
I work on AI at OpenAI. Former VP AI and Distinguished Scientist at Microsoft.
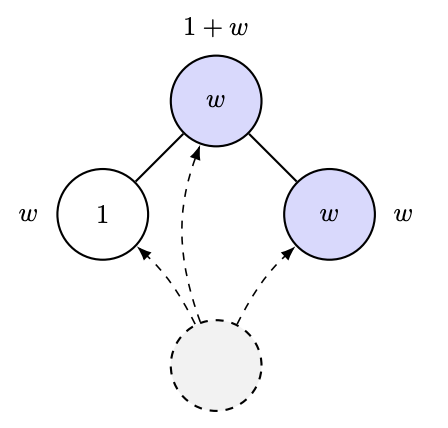
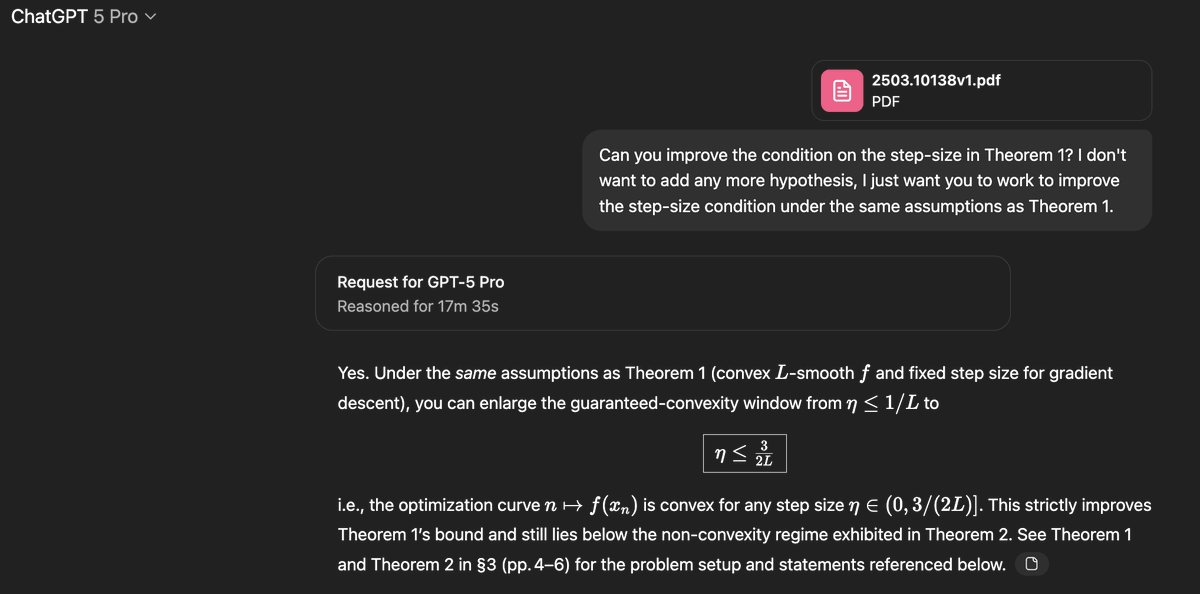 The paper in question is this one which studies the following very natural question: in smooth convex optimization, under what conditions on the stepsize eta in gradient descent will the curve traced by the function value of the iterates be convex?arxiv.org/pdf/2503.10138…
The paper in question is this one which studies the following very natural question: in smooth convex optimization, under what conditions on the stepsize eta in gradient descent will the curve traced by the function value of the iterates be convex?arxiv.org/pdf/2503.10138…
 Indeed it hits all the right things: the connection with self-contracted curves, the dimension-dependent bound, and even cites a relevant paper!
Indeed it hits all the right things: the connection with self-contracted curves, the dimension-dependent bound, and even cites a relevant paper!


 With my student extraordinaire Mark Sellke @geoishard, we prove a vast generalization of our conjectured law of robustness from last summer, that there is an inherent tradeoff between # neurons and smoothness of the network (see *pre-solution* video). 2/7
With my student extraordinaire Mark Sellke @geoishard, we prove a vast generalization of our conjectured law of robustness from last summer, that there is an inherent tradeoff between # neurons and smoothness of the network (see *pre-solution* video). 2/7