AI engineer that takes companies from RAGs to riches
Aug 9, 2025 • 4 tweets • 2 min read
Apple just dropped a killer open-source visualization tool for embeddings — Embedding Atlas — and it’s surprisingly powerful for anyone working with large text+metadata datasets.
This reminds me of Nomic's Atlas, but I never got around to using it 😅
We’re talking real-time search, multi-million point rendering, and automatic clustering with labels.
One of their showcase examples visualizes ~200K wine reviews using embeddings + metadata like price, country, and tasting notes. And it is lightning fast even on my browser! No separate code needed!
It nails what most LLM devs need but often hack together:
✅ UMAP projections
✅ Faceted search across metadata (e.g. “country vs. price”)
✅ Hover + tooltip on raw points
✅ Interactive filters, histograms, and cluster overlays
✅ Cross-linked scatterplot + table views
Under the hood:
• Fast rendering using WebGPU (with WebGL fallback)
• Embedding-based semantic similarity search
• Kernel density contours for spotting clusters or outliers
You just upload your .jsonl or .csv with text + vector + metadata. It handles the rest: clustering, labeling, UI layout, everything.
This feels like the LLM-native version of Tableau — but optimized for text, chat and modern data needs
If you’re building RAG evals, search tuning, clustering explainability, or even dataset audits — this could be your new favorite tool. apple.github.io/embedding-atla…
Nov 5, 2023 • 8 tweets • 2 min read
6 Quick tips on doing RAG better:
1. Retrieval and ranking matter quite a lot:
1a) Chunking: Including section title in your chunks improves that, so does keywords from the documents
1b) Different token-efficient separators in your chunks e.g. ### is a single token in GPT
1c) Latency permitting — use a ReRanker — Cohere, Sentence Transformers and BGE have decent ones
1d) If you can, finetune the embedding to your domain — takes about 20 minutes on a modern laptop or Colab notebook, improves recall by upto 30-50%
Jun 28, 2023 • 5 tweets • 2 min read
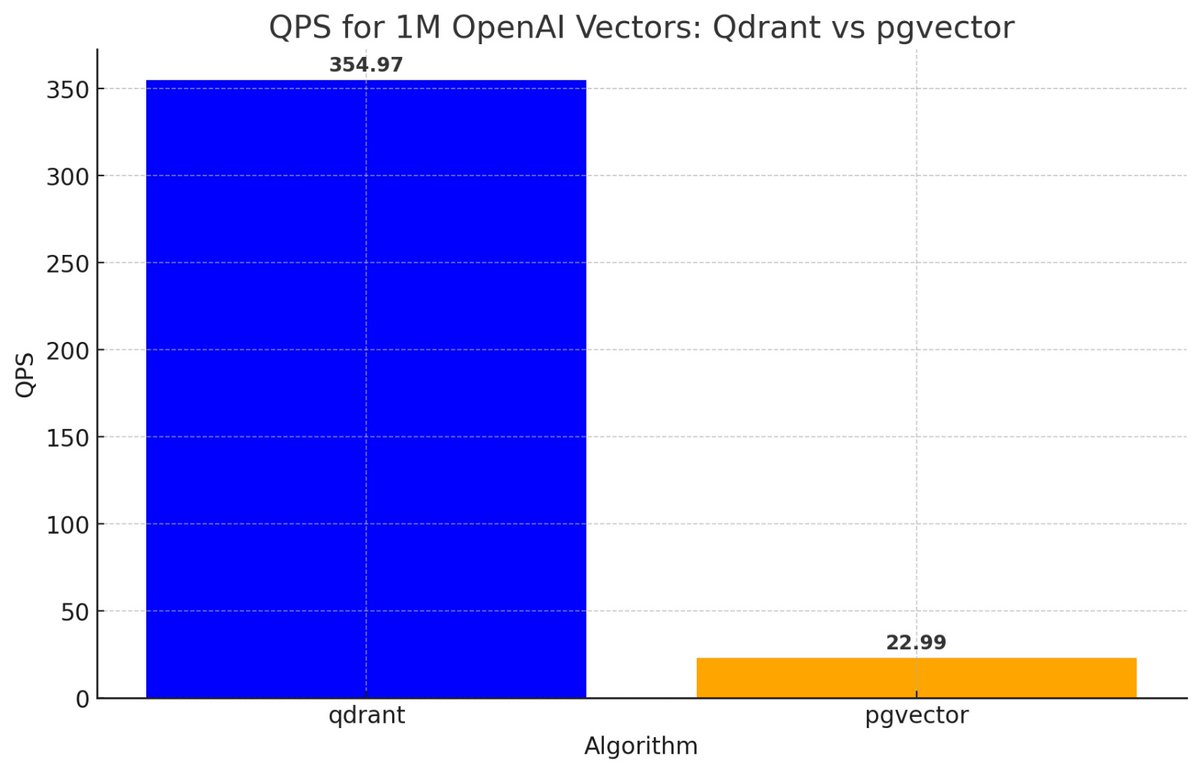
Why you should never use pgvector (e.g. @supabase Vector Store) for production:
😮 pgvector is 20x slower than a decent vector DB (e.g. @qdrant_engine)
🤯 And it's a full 18% worse in finding relevant docs for you
And this can happen at as little as 10K documents when chunked!
As a postgres fan, I am sad to see that pgvector not only starts at less than half the QPS at even 100K vectors — it dips really quickly beyond that.

 apple.github.io/embedding-atla…
apple.github.io/embedding-atla…