
Blue collar financial economist (codes, debugs, daily) @federalreserve. Ph.D. @FisherOSU. https://t.co/d4vMeEAZZy. Views are my own.
 There's a reason for the sacred cow. Post-hoc theorizing leads to overfitted ideas. As a result,
There's a reason for the sacred cow. Post-hoc theorizing leads to overfitted ideas. As a result,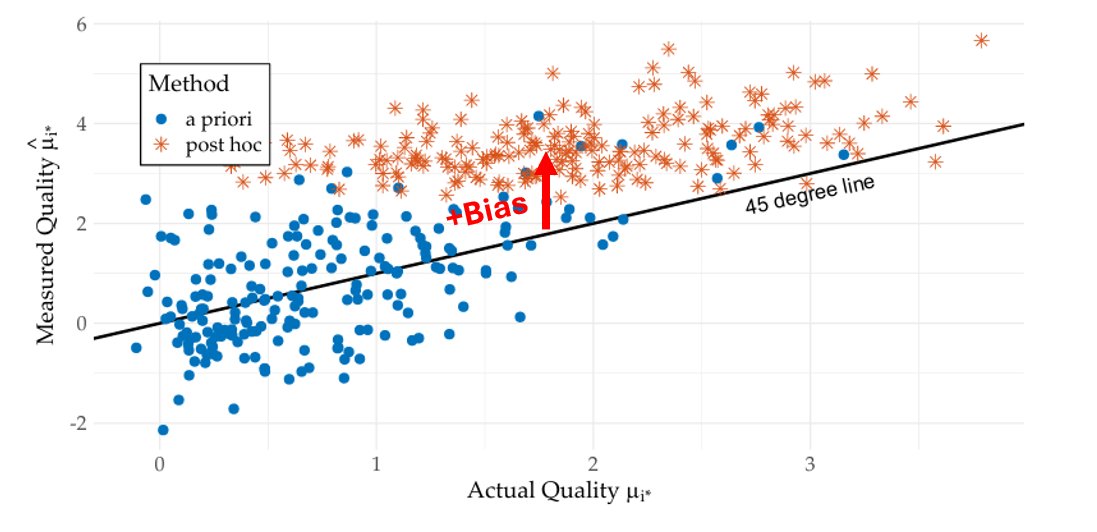

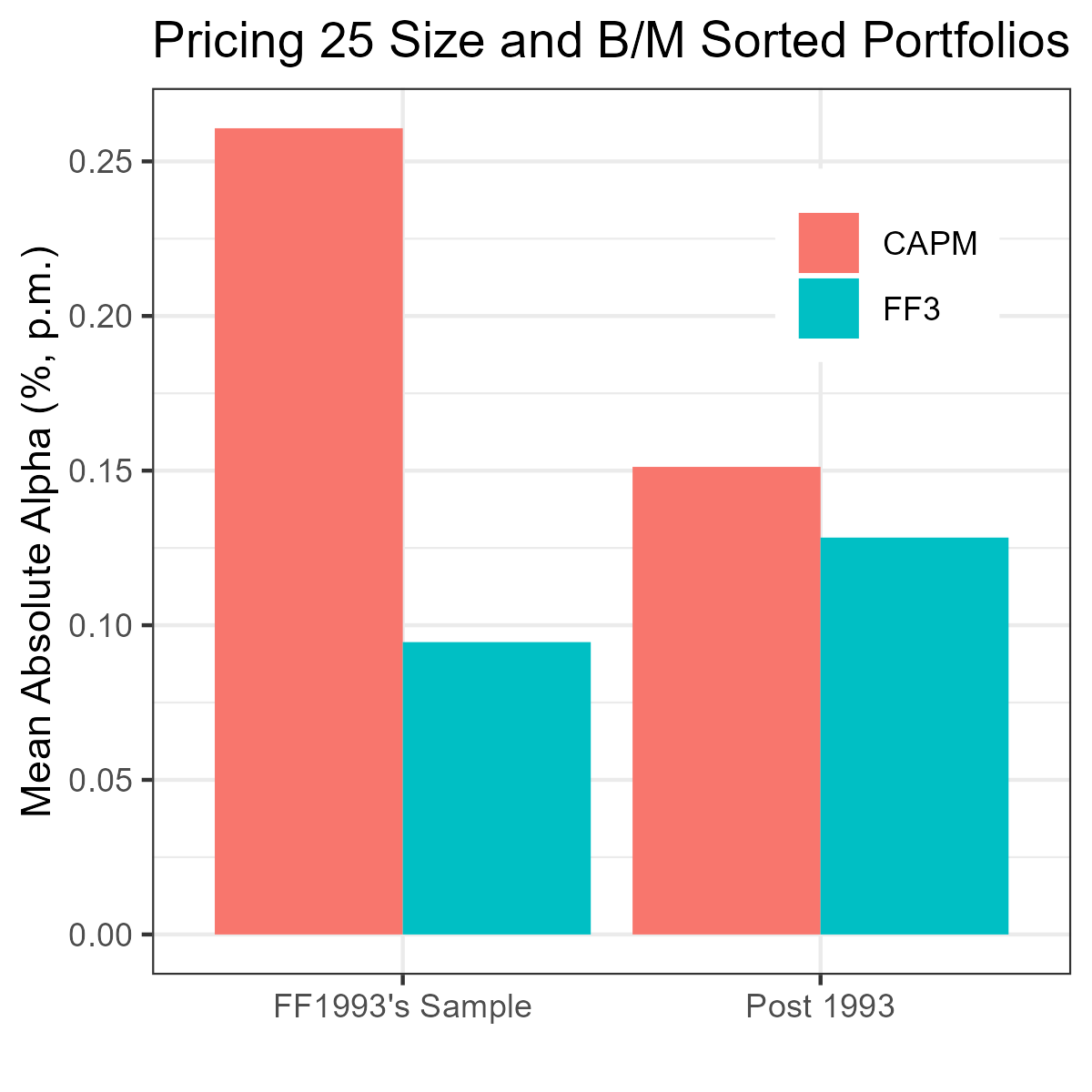 FF's size and value factors are not beautiful nor theoretically well-founded. And they fail to explain most anomalies. But they are supposed to provide an improved empirical description of, well, **size and value sorted portfolios**!! I guess they did, until 1993.
FF's size and value factors are not beautiful nor theoretically well-founded. And they fail to explain most anomalies. But they are supposed to provide an improved empirical description of, well, **size and value sorted portfolios**!! I guess they did, until 1993.
