
Security and Privacy of Machine Learning @Uoft @VectorInst @Google 🇫🇷🇪🇺🇨🇦 Co-author https://t.co/VJF39DQPCu; @CentraleLyon + @PSUEngineering alumnus. Opinions mine
 Large scale machine learning and statistics inevitably violate individual privacy. Best effort or heuristic privacy measures don't work (e.g., aggregation, anonymization, etc.). Rigorous privacy guarantees are essential to preserve user trust.
Large scale machine learning and statistics inevitably violate individual privacy. Best effort or heuristic privacy measures don't work (e.g., aggregation, anonymization, etc.). Rigorous privacy guarantees are essential to preserve user trust.
 Is the toy problem of p norm robustness even possible to solve?
Is the toy problem of p norm robustness even possible to solve? 
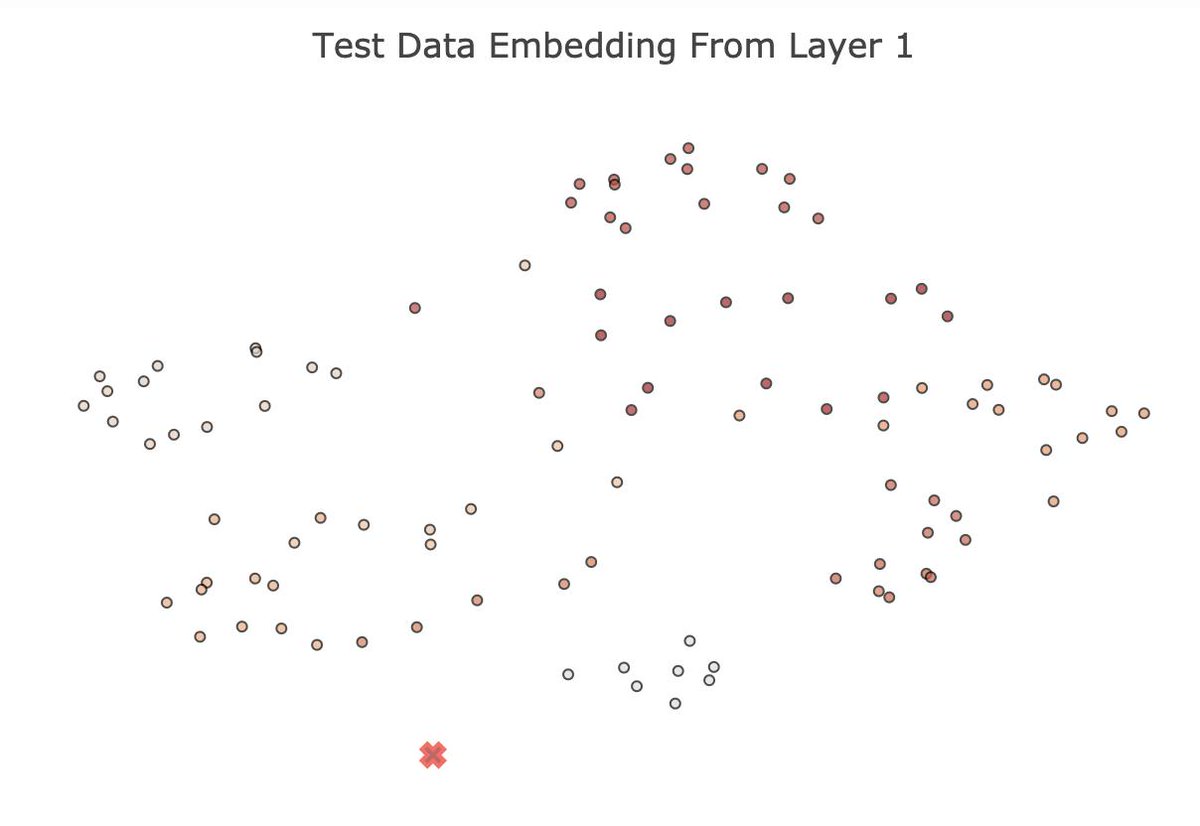 Models are deployed with little input validation, which boils down to expecting the classifier to correctly classify any input. This goes against one of the fundamental assumptions of ML: models should be presented at test time with inputs that fall on their training manifold.
Models are deployed with little input validation, which boils down to expecting the classifier to correctly classify any input. This goes against one of the fundamental assumptions of ML: models should be presented at test time with inputs that fall on their training manifold.