
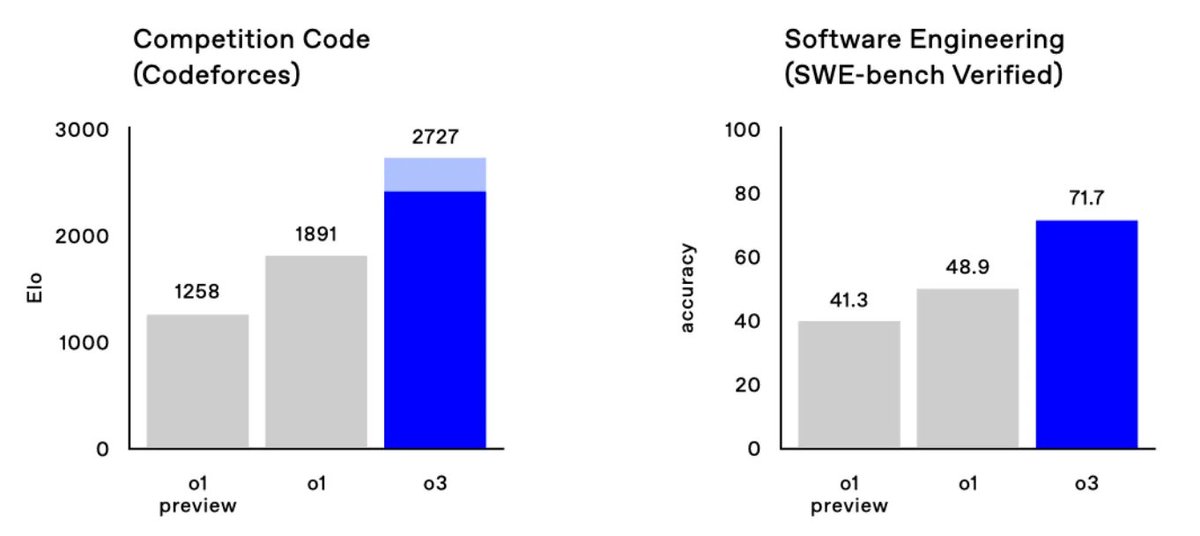
 o1 was the first large reasoning model — as we outlined in the original “Learning to Reason” blog, it’s “just” an LLM trained with RL. o3 is powered by further scaling up RL beyond o1, and the strength of the resulting model the resulting model is very, very impressive. (2/n)
o1 was the first large reasoning model — as we outlined in the original “Learning to Reason” blog, it’s “just” an LLM trained with RL. o3 is powered by further scaling up RL beyond o1, and the strength of the resulting model the resulting model is very, very impressive. (2/n)
 Models should use what they have learned in the past to pick the most informative things to learn in the future. This has proved surprisingly tricky so far with naive exploration common in RL, and many AL methods failing to make the most of pre-trained models. (2/n)
Models should use what they have learned in the past to pick the most informative things to learn in the future. This has proved surprisingly tricky so far with naive exploration common in RL, and many AL methods failing to make the most of pre-trained models. (2/n)