-ngl 99 here isn't a typo, full 12B dense, every layer on GPU, on an 8GB card. that's the part worth sitting with. The model has vision, audio input, thinking/reasoning and fits your 8GB card.
TurboQuant's KV cache savings are what free up the room to do that at 120k context.
side by side with yesterday: 26B A4B MoE got 320+ tok/s prefill. this dense 12B is clearing 1000+
rig: RTX 4060 8GB · i7H · 16GB RAM
same two flags as yesterday, different model size:
--cache-type-k q8_0 --cache-type-v turbo3
thanks to TheTom/llama-cpp-turboquant, TurboQuant fork of llama.cpp by Tom Turney (@no_stp_on_snek) to make this work.
unsloth's model quant huggingface and the llama.cpp fork github link in the comments
Do you prefer a dense or a MoE for your 8GB card?
GitHub - TheTom/llama-cpp-turboquant: LLM inference in C/C++ · GitHub github.com/TheTom/llama-c…
Jun 8 • 4 tweets • 3 min read
Run Gemma 4 26b MTP on 8 GB VRAM GPUs at 25+ tokens/second. Flags included!
local llm space is moving at terminal velocity. only 3 days ago google released gemma 4 26b a4b qat quants. more efficient than before, ran on 8gb vram at 20 tok/sec.
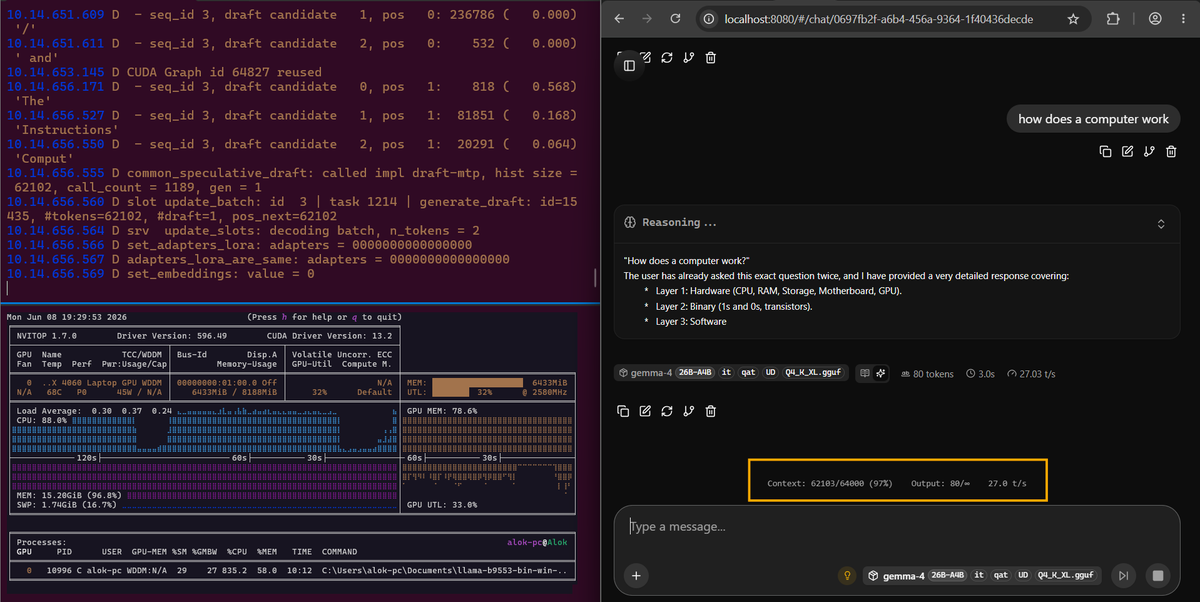
and now just a few hours ago, mainline llama.cpp merged a massive update and we just shattered our own record. decode throughput went 25-40% up on the same 8 GB VRAM setup!
Before MTP: 20 tps -> After MTP: 28 tps!
llama.cpp just officially merged PR #23398 ("add Gemma4 MTP"), bringing native Multi-Token Prediction (MTP) support to Gemma 4 models.
By running speculative drafting on the same 8GB VRAM RTX 4060 setup, my decode throughput on a 64k context instantly leaped to a blistering 25–27 tokens/sec thats 25-30% increase with the same hardware.
Here is the architectural catch you need to know: Unlike the Qwen 3.5 and 3.6 series, which bake the MTP heads directly into the base GGUF, the Gemma 4 MTP head is not built in.
You must download a separate, specialized MTP drafter GGUF (the assistant model) to act as the speculator. (I've dropped the download link in the replies).