Scaling GenAI Systems @Youtube | Building AI powered video editing | Ex - @Google Search, @Microsoft Azure | AI + Backend | views my own
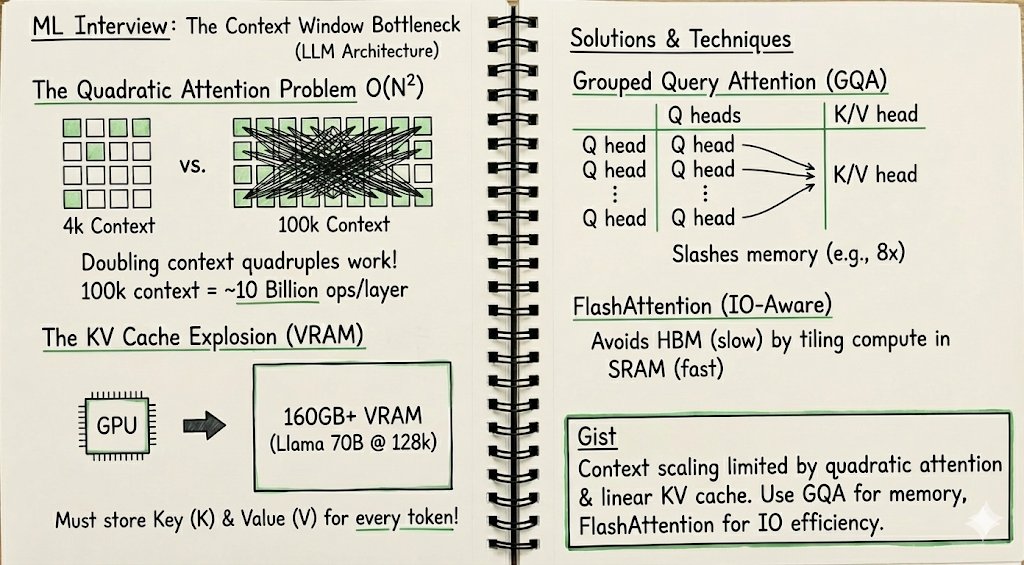 Don't say: "It makes the model too slow."
Don't say: "It makes the model too slow."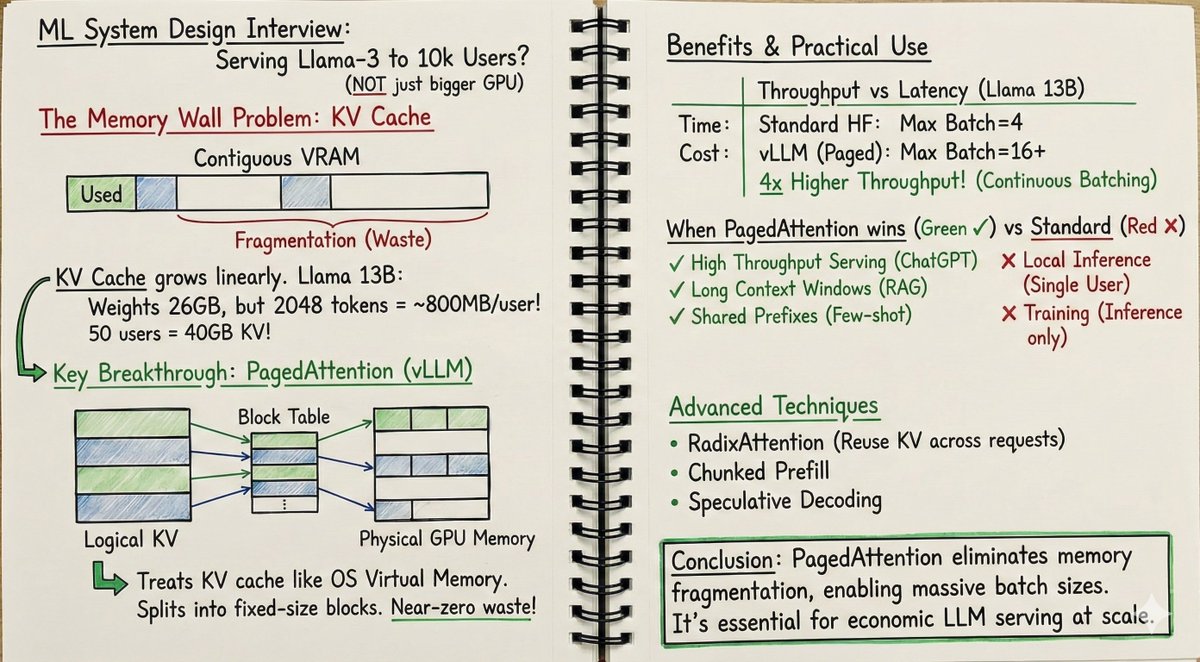 Don't say: "Just use a bigger GPU."
