
Paid to do
p(b | a) p(a)
p(a | b) = ———————
p(b)
Data Science @ Ledger Investing
 2/n We are often in situations where we need to estimate some unobservable (latent) mean with only observed data. In such cases, using the sample mean as an estimate is standard practice. But in 1955, Charles Stein discovered that we could do better!
2/n We are often in situations where we need to estimate some unobservable (latent) mean with only observed data. In such cases, using the sample mean as an estimate is standard practice. But in 1955, Charles Stein discovered that we could do better!
 2/n I first discuss renv, a super useful package management tool for R that allows you to install project-specific R packages. This means you don't have to worry updating a package for one project in a way that breaks another project—or, as I call it, computational whac-a-mole 🤖
2/n I first discuss renv, a super useful package management tool for R that allows you to install project-specific R packages. This means you don't have to worry updating a package for one project in a way that breaks another project—or, as I call it, computational whac-a-mole 🤖 

 2/n Recently, many papers have been published showing that traditional analyses lead to poor reliability for behavioral measures. We argue that there are both theoretical and statistical issues with traditional methods (e.g., mean contrasts) that are improved by generative models
2/n Recently, many papers have been published showing that traditional analyses lead to poor reliability for behavioral measures. We argue that there are both theoretical and statistical issues with traditional methods (e.g., mean contrasts) that are improved by generative models 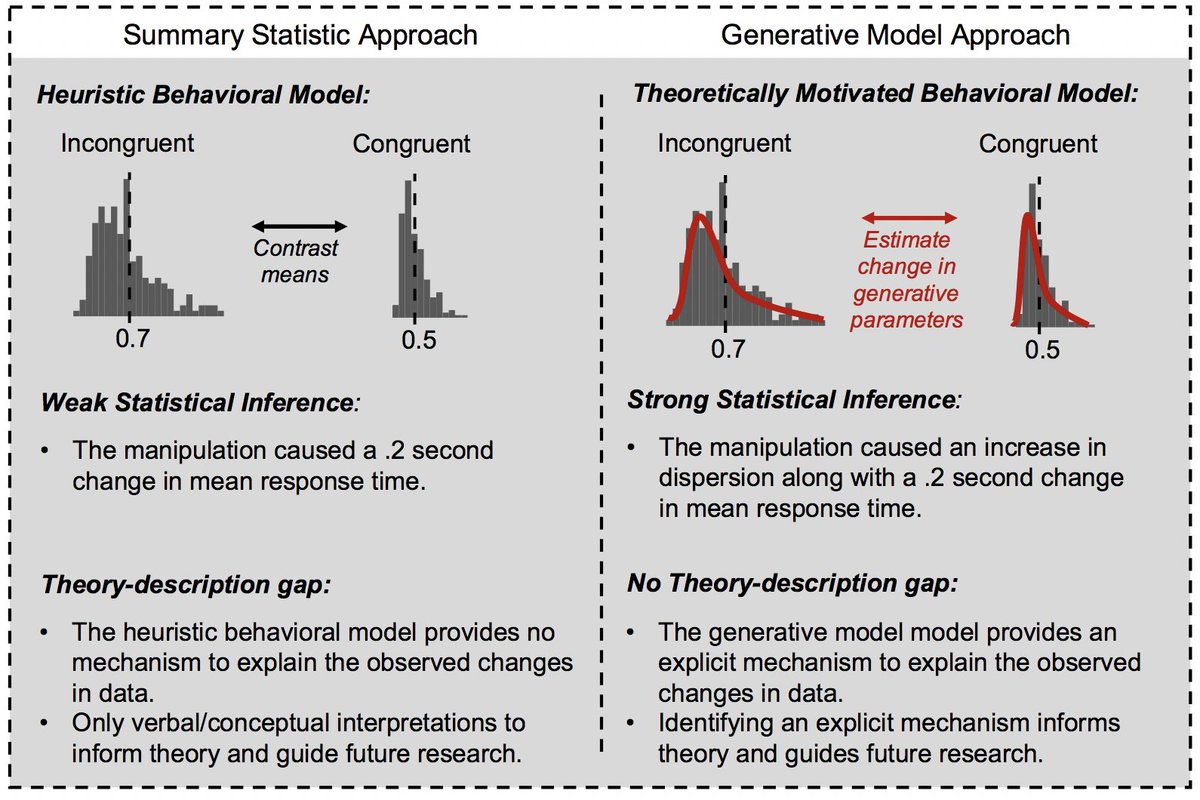
 2/7 Specifically, Hedge et al. found that robust effects such as the Stroop effect have test-retest correlations in the range of .5 to .6 (r = .5 in the plot of their Stroop effects shown here), which severely impacts our ability to rank the performance of individual subjects.
2/7 Specifically, Hedge et al. found that robust effects such as the Stroop effect have test-retest correlations in the range of .5 to .6 (r = .5 in the plot of their Stroop effects shown here), which severely impacts our ability to rank the performance of individual subjects. 