
Research scientist @valeoai | Teaching @Polytechnique @ENS_ULM | Alumni @upb1818 @Mines_Paris @Inria @ENS_ULM | Feedback: https://t.co/MHAm0ClqFJ
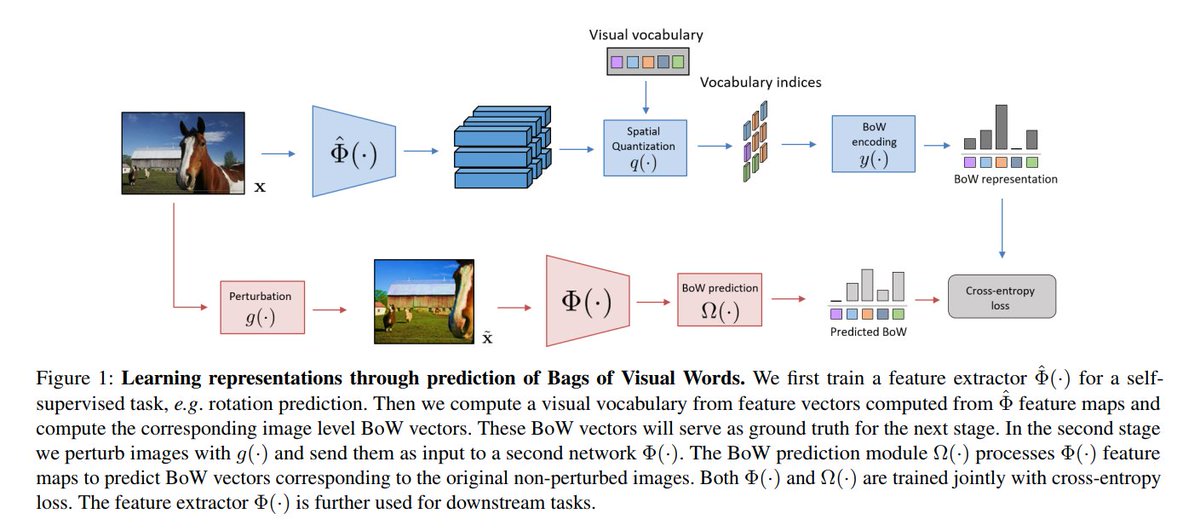 @quobbe Inspired by NLP approaches, our method builds upon features from a self-supervised CNN (e.g. RotNet), which are used for computing a codebook of visual words and image-level Bag-of-Words (BoW) representations 2/
@quobbe Inspired by NLP approaches, our method builds upon features from a self-supervised CNN (e.g. RotNet), which are used for computing a codebook of visual words and image-level Bag-of-Words (BoW) representations 2/ 