 How can you stop worrying and ❤️ data mining? You can if you do a good job!---if you mine data *rigorously*. We demonstrate by mining 73,108 long-short strategies based on accounting, past returns, and ticker symbol data using empirical Bayes shrinkage.
How can you stop worrying and ❤️ data mining? You can if you do a good job!---if you mine data *rigorously*. We demonstrate by mining 73,108 long-short strategies based on accounting, past returns, and ticker symbol data using empirical Bayes shrinkage.
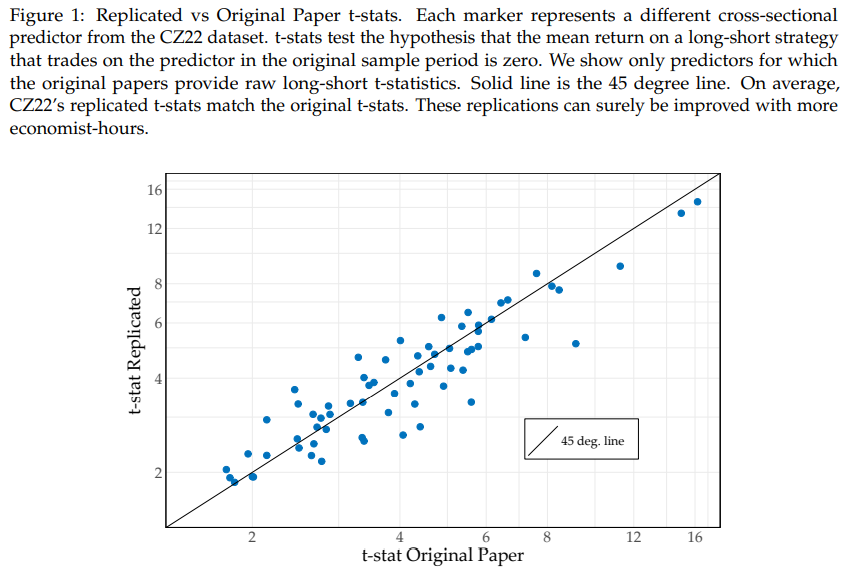
 2/5 I was taught that expected returns are high in recessions. In recessions, risk is high, so returns are high. My JMP (and first pub) is a quantitative GE model of this fundamental idea.
2/5 I was taught that expected returns are high in recessions. In recessions, risk is high, so returns are high. My JMP (and first pub) is a quantitative GE model of this fundamental idea.