Don't say: "Just use a bigger GPU." 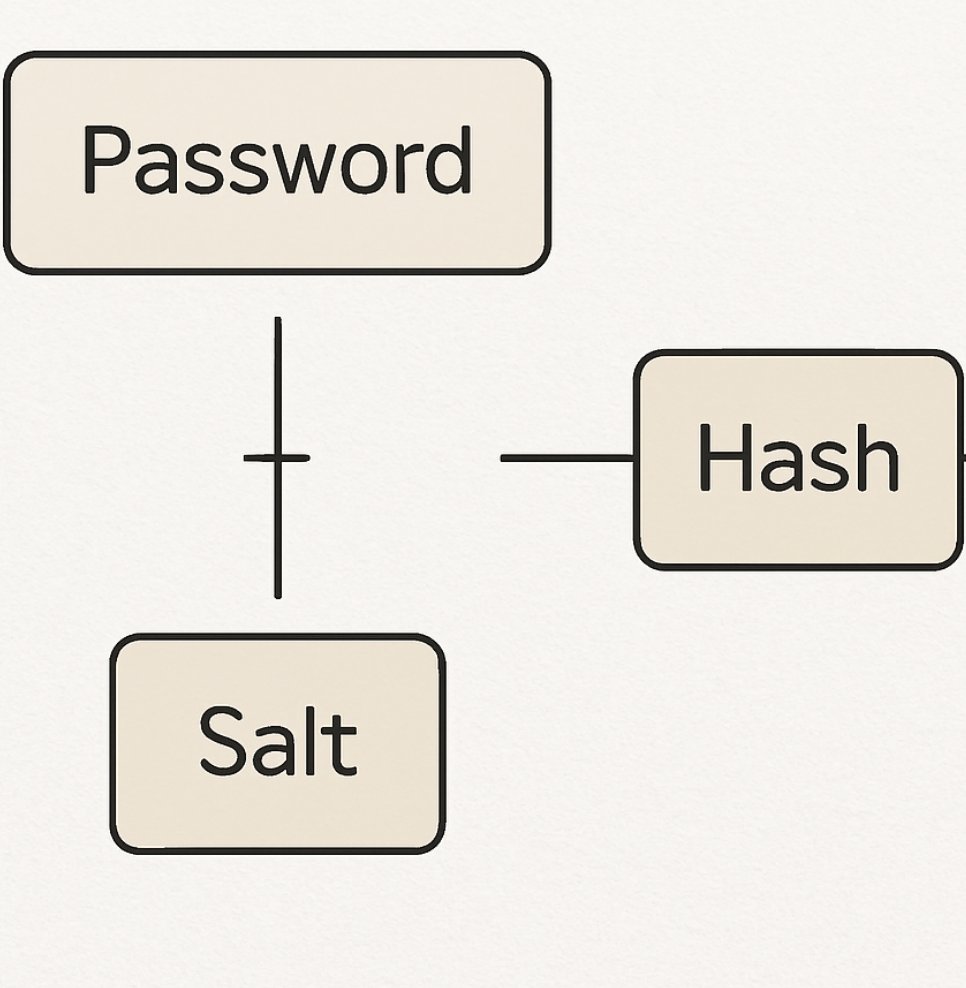
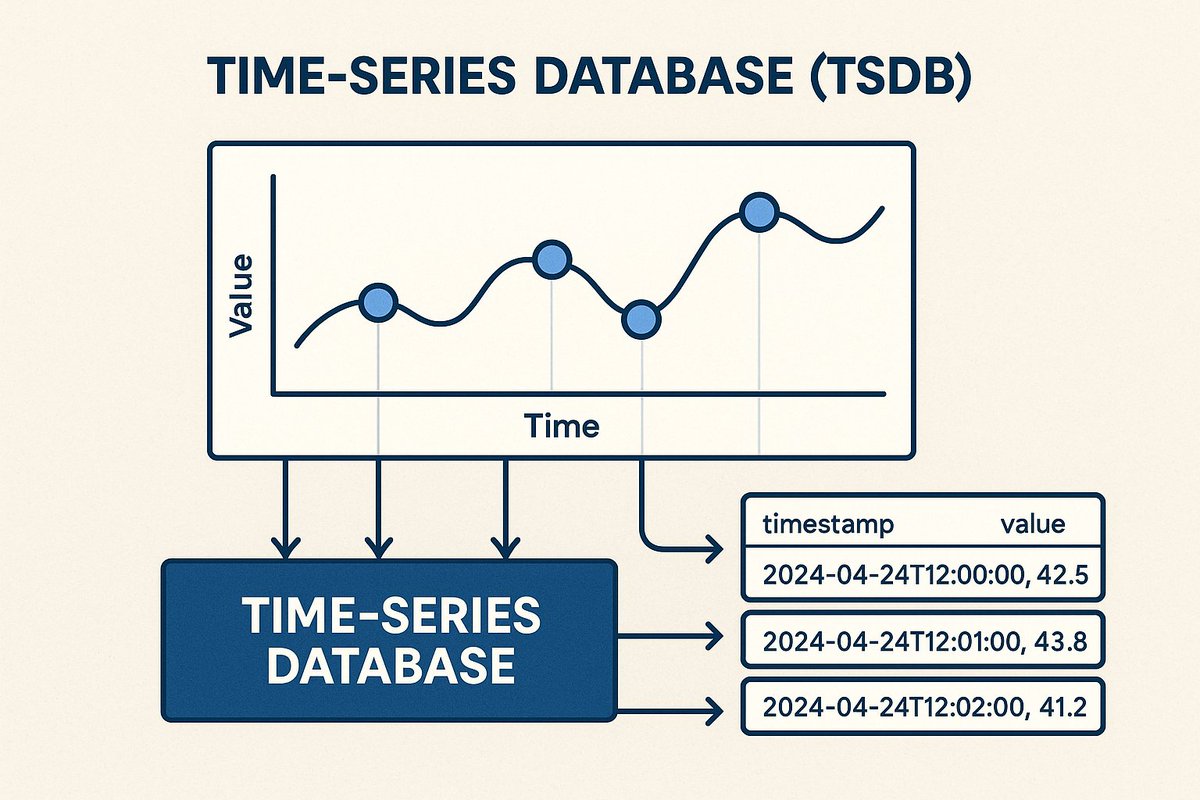
 The magic keyword is Time-Series Database (TSDB).
The magic keyword is Time-Series Database (TSDB).