
 In bioinformatics, it discovered 40 novel methods for single-cell data analysis that outperformed the top human-developed methods on a public leaderboard.
In bioinformatics, it discovered 40 novel methods for single-cell data analysis that outperformed the top human-developed methods on a public leaderboard. 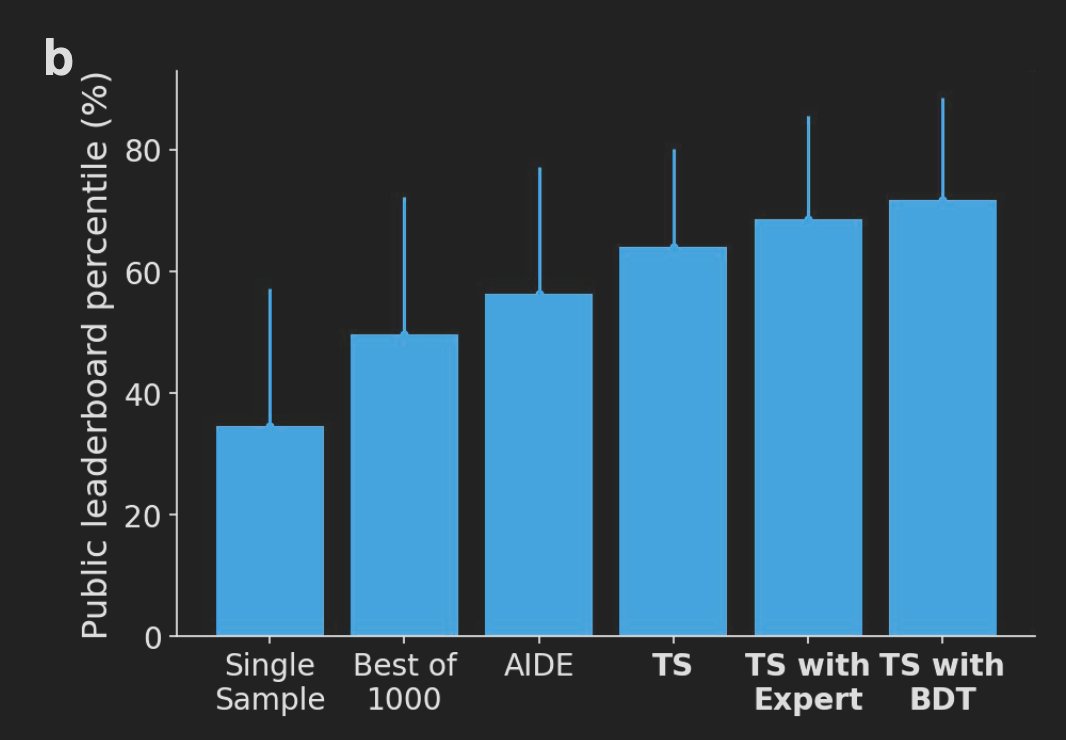
 If you have a linear layer F(x) := W_0x, gradient descents transform it to F(x) in this image, where LinearAttn is attention over every token / timestep (X’) from all observed training data with their respective gradient (E) as value.
