
 Indeed, imagine choosing 5% of the cat images in ImageNet training set, and superimposing synthetically generated hats on top of them.
Indeed, imagine choosing 5% of the cat images in ImageNet training set, and superimposing synthetically generated hats on top of them.
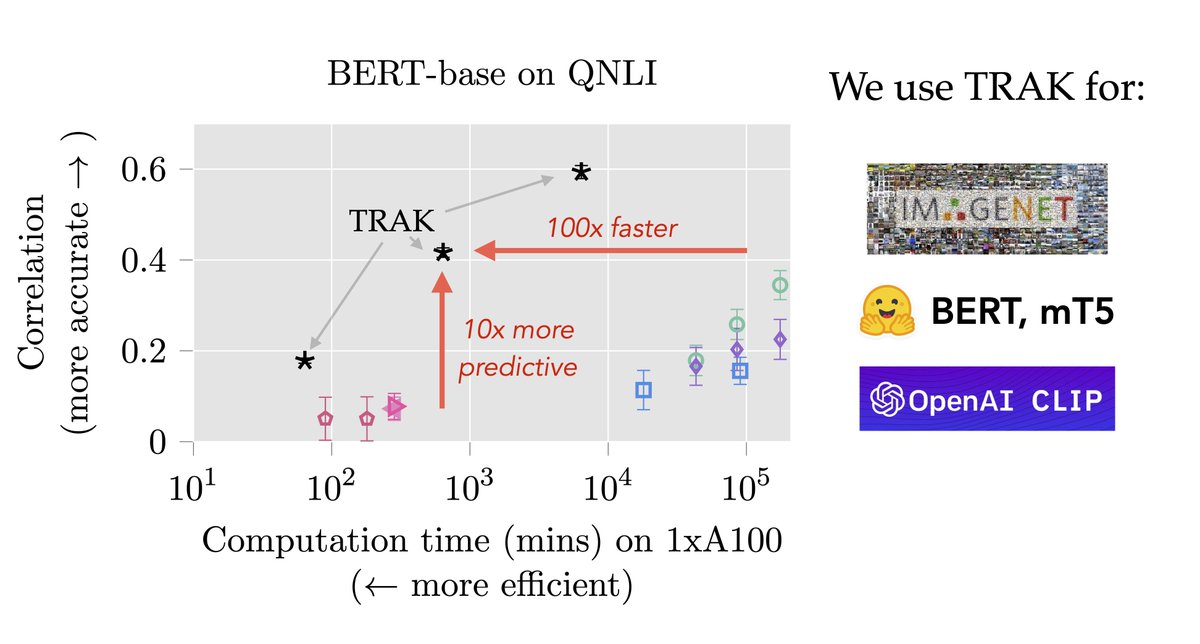 Turns out: Existing data attribution methods don't scale---they're either too expensive or too inaccurate. But TRAK can handle ImageNet classifiers, CLIP, and LLMs alike. (2/6)
Turns out: Existing data attribution methods don't scale---they're either too expensive or too inaccurate. But TRAK can handle ImageNet classifiers, CLIP, and LLMs alike. (2/6)
 Remember when Trevor shared (on Instagram) a photo with @michaelkosta at a tennis game? (2/8)
Remember when Trevor shared (on Instagram) a photo with @michaelkosta at a tennis game? (2/8) 
 We trained *hundreds of thousands* of models on random subsets of computer vision datasets using our library FFCV (ffcv.io). We then used this data to fit *linear* models that can successfully predict model outputs. (2/6)
We trained *hundreds of thousands* of models on random subsets of computer vision datasets using our library FFCV (ffcv.io). We then used this data to fit *linear* models that can successfully predict model outputs. (2/6) 

 FFCV is easy to use, minimally invasive, fast, and flexible: github.com/MadryLab/ffcv#…. We're really excited to both release FFCV today, and start unveiling (soon!) some of the large-scale empirical work it has enabled us to perform on an academic budget. (2/3)
FFCV is easy to use, minimally invasive, fast, and flexible: github.com/MadryLab/ffcv#…. We're really excited to both release FFCV today, and start unveiling (soon!) some of the large-scale empirical work it has enabled us to perform on an academic budget. (2/3)