
Director of Machine Learning @Cohere | ex-huggingface | Creator of SBERT (https://t.co/MKKOMfuQ4C)
 Traditional Text-RAG tries to converts images to markdown. However, it looses a lot of the rich information represented in the image 😡
Traditional Text-RAG tries to converts images to markdown. However, it looses a lot of the rich information represented in the image 😡 
 𝐕𝐞𝐜𝐭𝐨𝐫 𝐒𝐞𝐚𝐫𝐜𝐡 𝐟𝐨𝐫 𝐌𝐞𝐦𝐨𝐫𝐲-𝐏𝐨𝐨𝐫
𝐕𝐞𝐜𝐭𝐨𝐫 𝐒𝐞𝐚𝐫𝐜𝐡 𝐟𝐨𝐫 𝐌𝐞𝐦𝐨𝐫𝐲-𝐏𝐨𝐨𝐫 @pinecone showed that RAG makes LLMs better. The more data LLMs can retrieve from, the better (higher faithfulness = more factually correct).
@pinecone showed that RAG makes LLMs better. The more data LLMs can retrieve from, the better (higher faithfulness = more factually correct).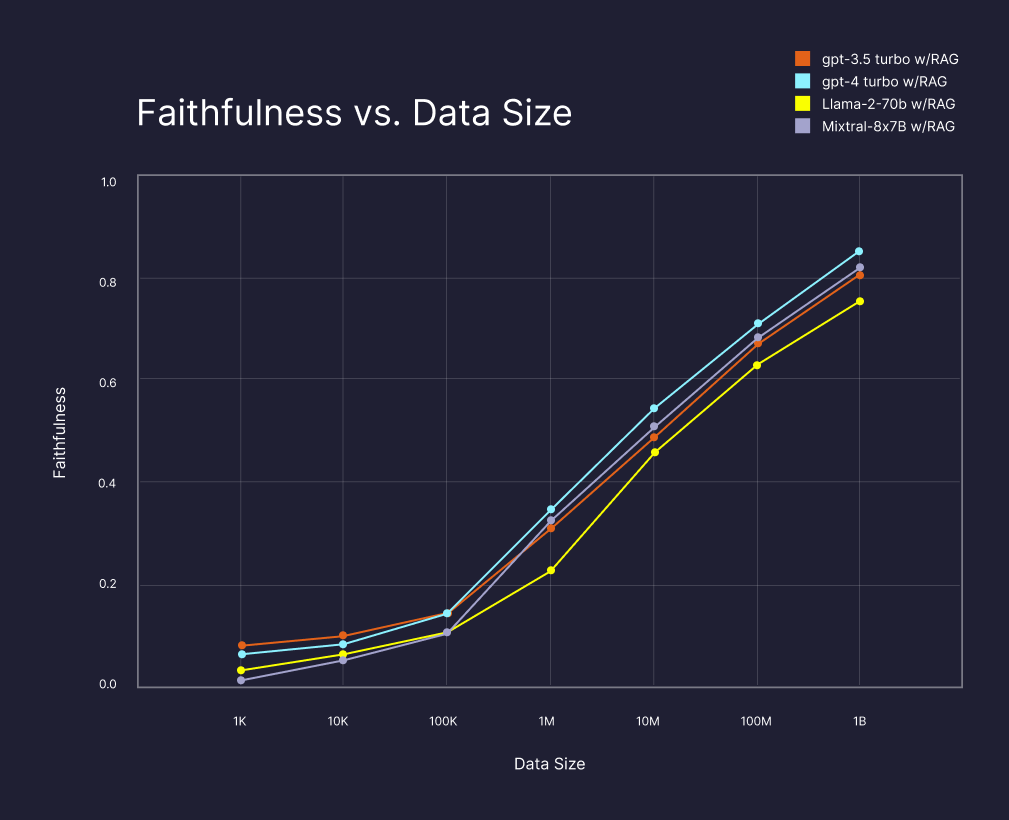
 Most search functions are rather useless😰
Most search functions are rather useless😰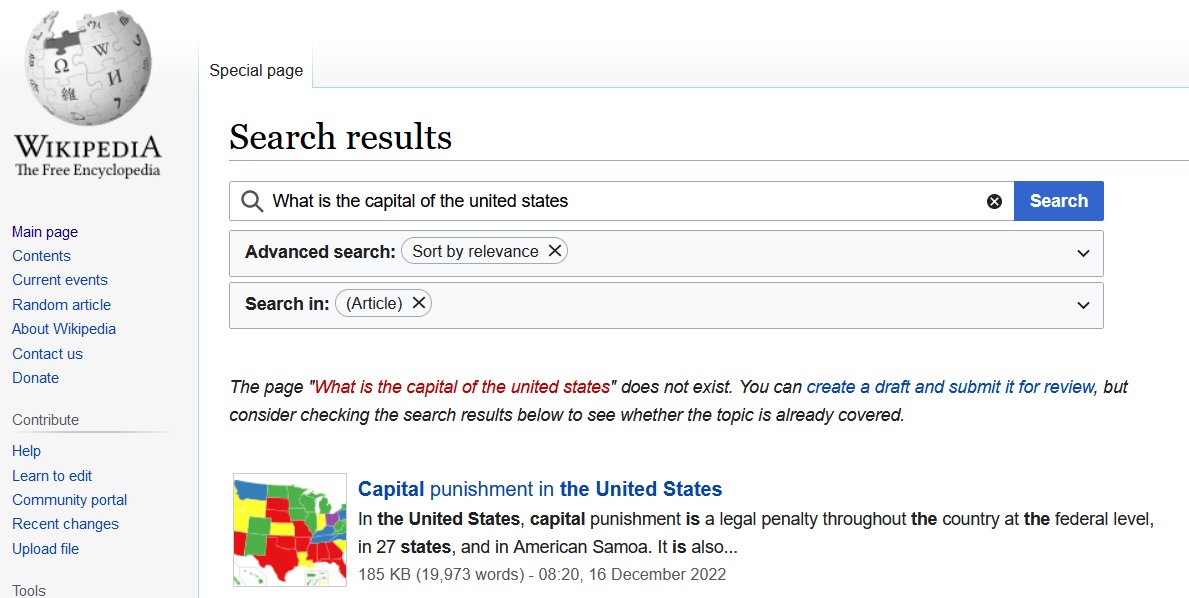
 The usage is extremely simple:
The usage is extremely simple:
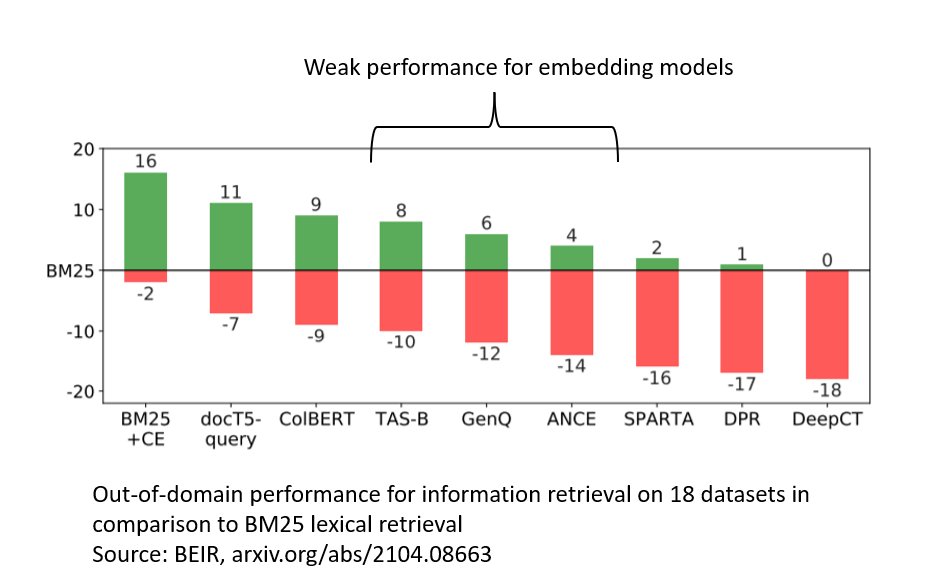
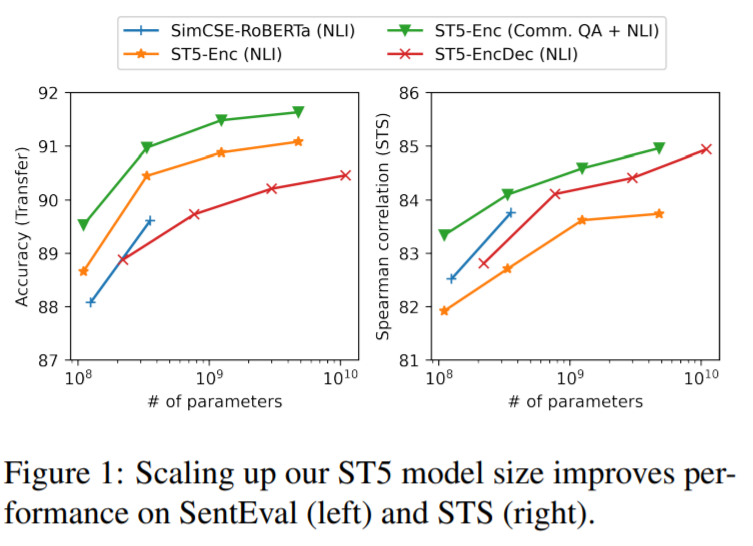
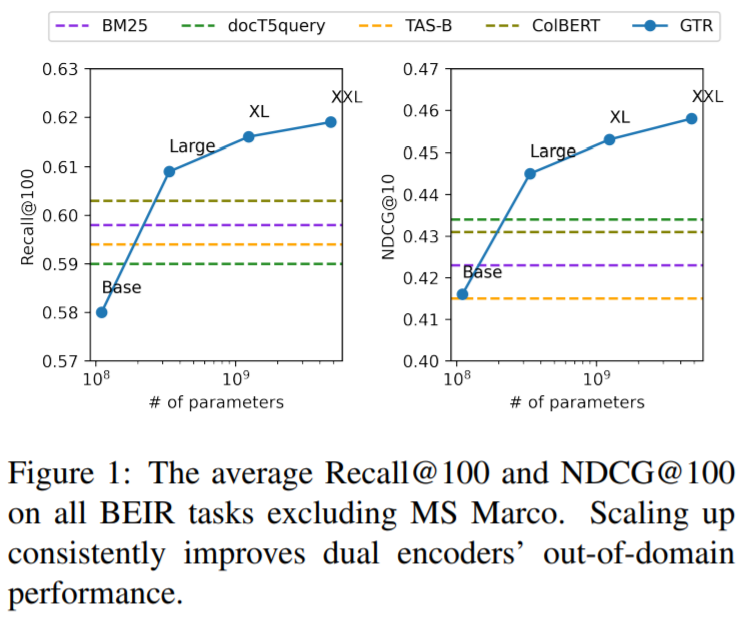
