
Senior Research Scientist at DeepMind. Intrinsically motivated to research intrinsic motivation. All opinions my own.
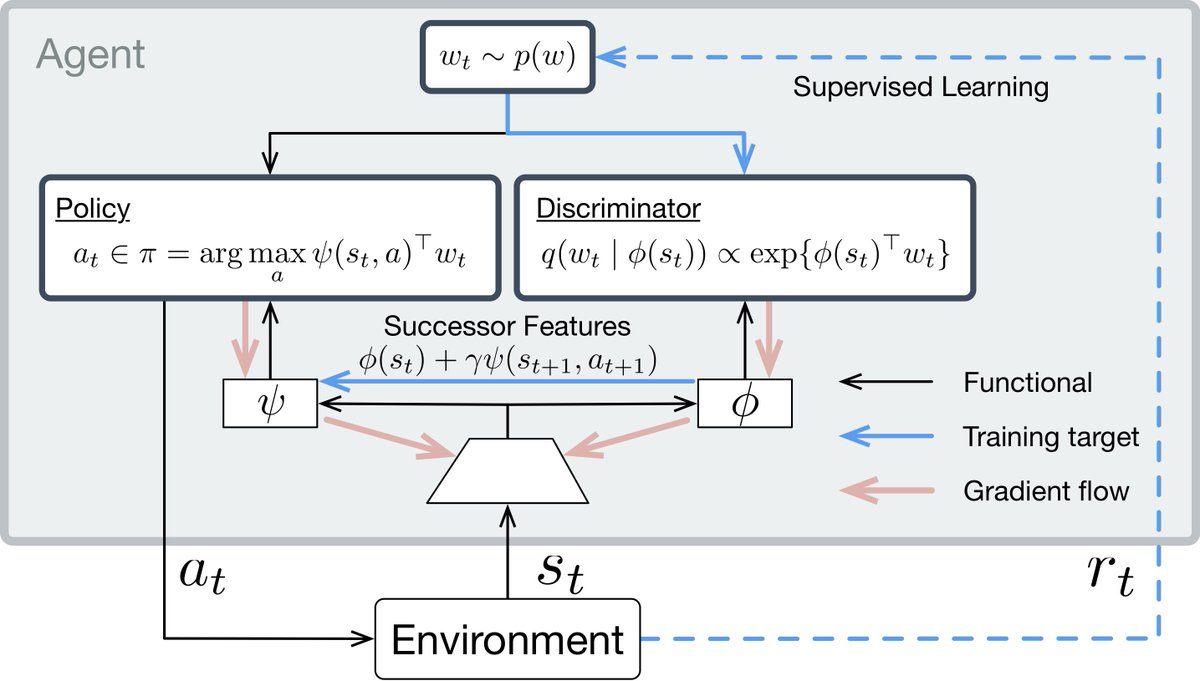 Imagine that unsupervised interaction is free/cheap, but evaluating the reward function isn't. We formalize this as a 2 phase training regime:
Imagine that unsupervised interaction is free/cheap, but evaluating the reward function isn't. We formalize this as a 2 phase training regime: