
 two quick things outta the way:
two quick things outta the way:  aidanbench was at neurips; we re-wrote the entire benchmark and made new questions (still work to do!)
aidanbench was at neurips; we re-wrote the entire benchmark and made new questions (still work to do!)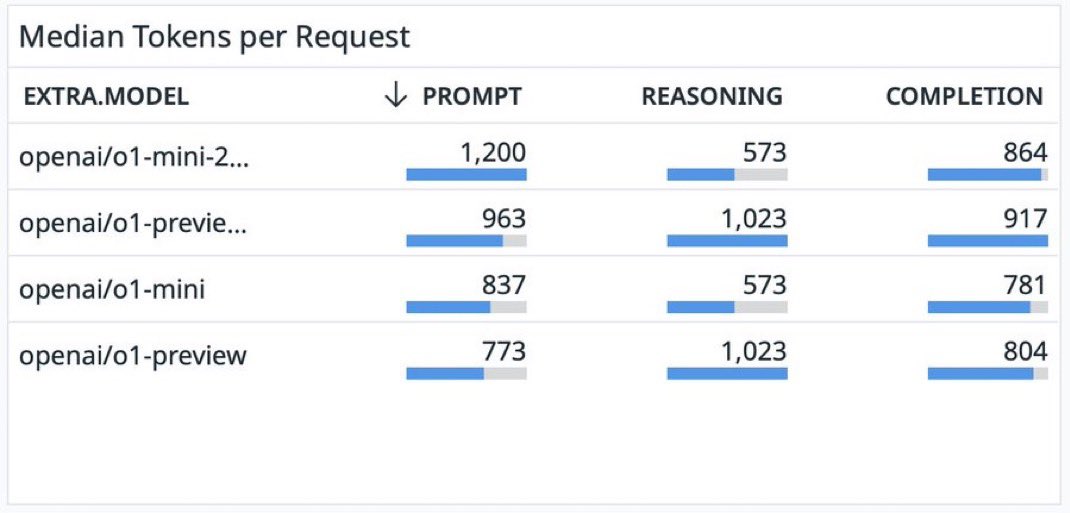 openrouter released recent data on o1 tokens spent on reasoning vs response
openrouter released recent data on o1 tokens spent on reasoning vs response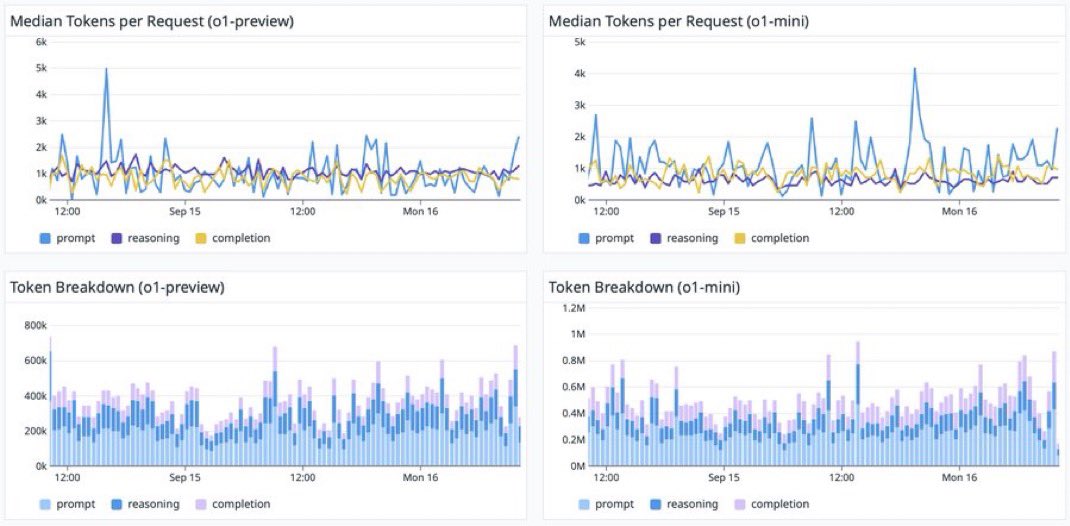
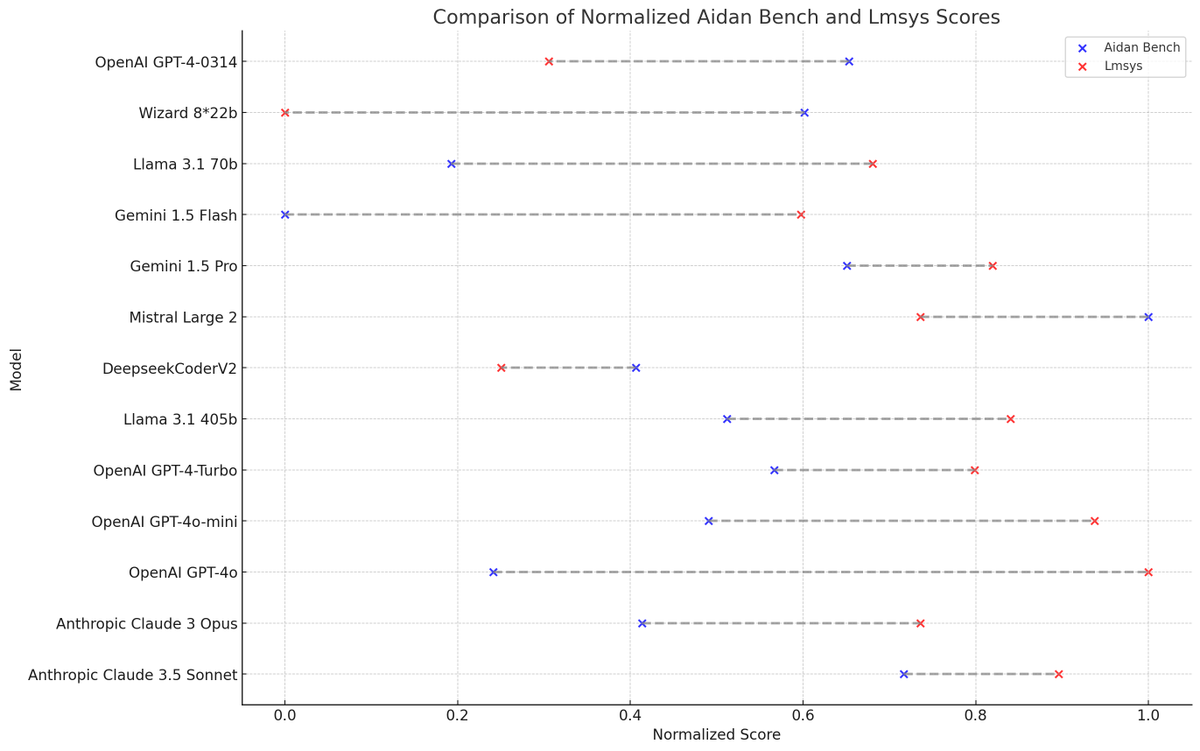
 notably, Aidan Bench scores are largely uncorrelated with Lmsys scores.
notably, Aidan Bench scores are largely uncorrelated with Lmsys scores.
 LLMs are stateless.
LLMs are stateless. 
 nobody admits this because we're all suffering from "no-adults-in-the-room-ism"
nobody admits this because we're all suffering from "no-adults-in-the-room-ism"