
CEO&Founder @GenPeachAI, x-Staff Research Scientist @Meta GenAI
PhD in Computer Vision @ Heidelberg University,
@Kaggle Competitions Master (Top-50 worldwide)
 1/ Instead of directly predicting the latent code of a given real image using a single pass, the encoder is tasked with predicting a residual with respect to the current estimate. The initial estimate is set to just average latent code across the dataset. ...
1/ Instead of directly predicting the latent code of a given real image using a single pass, the encoder is tasked with predicting a residual with respect to the current estimate. The initial estimate is set to just average latent code across the dataset. ...
 1/
1/ 
 1/
1/ 
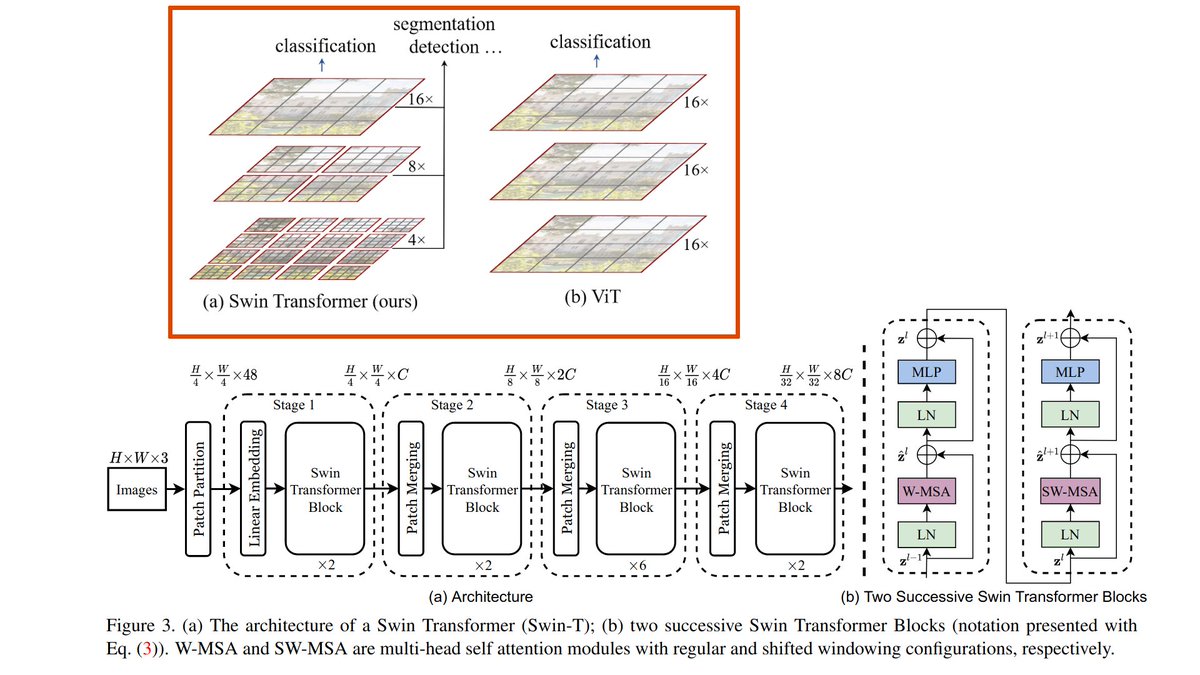 2/
2/  2/ Point to a location in a synthesized image and apply an arbitrary new concept such as “rustic” or “opulent” or “happy dog.”
2/ Point to a location in a synthesized image and apply an arbitrary new concept such as “rustic” or “opulent” or “happy dog.” 
 Specifically, the Meta-DETR first encodes both support and query images into category-specific
Specifically, the Meta-DETR first encodes both support and query images into category-specific

 1/ The main idea is to factorize the voxel color representation into two independent components: one that depends only on positions p=(x,y,z) of the voxel and one that depends only on the ray directions v.
1/ The main idea is to factorize the voxel color representation into two independent components: one that depends only on positions p=(x,y,z) of the voxel and one that depends only on the ray directions v. Using latent space regression to analyze and leverage compositionality in GANs
Using latent space regression to analyze and leverage compositionality in GANs