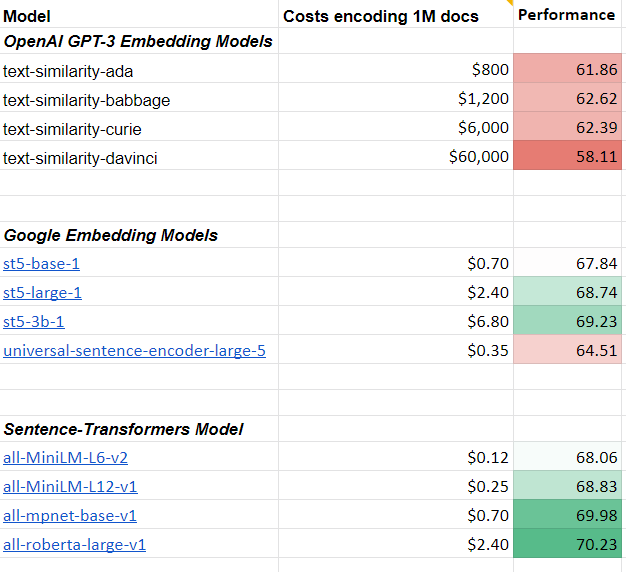
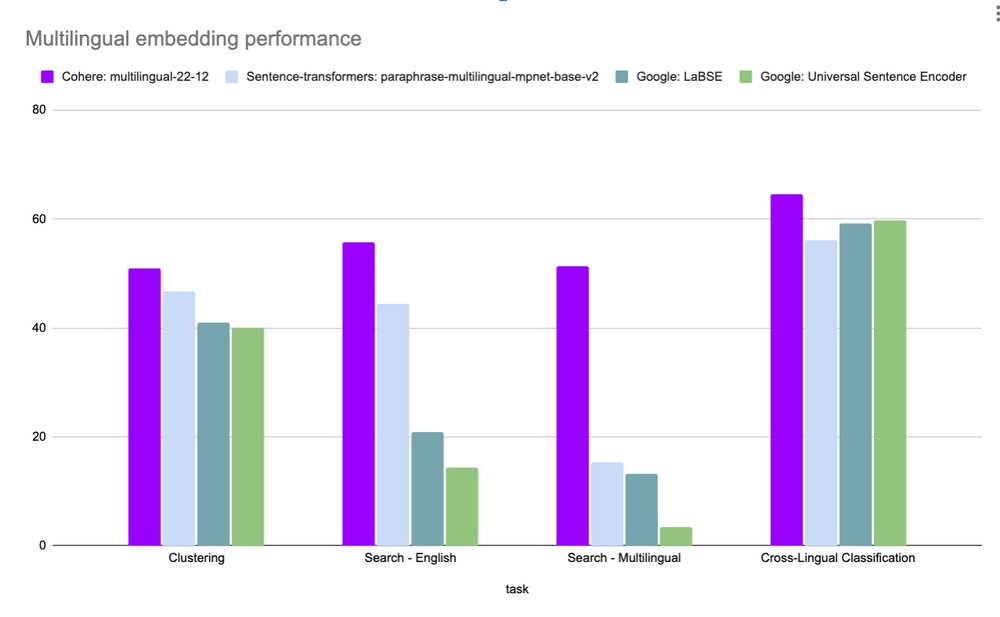
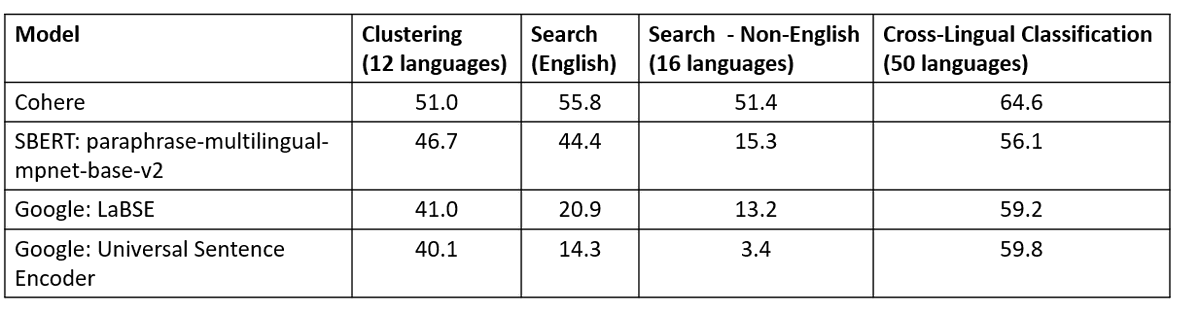
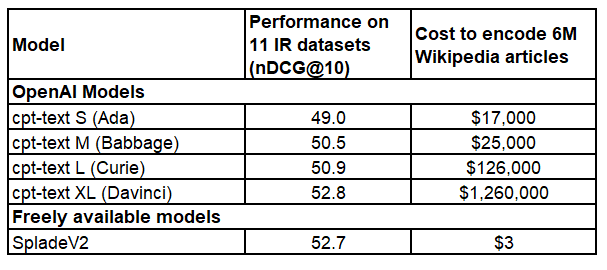 I tested the text similarity models on 14 datasets from different domains (emails, papers, online communities) on various tasks (clustering, retrieval, paraphrase mining).
