A thread of my favorite recent ultra small AI models that you can run locally (text, vision, speech, video) – most of them are <1B some up to 3-4B 👇
Running your small VLM in browser
Ok friends, it's weekend, we've some time for us. So let me tell you about a possible future for AI where the largest AI spendings, in billions of dollars, in 2-3 years would be on...
... antitrust legal fees
A quick 🧵1/8
let's go back to early 2000 – Microsoft was at that time the archenemy of the free and open source movements and the fight between OSS and private software was going strong
2/8
Dec 27, 2021 • 12 tweets • 4 min read
I read a lot of books this year to broaden my horizons in AI/ML with adjacent or complementary disciplines. It was a great pleasure so I’m sharing some my reading list here with a couple of notes:
[1/12]
P. Miller – Theories of Developmental Psychology
A great introduction to the major theoretical schools of child development
Orienting yourself in a field is easier when you’re familiar with a few important researchers & how each brought new views & approaches to the field
[2/12]
Dec 2, 2021 • 9 tweets • 3 min read
In 2021, we've seen an explosion of grounded Langage Models: from "image/video+text" to more embodied models in "simulation+text"
But, when tested on text benchmarks, these grounded models really struggle to improve over pure text-LM e.g T5/GPT3
Why?
>>
When we, humans, read sentences like "lemons are yellow" or "the dog is barking", we have the impression to recruit visual and auditory experiences.
Why then is it so difficult for grounded models to use multimodal inputs like we do to improve on text processing benchmarks?
>>
Sep 17, 2021 • 4 tweets • 2 min read
I'm not sure many people know how easy it is to share a dataset with the new versions of the @huggingface hub and Dataset library
In my view, this perception of large language models is mostly due to a narrative created by a few teams leveraging large language models as an instrument of power/showcase/business
In my view, these models:
Jan 14, 2020 • 8 tweets • 2 min read
I often meet research scientists interested in open-sourcing their code/research and asking for advice.
Here is a thread for you.
First: why should you open-source models along with your paper? Because science is a virtuous circle of knowledge sharing not a zero-sum competition 1. Consider sharing your code as a tool to build on more than a snapshot of your work:
-other will build stuff that you can't imagine => give them easy access to the core elements
-don't over-do it => no need for one-liner abstractions that won't fit other's need – clean & simple
May 3, 2019 • 9 tweets • 4 min read
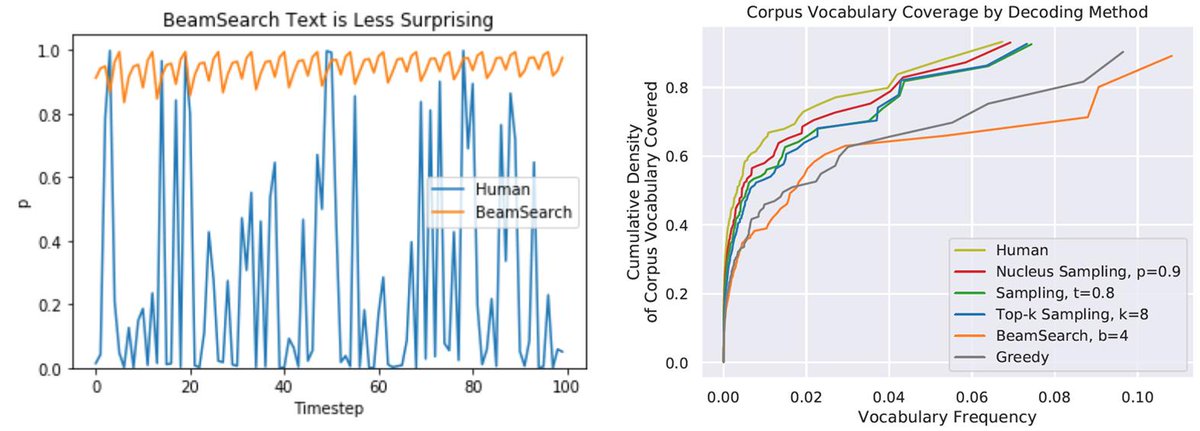
Interesting developments happened in 2018/2019 for natural language generation decoding algorithms: here's a thread with some papers & code
So, the two most common decoders for language generation used to be greedy-decoding (GD) and beam-search (BS). [1/9]
Greedy: at each time step, select the most likely next token according to the model until end of sequence. Risk: miss a high prob token hiding after a low-prob one.
Beam-search: to mitigate this, maintain a beam of sequences constructed word-by-word. Choose best at the end [2/9]