CEO and Co-founder @datologyai working to make it easy for anyone to make the most of their data. Former: RS @AIatMeta (FAIR), RS @DeepMind, PhD @PiN_Harvard.
 In work led by Ben Sorscher and Robert Geirhos and done in collaboration with @sshkhr16 and @SuryaGanguli, we show both theoretically and empirically that exponential scaling is possible even on ImageNet so long as you can accurately rank data point importance.
In work led by Ben Sorscher and Robert Geirhos and done in collaboration with @sshkhr16 and @SuryaGanguli, we show both theoretically and empirically that exponential scaling is possible even on ImageNet so long as you can accurately rank data point importance. 
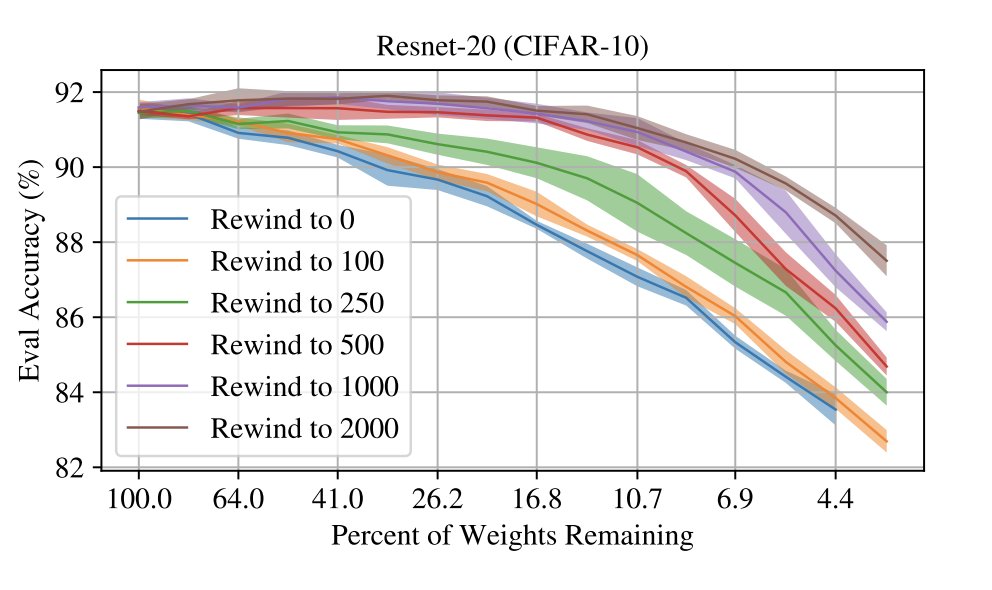
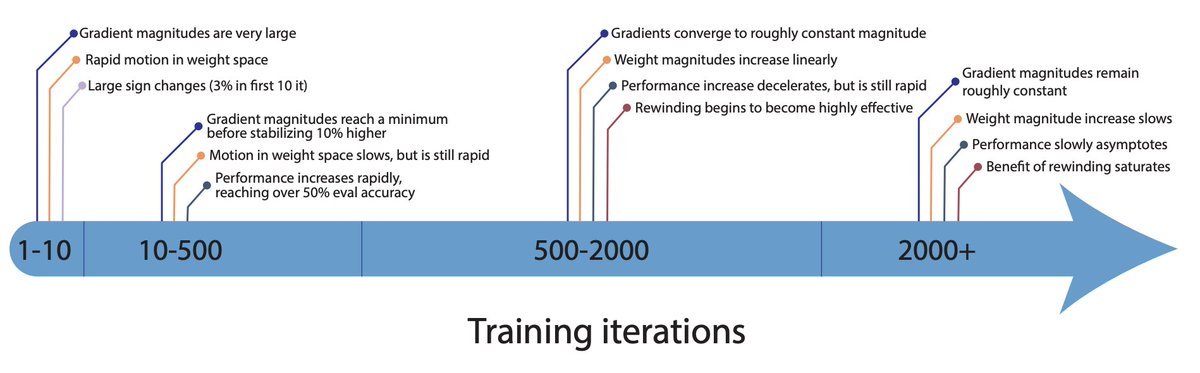 @jefrankle @davidjschwab Existing methods can't find winning lottery tickets at init on larger networks. Instead, they only seem to emerge early in training. We exploit this in our experiments by as a causal way to measure the impact of various network properties on this early phase of training.
@jefrankle @davidjschwab Existing methods can't find winning lottery tickets at init on larger networks. Instead, they only seem to emerge early in training. We exploit this in our experiments by as a causal way to measure the impact of various network properties on this early phase of training.