I tested the text similarity models on 14 datasets from different domains (emails, papers, online communities) on various tasks (clustering, retrieval, paraphrase mining).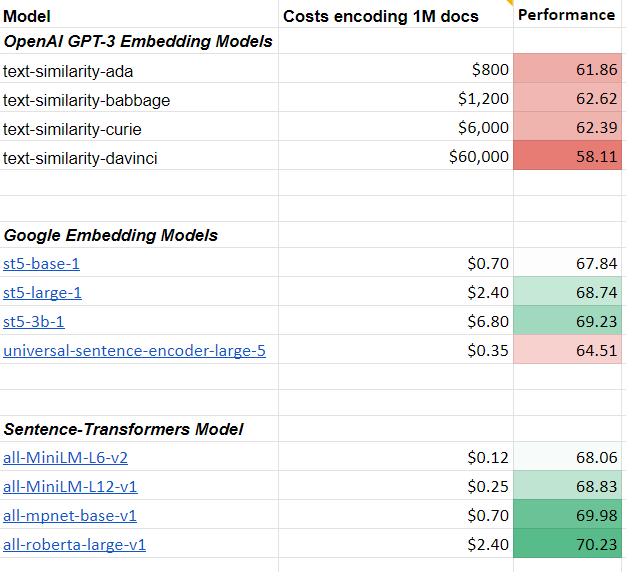
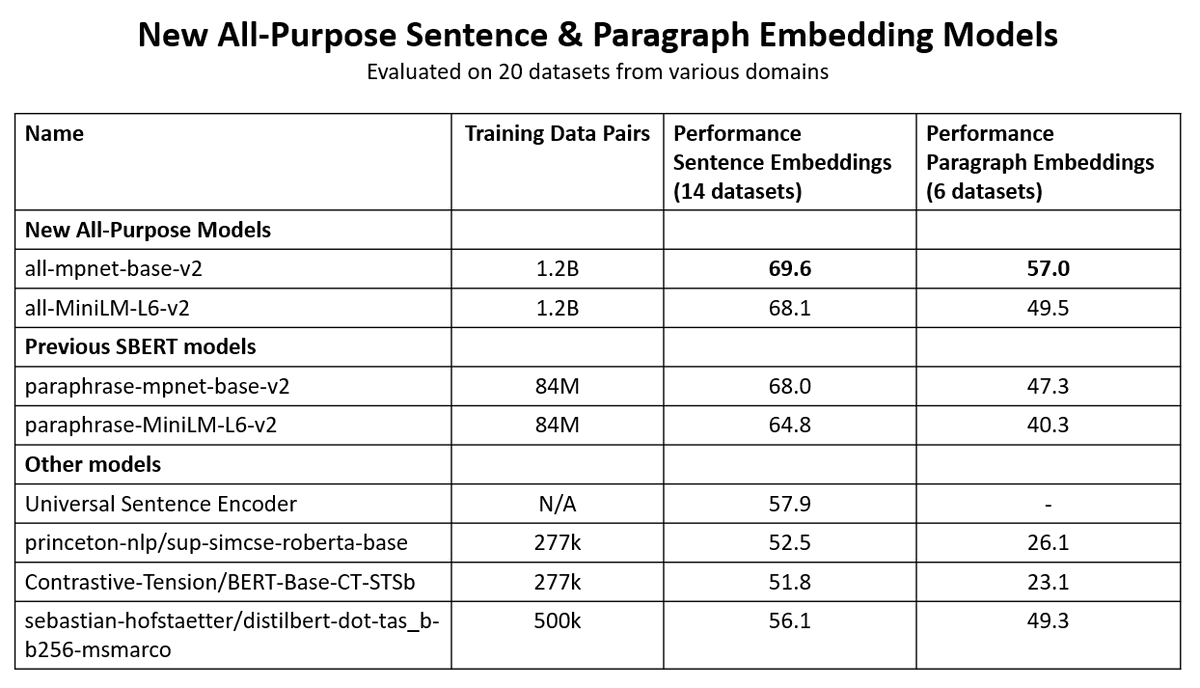
