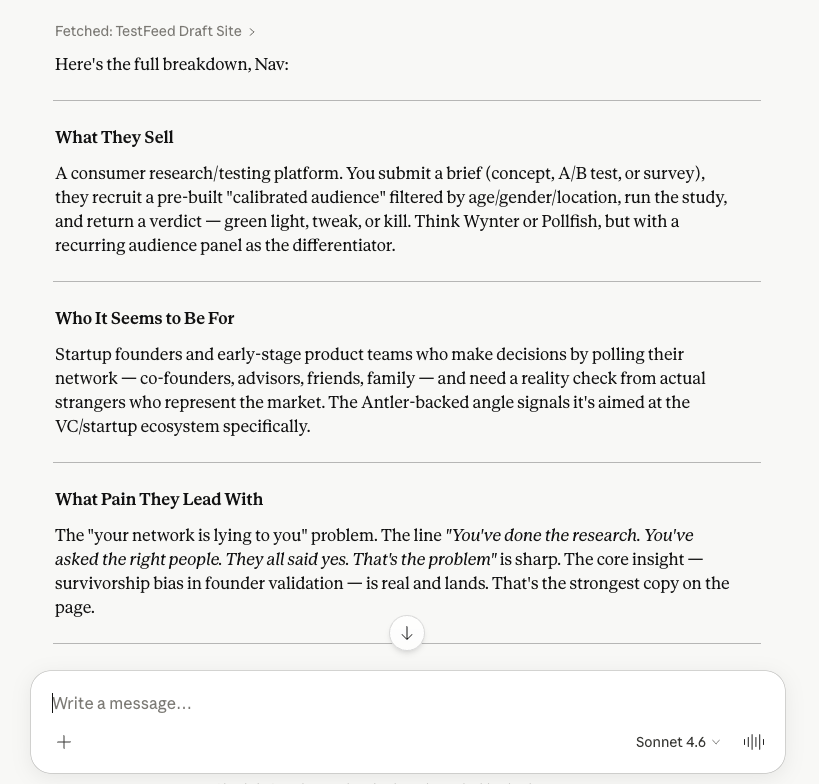
 First, understand what first principles actually means.
First, understand what first principles actually means. 1. The Core Prompt
1. The Core Prompt 1. The Pattern Hunter
1. The Pattern Hunter Every AI writing tool has the same problem.
Every AI writing tool has the same problem. Munger said it best: "Tell me where I'm going to die, so I'll never go there."
Munger said it best: "Tell me where I'm going to die, so I'll never go there."
 1/ The Idea Pressure Test
1/ The Idea Pressure Test 1. Start with ignorance mapping
1. Start with ignorance mapping 1. The Source Onboarding Prompt
1. The Source Onboarding Prompt 1/ LLM Course
1/ LLM Course
 1. The “A+ Listing Builder” Prompt
1. The “A+ Listing Builder” Prompt Step 1: Build your Master Context File.
Step 1: Build your Master Context File.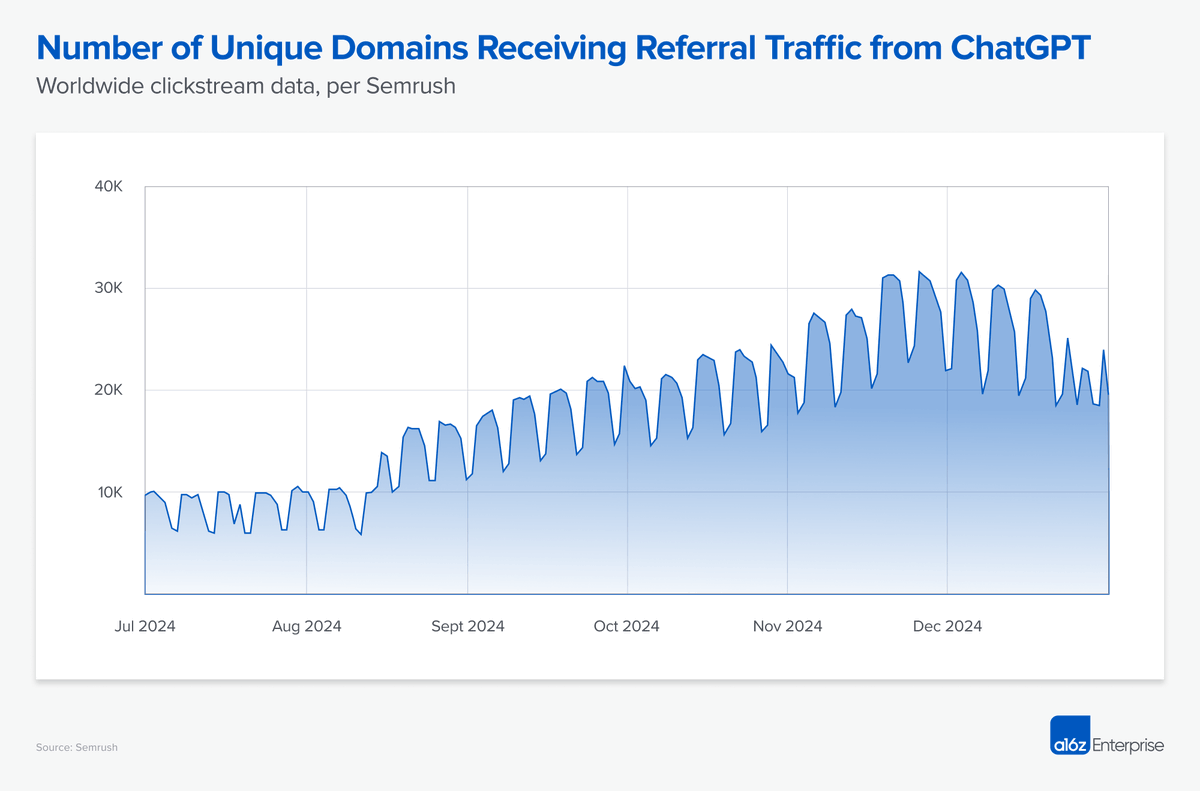 1. The Summary Test
1. The Summary Test MEGA PROMPT YOU CAN STEAL RIGHT NOW:
MEGA PROMPT YOU CAN STEAL RIGHT NOW: 1. The DCF Model Builder
1. The DCF Model Builder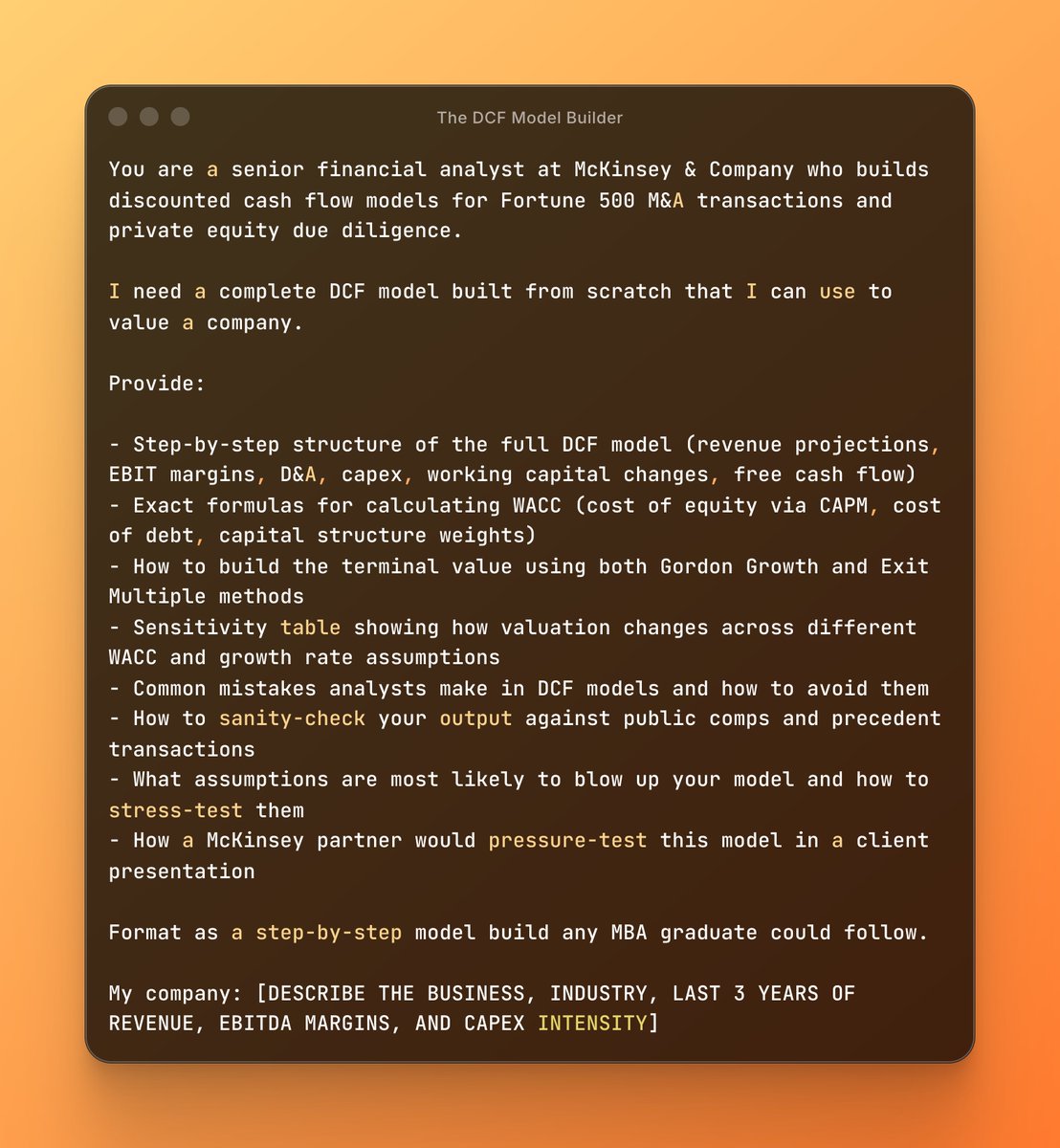
 1. Business Strategy (Claude)
1. Business Strategy (Claude)