Can we simplify video generation by decomposing it into interleaved text-video co-generation?
Would explicit, repeated thinking in language improve generation in pixels?
We introduce TV2TV: a unified model that jointly learns
- language modeling (next-token prediction)
- video flow matching (next-frame prediction)
At inference, TV2TV dynamically alternates between textual thinking and video generation.
Model generations below: interleaved text plans and video slices (~1–2s) are co-generated over time, conditioned on a single frame per sport.
📖 arxiv.org/abs/2512.05103
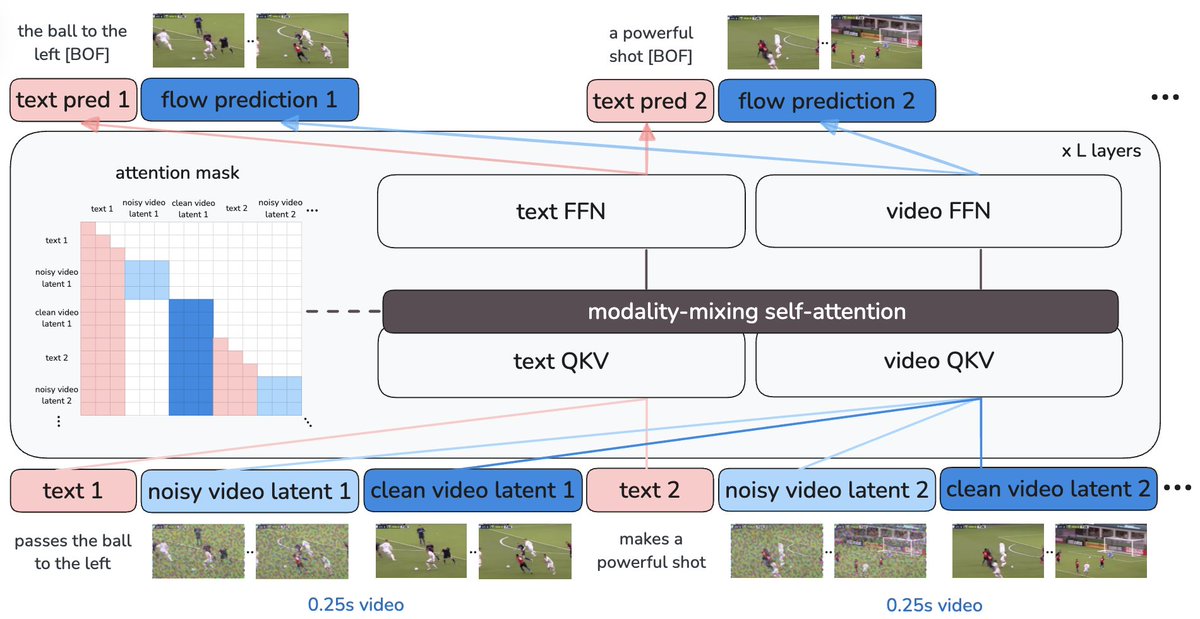
TV2TV builds on Transfusion, LMFusion, and mixture-of-Transformers, but goes further by enabling interleaved text-video co-generation in a single model. It models text autoregressively and video in short chunks semi-autoregressively (flow matching within ~0.25s clips, autoregressive globally). Each text token or video chunk attends to all previous text tokens and clean video chunks.