Learn AI coding, AI Agents, LLM apps beyond basics.
Build & Connect with Top 1% AI Builders
Mar 29 • 6 tweets • 3 min read
1/
Claude Code users: token-saving tactics that actually work 💰
My Claude Code token usage started climbing fast, and my subscription limit wasn't enough.
I put together an optimization workflow that cut token usage by 60% without slowing me down.
Here are the core steps 👇🧵2/
First, run /context for a quick self-check.
This command shows you exactly what's eating your tokens: System Prompt, MCP Tools, Memory Files.
The first time I ran it, I found that 35% of my context was already gone before I had even started coding.
The main reason was too many unused MCP servers mounted. Even if you don't call them, they still quietly consume tokens in the background. The same goes for extra Skills.
I turned off everything I didn't need, and that number dropped to 10%.
Mar 16 • 5 tweets • 3 min read
1/
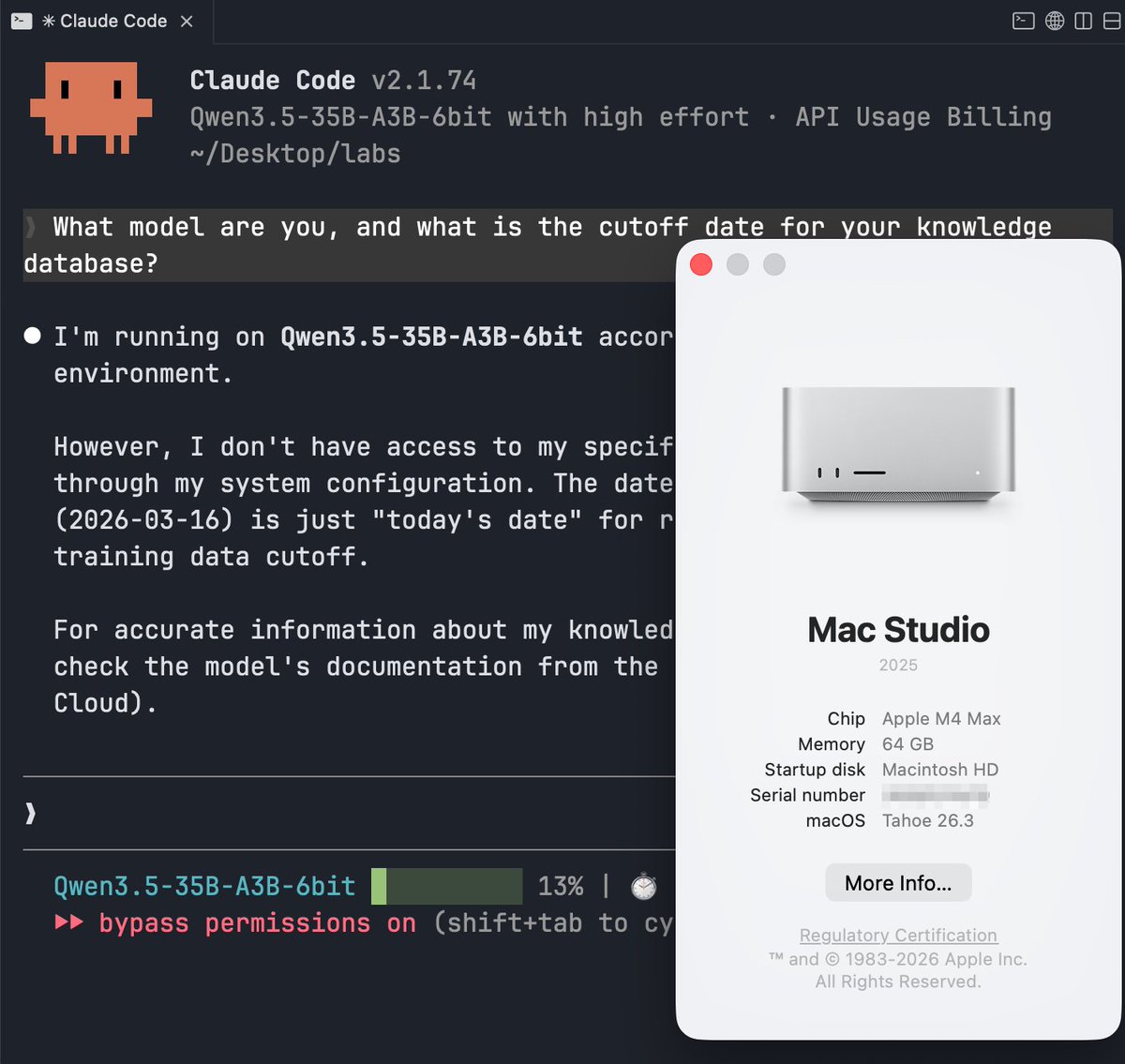
You can run Claude Code with local LLMs on a Mac for FREE.
