
Member of Technical Staff at Thinking Machines. Human+AI collaboration. Scalable Oversight. Explainability. Prev @AnthropicAI PhD UC Berkeley'25; Columbia'19
 We propose the D5 task – goal driven discovery of distributional differences via language descriptions.
We propose the D5 task – goal driven discovery of distributional differences via language descriptions. 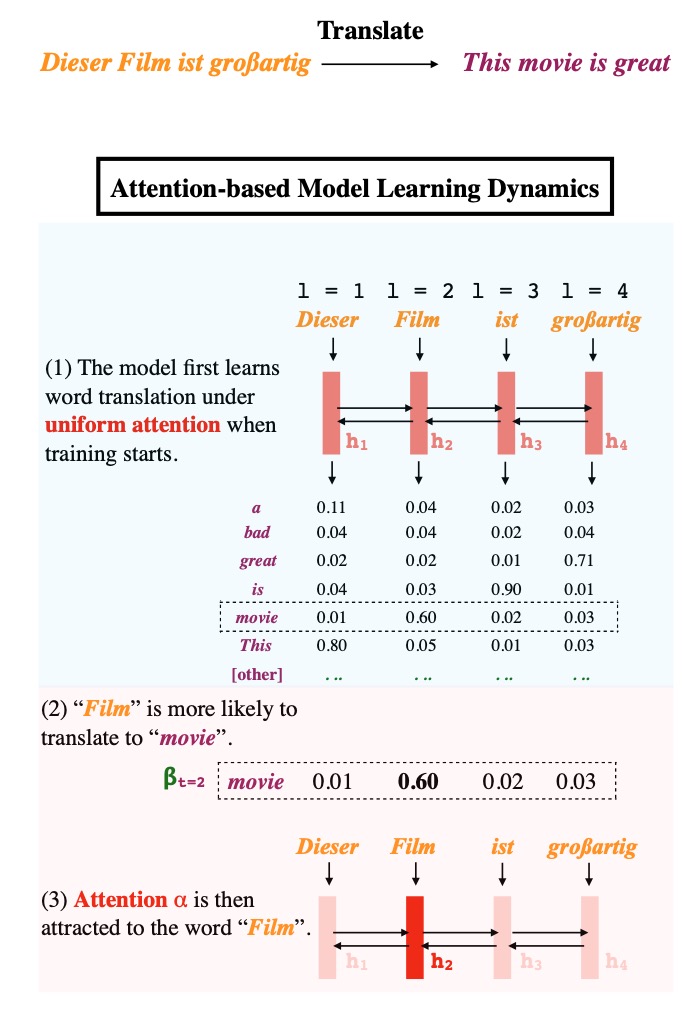 We approximate with 2 stages: early in training when attentions are uniform, the model learns to translate individual input word `i` to `o` if they co-occur frequently. Later, the model learns to attend to `i` while the correct output is o because it knows `i` translates to `o`.
We approximate with 2 stages: early in training when attentions are uniform, the model learns to translate individual input word `i` to `o` if they co-occur frequently. Later, the model learns to attend to `i` while the correct output is o because it knows `i` translates to `o`.
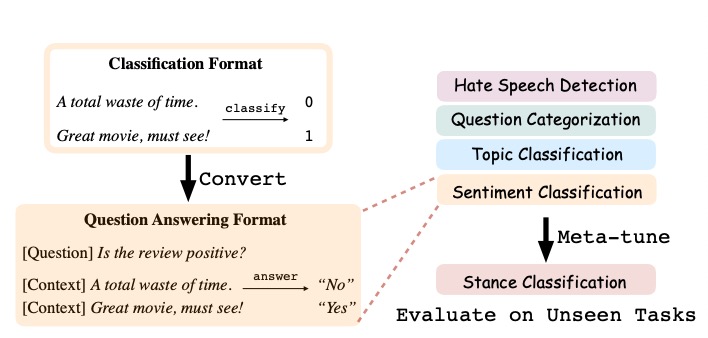 1. Prompting a language model out of the box can be highly suboptimal. For example, GPT-3 (175B parameters) gets 80% on SST-2 zero-shot, while UnifiedQA (700M) get 92% 🤔 so even being adapted to generic question answering can make a 200x smaller model better ...
1. Prompting a language model out of the box can be highly suboptimal. For example, GPT-3 (175B parameters) gets 80% on SST-2 zero-shot, while UnifiedQA (700M) get 92% 🤔 so even being adapted to generic question answering can make a 200x smaller model better ...