This will not happen simply by fiddling with model architectures. They will ONLY learn this signal when fine tuned on large scale genome perturbation & rearrangement coupled with molecular readouts. 2/
Jun 25, 2025 • 9 tweets • 2 min read
This a really exciting leap forward for genomic sequence to activity gene regulation models. It is a genuine improvement over pretty much all SOTA models spanning a wide range of regulatory, transcriptional and post-transcriptional processes. 1/
Combines several key ideas (a) base-pair resolution profile models (b) sequence context to 1MB (c) unify 1D and 3D tracks (d) simultaneously model multiple readouts across cell contexts (e) model distillation enabling predictive boost of ensembles from a single model. 2/
Jun 19, 2025 • 18 tweets • 3 min read
Ok a few quick things.
Most CS students who get into elite PhD programs in AI especially have already usually published multiple first author papers in "top" conferences. 1/
These students typically have had access to incredible research opportunities in academia during their undergrads & have spent substantial time doing research already. 2/
Feb 27, 2024 • 20 tweets • 3 min read
Great application of DNA language models to prokaryotic genomes. Excellent impactful application use cases of the model. Congrats to all the authors!
But a quick answer to the first question. No - DNA is not all you need. 1/
While incredibly impressive, lets just take the zero-shot gene expression prediction performance of the model (Spearman 𝑟 = 0.41). This is extremely low for a prokaryotic genome 2/
Sep 5, 2023 • 20 tweets • 4 min read
@vitaliikl @neal_amin @drklly @tangming2005 Sequence is static across cells but varies across the genome. Transfactor activity varies across cell types but are static in any cell across the genomic axis (this is not entirely true but ok for a first approx). 2/
@vitaliikl @neal_amin @drklly @tangming2005 So if we want to predict say expression (E[c,g]) coverage in any cell (c) at any specific genomic location (g), we need to learn a function that minimally models sequence context of g, S[g] & activity of all transfactors in cell c ie. A[c]. 3/
May 28, 2023 • 48 tweets • 7 min read
This is a great thread. Below, a few opinionated thoughts on modeling, interpretation, evaluation choices that are unlikely to be useful directions to pursue for predictive regulatory sequence models: 1/
Binarizing signal (eg classifying peaks vs background): please stop this practice for 2 main reasons. Massive loss of info (effect sizes matter), substantial instability of binary models 2/
May 24, 2022 • 13 tweets • 3 min read
PSA: DeepBind was a revolutionary model of TF binding in 2015, the first neural network model of binding. But it is worth noting that the DeepBind architecture is pretty much an additive motif model. Here is what it does 1/
It learns PWM-like motif units called convolutional filters, scans and scores a sequence with each unit, thresholds the score, takes the max value of each unit over the entire sequence & learns a logistic regression additive model over all units. That's it. 2/
May 23, 2022 • 5 tweets • 1 min read
Excellent work. A great decomposable approach for first order PWM motif discovery using neural additive models. A fast, powerful, scalable, predictive replacement for classic motif discovery tools (e.g. MEME/HOMER etc). 1/
A few important caveats (many of which are clearly stated in the paper) (1) this approach is restricted to specific additive architectures, which are often not optimal for different modeling / discovery objectives & data types 2/
Feb 19, 2022 • 4 tweets • 1 min read
A quick word of advice to all budding scientists. Learning how to do science and how to communicate science (writing, visuals and presentation) are often the hardest skills with steep learning curves. So best to start sharpening these skills early. 1/
Would particularly like to direct this advice to high schoolers and undergrads from India (which is where I grew up). The education system in India almost entirely ignores these skills. And it is a major hurdle for many bright students. 2/
Jun 13, 2020 • 11 tweets • 3 min read
Check out latest work, led by the brilliant Alex Tseng w/ @avshrikumar on using Fourier based attribution priors to stabilize & improve feature attribution scores derived from neural network models in regulatory genomics. biorxiv.org/content/10.110… 1/
Feature attribution methods such as DeepLIFT/DeepSHAP, Integrated gradients and ISM are commonly used to infer base-resolution importance scores from NN models of regulatory DNA sequence trained on various molecular read outs (TF binding, chromatin accessibility etc.) 2/
May 6, 2020 • 5 tweets • 2 min read
After 4 months of effort (2 months of very disciplined effort - 2 hours every night), I've finished my second manual scan of the entire GRCh38 human genome assembly + 900 DNase tracks (processed 3 different ways) + Input DNA tracks repeat masker. For what you ask?
THE BLACKLIST! New manually annotated version that reconciles 3 auto-generated blacklists. Releasing soon at an @EncodeDCC portal near you!
