
Co-Founder @xAI. Minerva, STaR, AlphaGeometry, AlphaStar, Autoformalization, Memorizing transformer.
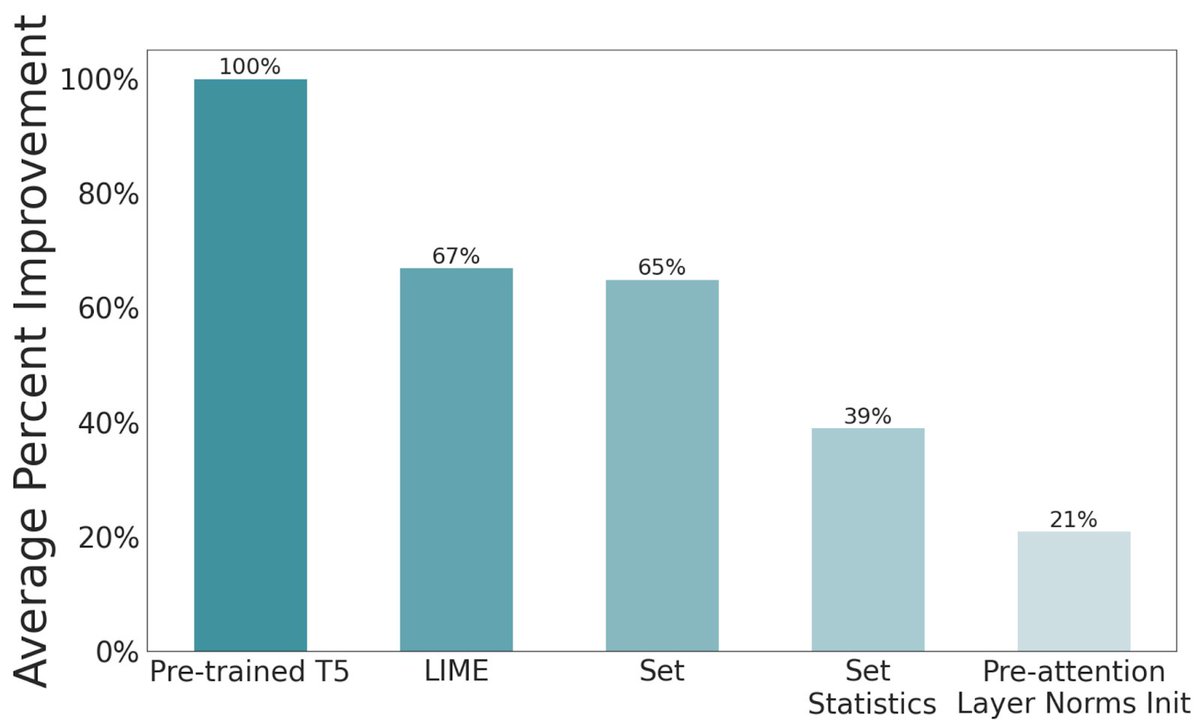 Nowadays, pre-training is ubiquitous in language, vision, audio, speech, RL etc.
Nowadays, pre-training is ubiquitous in language, vision, audio, speech, RL etc.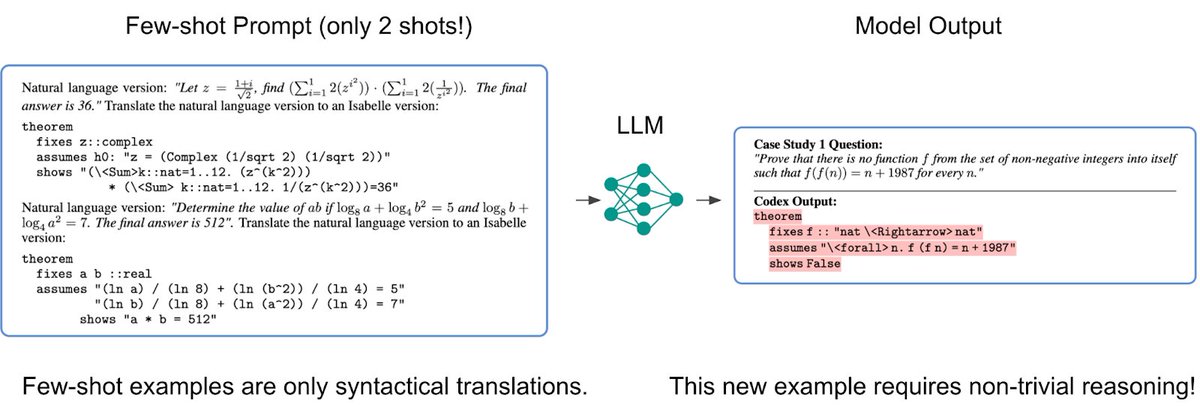
 We show two randomly chosen few-shot examples in the prompt, from latex to formal math (Isabelle). Note that these two examples are merely examples of syntactical translations, without much sophistication in reasoning or natural language understanding.