 🚨 All-Purpose Sentence & Paragraph Embeddings Models
🚨 All-Purpose Sentence & Paragraph Embeddings Models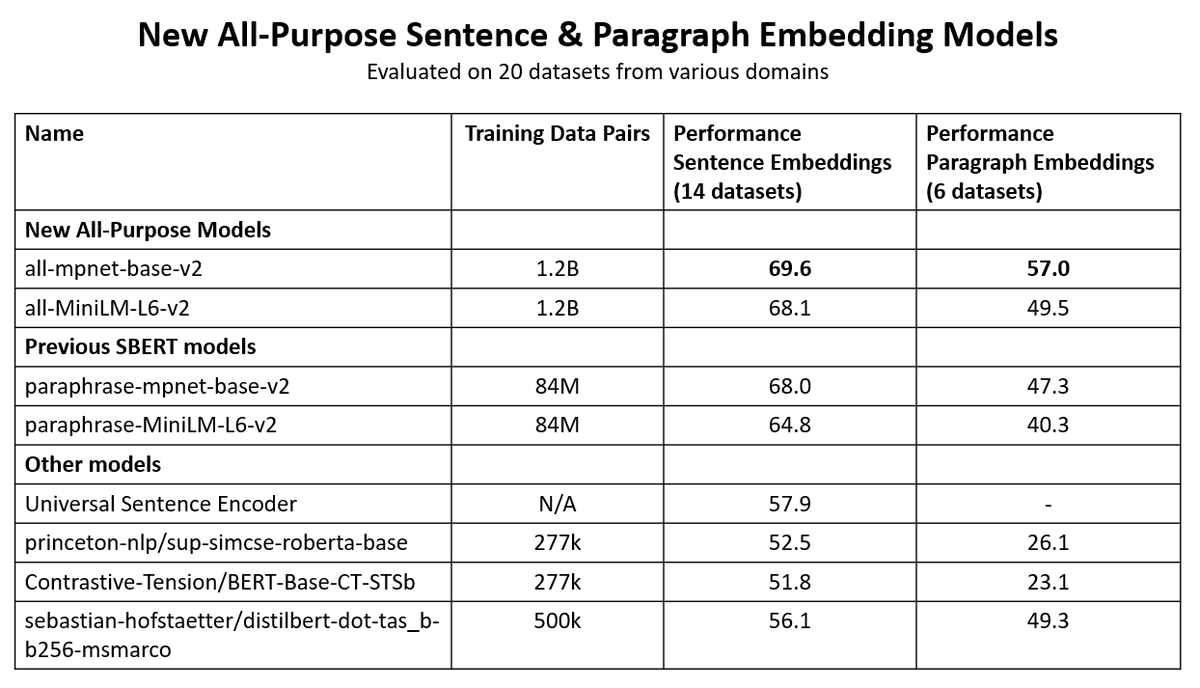
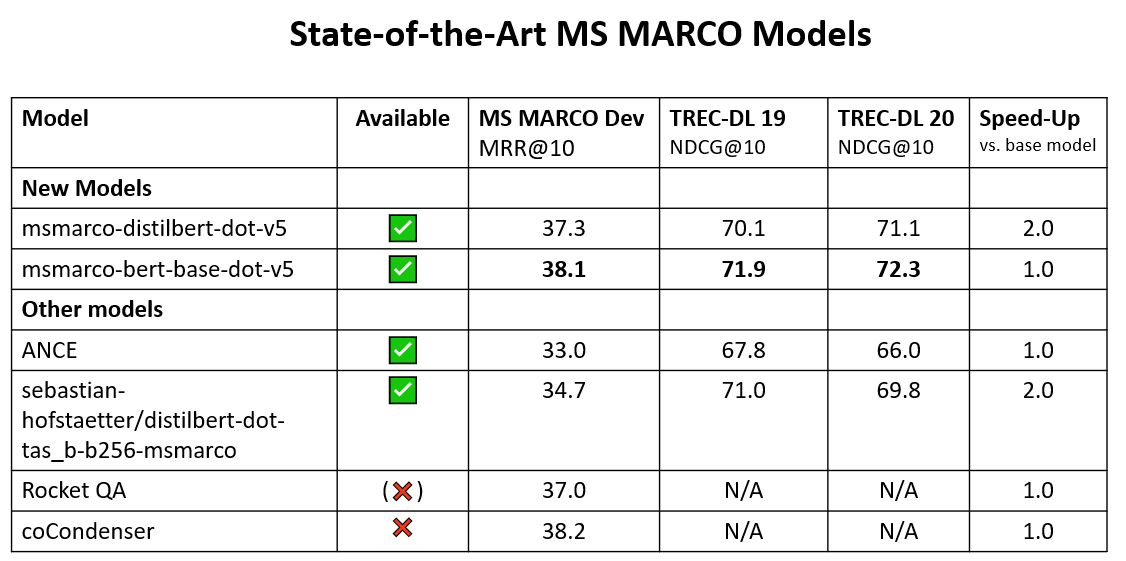
 Currently 4 state-of-the-art models are supported:
Currently 4 state-of-the-art models are supported: