
AI RS @ Meta TBD. On-Leave from Stanford w/ @sanmikoyejo. Prev @ Gemini, Meta, MIT, Harvard, Uber, UCL, UC Davis
 On Friday night, I gave 5 papers to Claude Opus 4.6 and GPT 5.2 Thinking on grokking, modular arithmetic, pattern formation, a theory of grid cells (note: I don't support this specific theory)
On Friday night, I gave 5 papers to Claude Opus 4.6 and GPT 5.2 Thinking on grokking, modular arithmetic, pattern formation, a theory of grid cells (note: I don't support this specific theory) @JoshuaK92829 @sanmikoyejo @Azaliamirh @jplhughes @jordanjuravsky @sprice354_ @aengus_lynch1 Large Language Monkeys & Best of N Jailbreaking discovered a striking finding:
@JoshuaK92829 @sanmikoyejo @Azaliamirh @jplhughes @jordanjuravsky @sprice354_ @aengus_lynch1 Large Language Monkeys & Best of N Jailbreaking discovered a striking finding: 
 The increasing presence of AI-generated content on internet raises critical question:
The increasing presence of AI-generated content on internet raises critical question:


 Predictable behavior from scaling AI systems is desirable. While scaling laws are well established, how *specific* downstream capabilities scale is significantly muddier eg. @sy_gadre @lschmidt3 @ZhengxiaoD @jietang
Predictable behavior from scaling AI systems is desirable. While scaling laws are well established, how *specific* downstream capabilities scale is significantly muddier eg. @sy_gadre @lschmidt3 @ZhengxiaoD @jietang

 Excited to announce our newest preprint!
Excited to announce our newest preprint!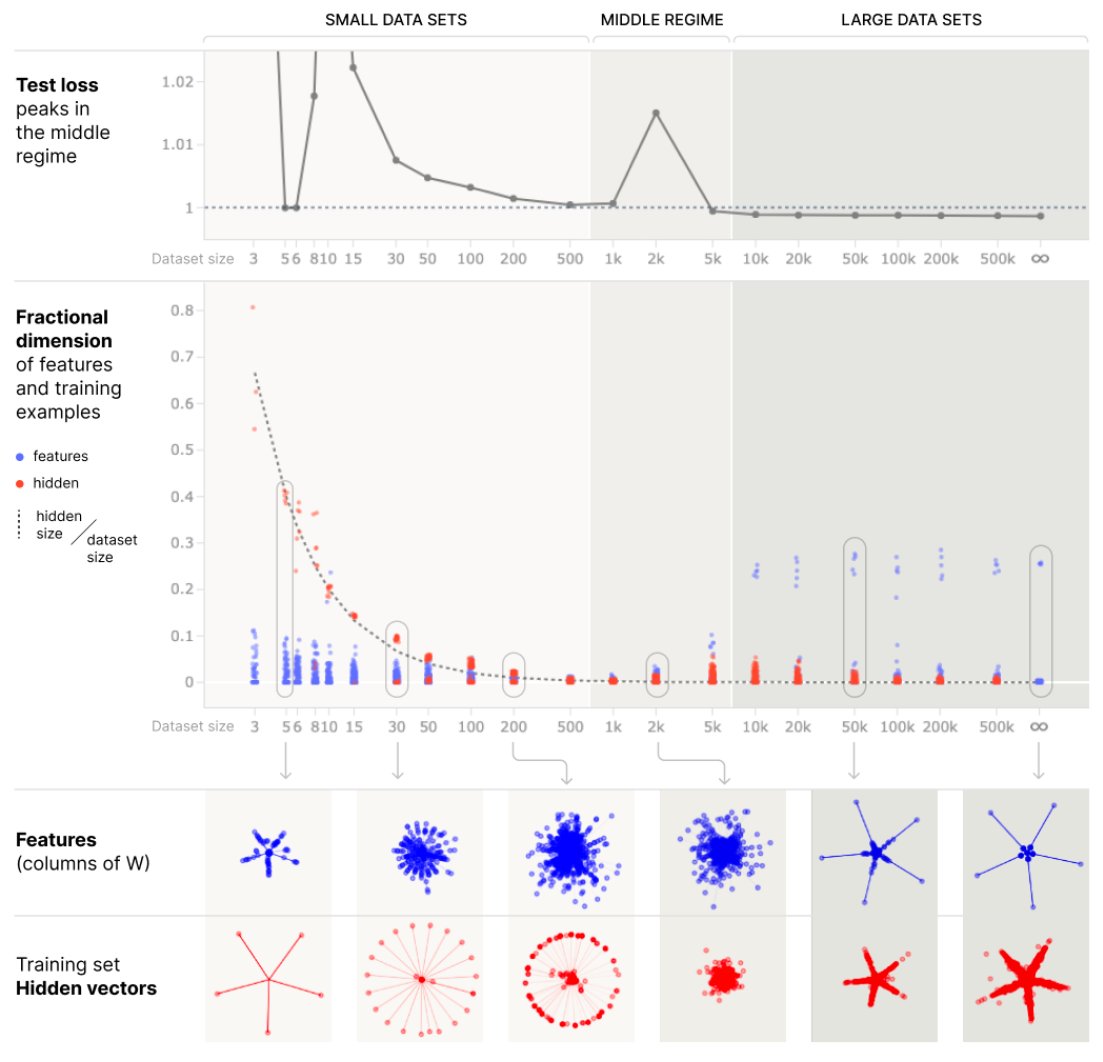 @SAIA_Alignment @AnthropicAI Prior work answers why double descent occurs, but we wanted an intuitive explanation that doesn’t require RMT or stat mech. Our new preprint identifies, interprets the **3** necessary ingredients for double descent, using ordinary linear regression!
@SAIA_Alignment @AnthropicAI Prior work answers why double descent occurs, but we wanted an intuitive explanation that doesn’t require RMT or stat mech. Our new preprint identifies, interprets the **3** necessary ingredients for double descent, using ordinary linear regression!
 @KhonaMikail @FieteGroup The promises of deep learning-based models of the brain are that they (1) shed light on the brain’s fundamental optimization problems/solutions, and/or (2) make novel predictions. We show, using deep network models of the MEC-HPC circuit, that one may get neither! 2/15
@KhonaMikail @FieteGroup The promises of deep learning-based models of the brain are that they (1) shed light on the brain’s fundamental optimization problems/solutions, and/or (2) make novel predictions. We show, using deep network models of the MEC-HPC circuit, that one may get neither! 2/15
 @AI_for_Science @KhonaMikail @FieteGroup The central promise of DL-based models of the brain are that they (1) shed light on the brain’s fundamental optimization problems/solutions, and/or (2) make novel predictions. We show, using DL models of grid cells in the MEC-HPC circuit, that one often gets neither 2/13
@AI_for_Science @KhonaMikail @FieteGroup The central promise of DL-based models of the brain are that they (1) shed light on the brain’s fundamental optimization problems/solutions, and/or (2) make novel predictions. We show, using DL models of grid cells in the MEC-HPC circuit, that one often gets neither 2/13