Jul 19, 2018 • 8 tweets • 2 min read
This is very sound advice. But I'd like to encourage applied data scientists to learn about deep learning. It's a very powerful toolkit, very appropriate for many bio problems with large datasets requiring integration of diverse structured input data types. 1/
And the only way to learn to use NNs is by working with them. Do an actual project with them. Consult with someone familiar with NN to make sure that the problem/dataset is a good match for NNs. 2/
External Tweet loading...
If nothing shows, it may have been deleted
by @biorxivpreprint view original on Twitter
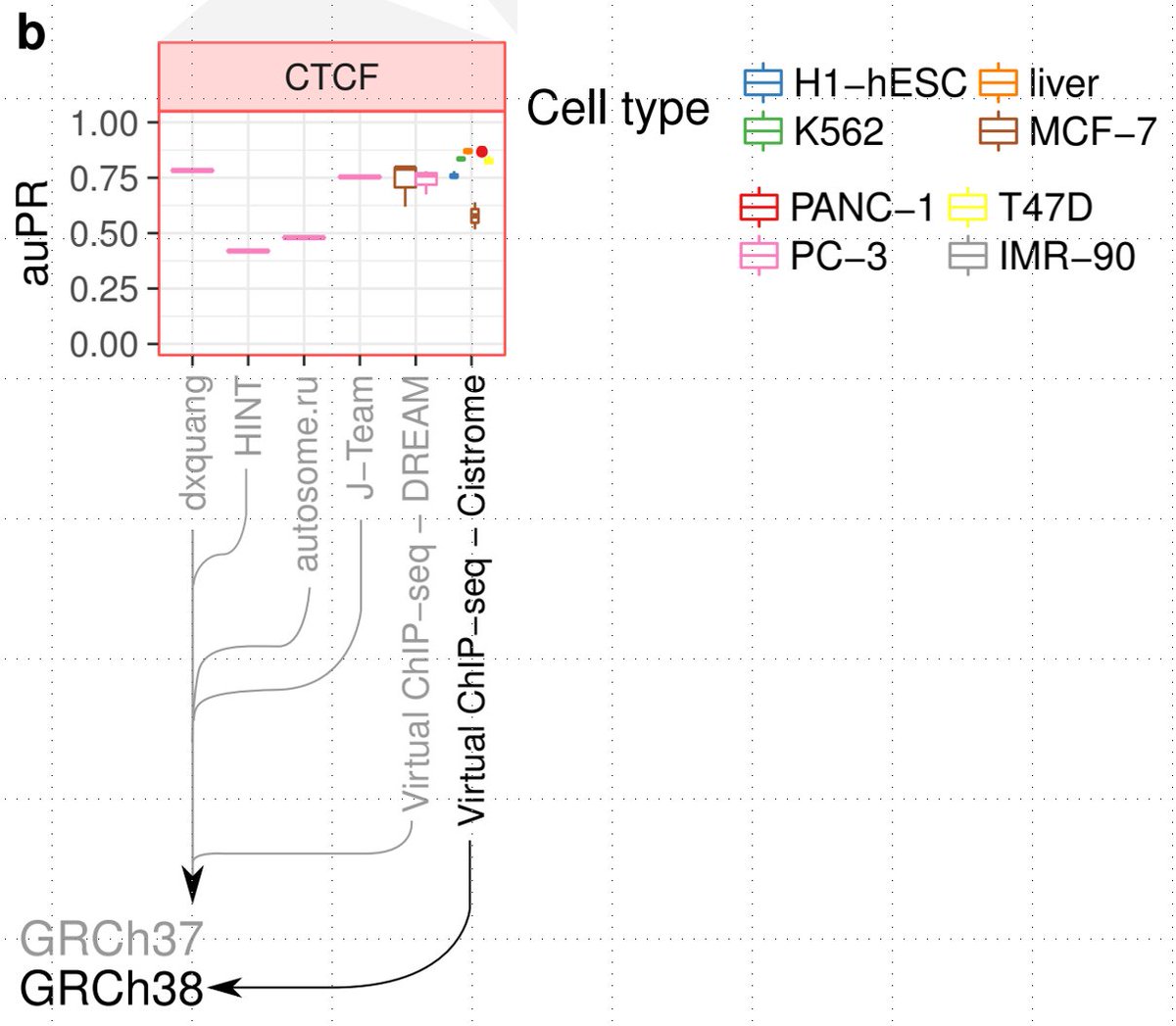
In summary, the paper proposes a powerful imputation based approach for predicting TF binding in NEW cell types. Note that this is the practical prediction problem. Not cross-validation, where u simply hold out chromosomes in cell types where u already have TF ChIP-seq data 1/