

 First, let's see what happens when we try to use A100s.
First, let's see what happens when we try to use A100s. Let's consider the widely used 7B param llama architecture.
Let's consider the widely used 7B param llama architecture.

 To be fair, they would have to use the diff/history data much more than the raw code.
To be fair, they would have to use the diff/history data much more than the raw code. The 14.7B param number comes from the scaling experiments they ran. The largest model in these experiments was 14.7B params
The 14.7B param number comes from the scaling experiments they ran. The largest model in these experiments was 14.7B params
 Not only that, but 10x better pricing than text-davinci, and far lower latency.
Not only that, but 10x better pricing than text-davinci, and far lower latency.
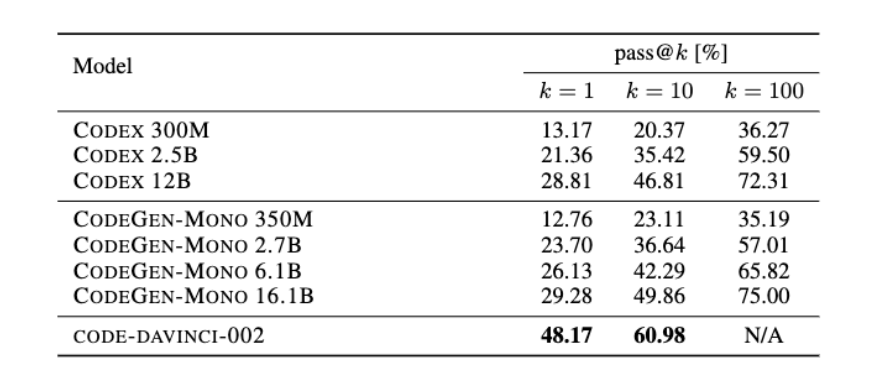 The earlier version of Codex was only finetuned on 159GB of python Code (probably just 50B tokens).
The earlier version of Codex was only finetuned on 159GB of python Code (probably just 50B tokens).