We show two randomly chosen few-shot examples in the prompt, from latex to formal math (Isabelle). Note that these two examples are merely examples of syntactical translations, without much sophistication in reasoning or natural language understanding.
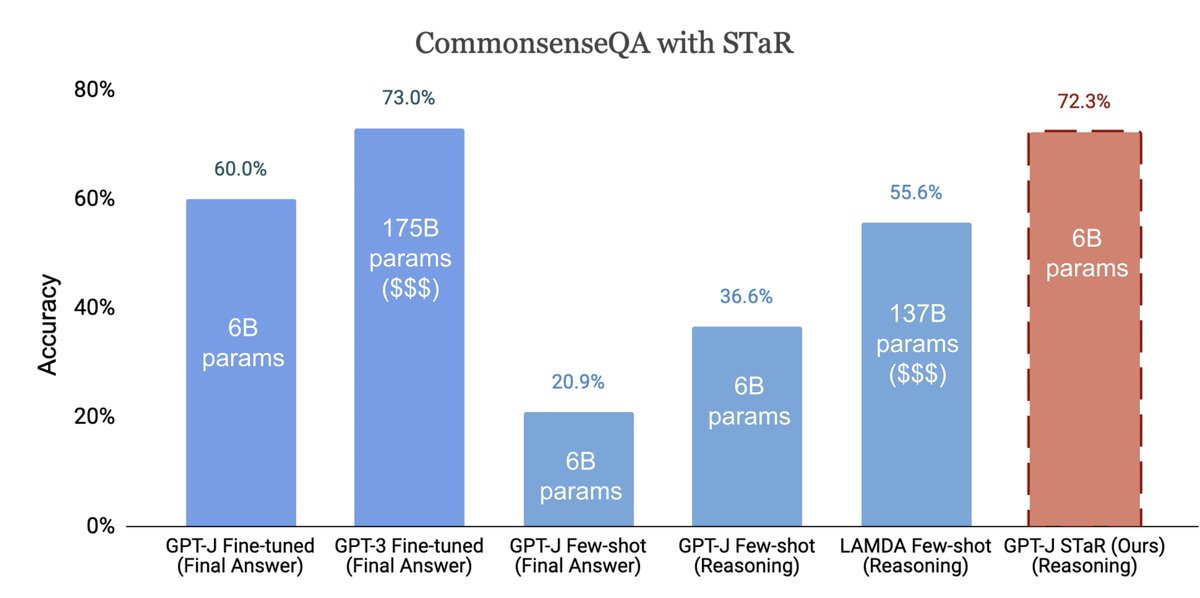 @ericzelikman Human reasoning is often the result of extended chains of thought.
@ericzelikman Human reasoning is often the result of extended chains of thought. 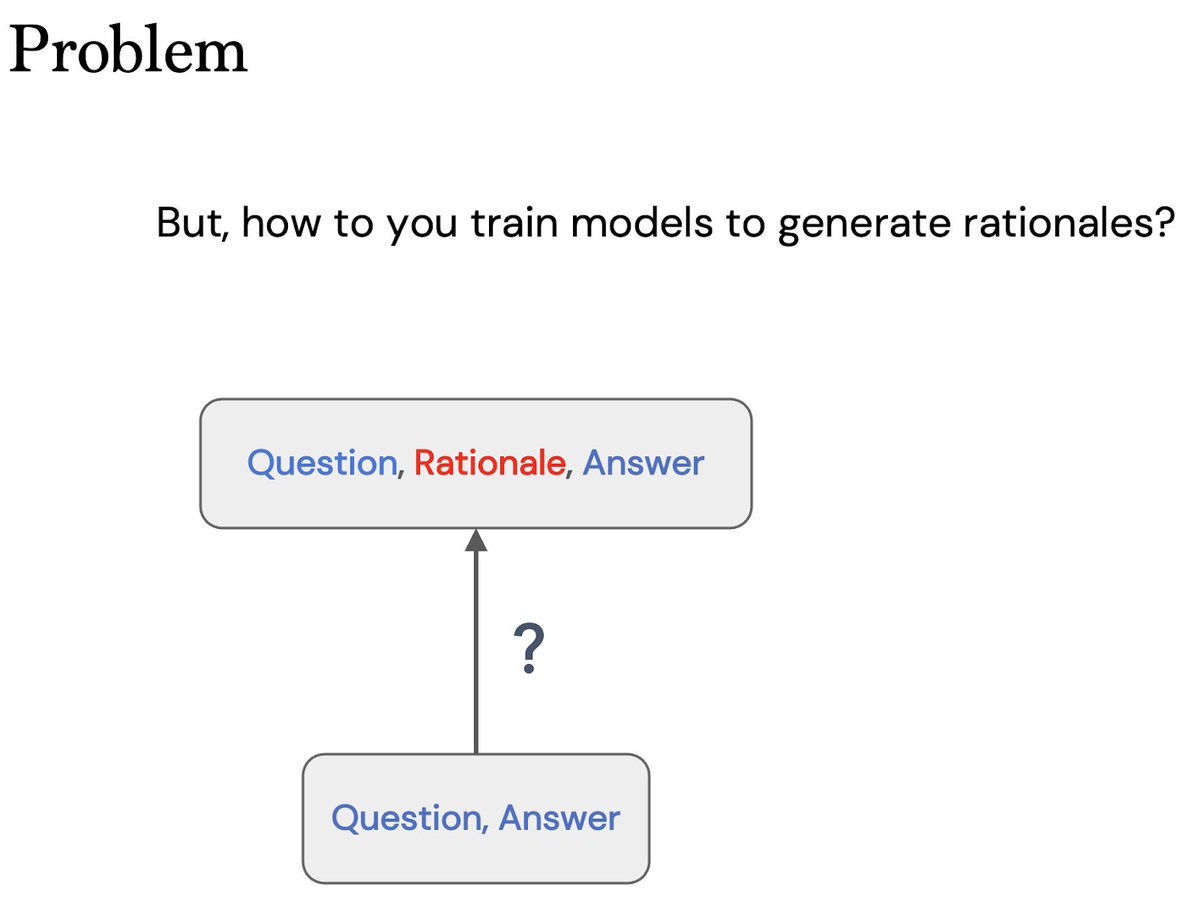
