Research Fellow @ Kempner Institute, Harvard | Interested in AI interpretability, robustness & safety
Apr 13 • 11 tweets • 4 min read
New paper: LLMs encode harmful content generation in a distinct, unified mechanism
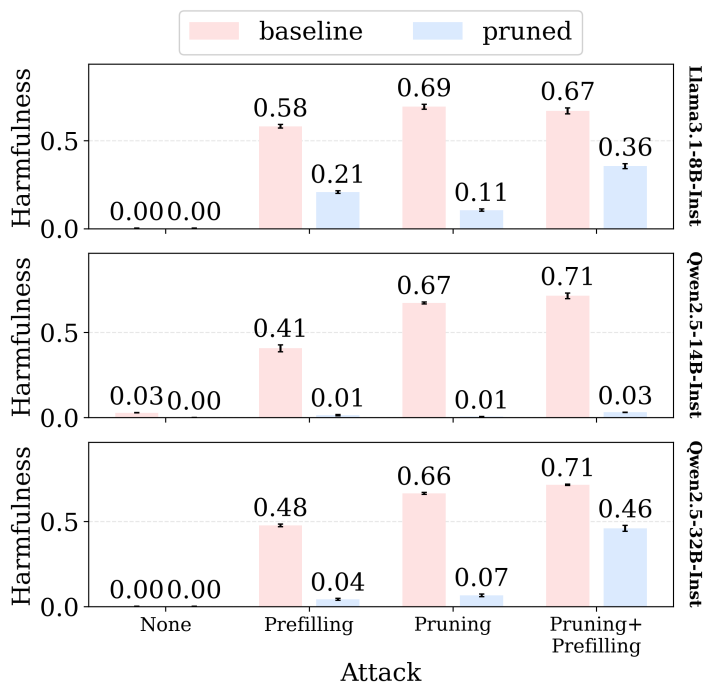
Using weight pruning, we find that harmful generation depends on a tiny subset of the weights that are shared across harm types and separate from benign capabilities.
🧵
Paper >>
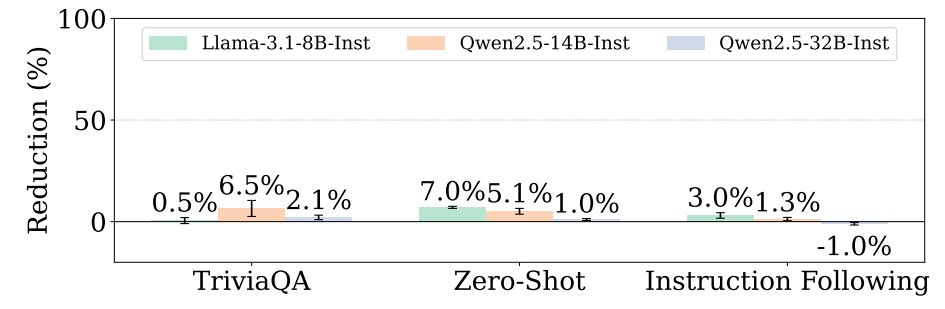
We use weight pruning to probe model internals.
Result: pruning ~0.0005% of model parameters, harmful generation drops dramatically, while general capabilities remain largely intact. arxiv.org/abs/2604.09544