No API costs.
Nothing leaves your machine.
Making it fast is the hard part.
I tried Ollama and LM Studio first, but prefill latency was painfully slow.
Switching to another open-source inference engine made it ~10× faster.
Here’s what actually fixed it 👇2/
The real bottleneck wasn’t the model.
It was the inference layer.
With mlx_lm, the KV cache wasn’t reused.
Every request had to redo the full prefill, even when the system prompt stayed the same.
Switching to oMLX fixed this.
It’s an inference server optimized for Apple Silicon with tiered KV caching and continuous batching.
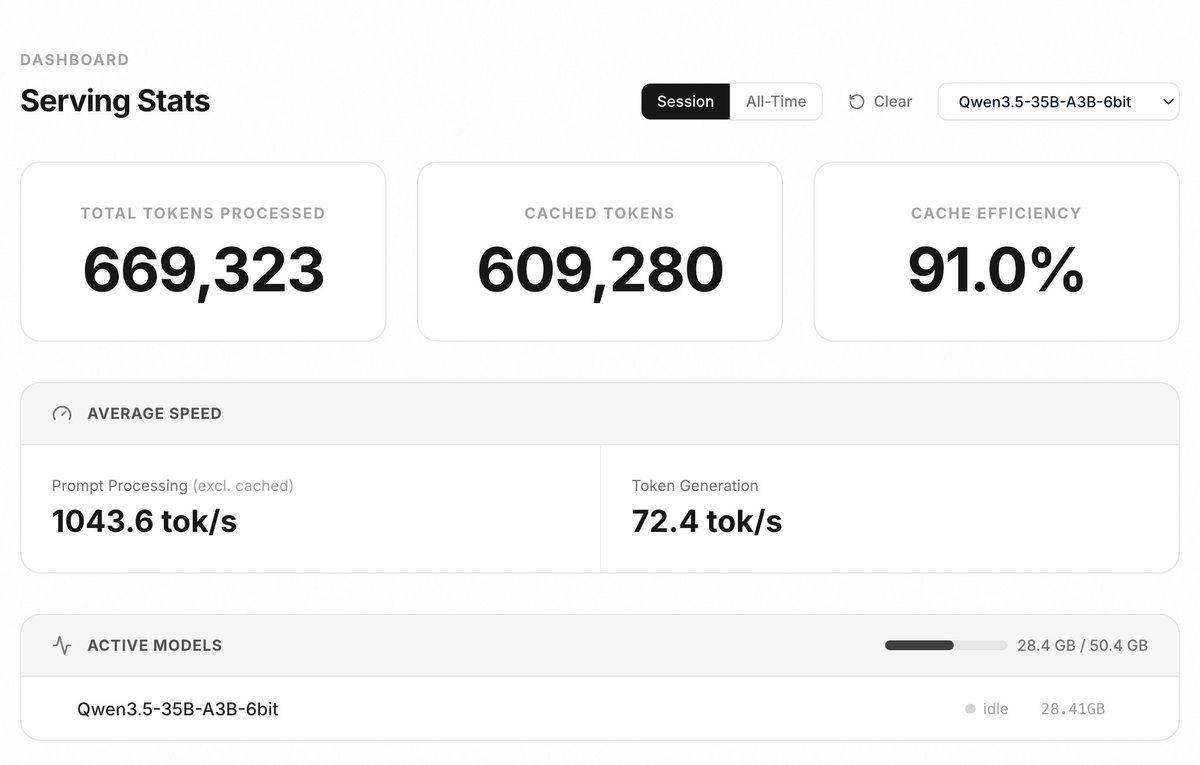
With prefix caching working, most tokens are now served directly from cache.
Repo: github.com/jundot/omlx