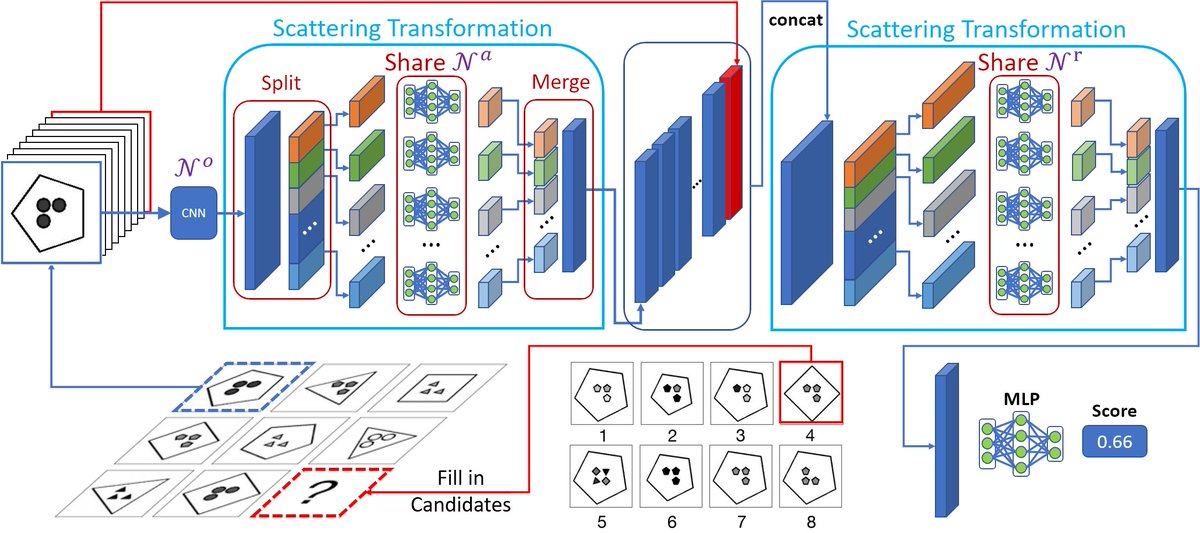 SCL is designed to discover the compositional structures of the data. In RAVEN, It learns to discover the compositions of objects, attributes, and relationships. The figure shows an example where SCL learns the concept of “size”.
SCL is designed to discover the compositional structures of the data. In RAVEN, It learns to discover the compositions of objects, attributes, and relationships. The figure shows an example where SCL learns the concept of “size”.