If you have a linear layer F(x) := W_0x, gradient descents transform it to F(x) in this image, where LinearAttn is attention over every token / timestep (X’) from all observed training data with their respective gradient (E) as value. 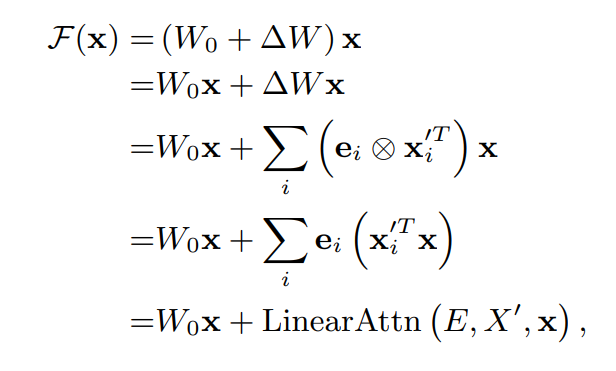
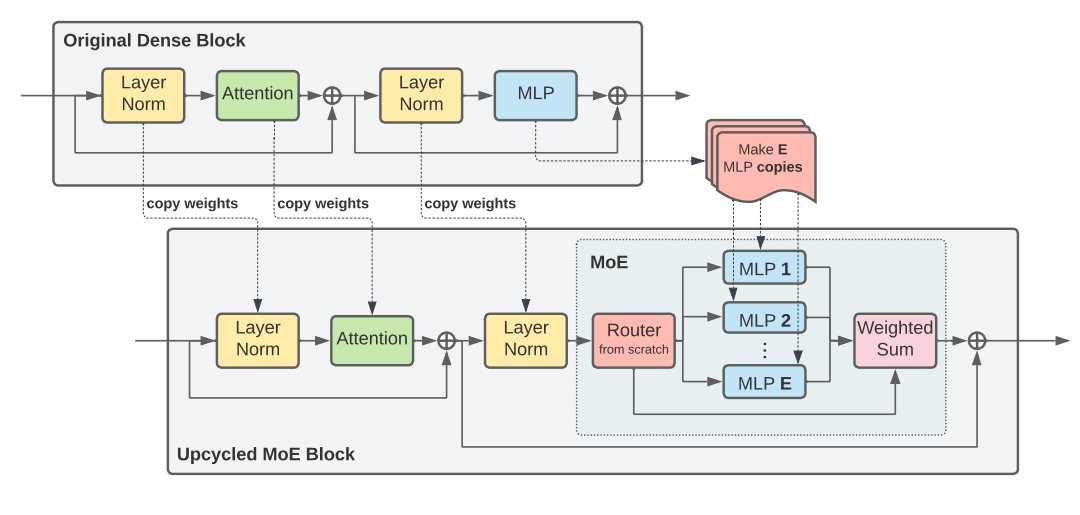 As this figure shows, Sparse Upcycling outperforms the dense continuation on ViT and T5 in terms of extra pretraining time. (2/N)
As this figure shows, Sparse Upcycling outperforms the dense continuation on ViT and T5 in terms of extra pretraining time. (2/N) 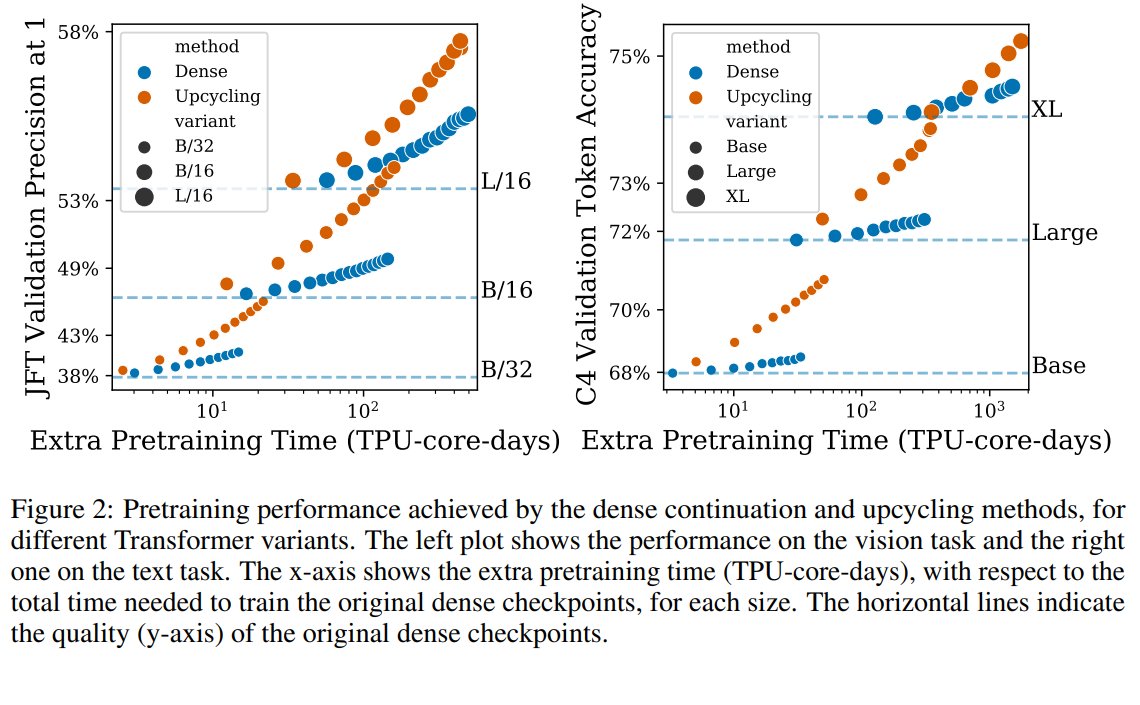
 Colab: bit.ly/3w0fB6n
Colab: bit.ly/3w0fB6n