
Author of the book Hands-On #MachineLearning with #ScikitLearn, #Keras and #TensorFlow. Former PM of #YouTube video classification. Founder of telco operator.
 Other Python 3.5 features I often use:
Other Python 3.5 features I often use: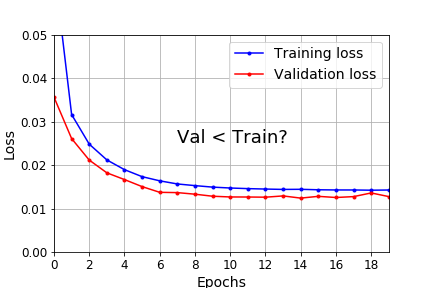 The most common reason is regularization (e.g., dropout), since it applies during training, but not during validation & testing. If we add the regularization loss to the validation loss, things look much different. 2/5
The most common reason is regularization (e.g., dropout), since it applies during training, but not during validation & testing. If we add the regularization loss to the validation loss, things look much different. 2/5 
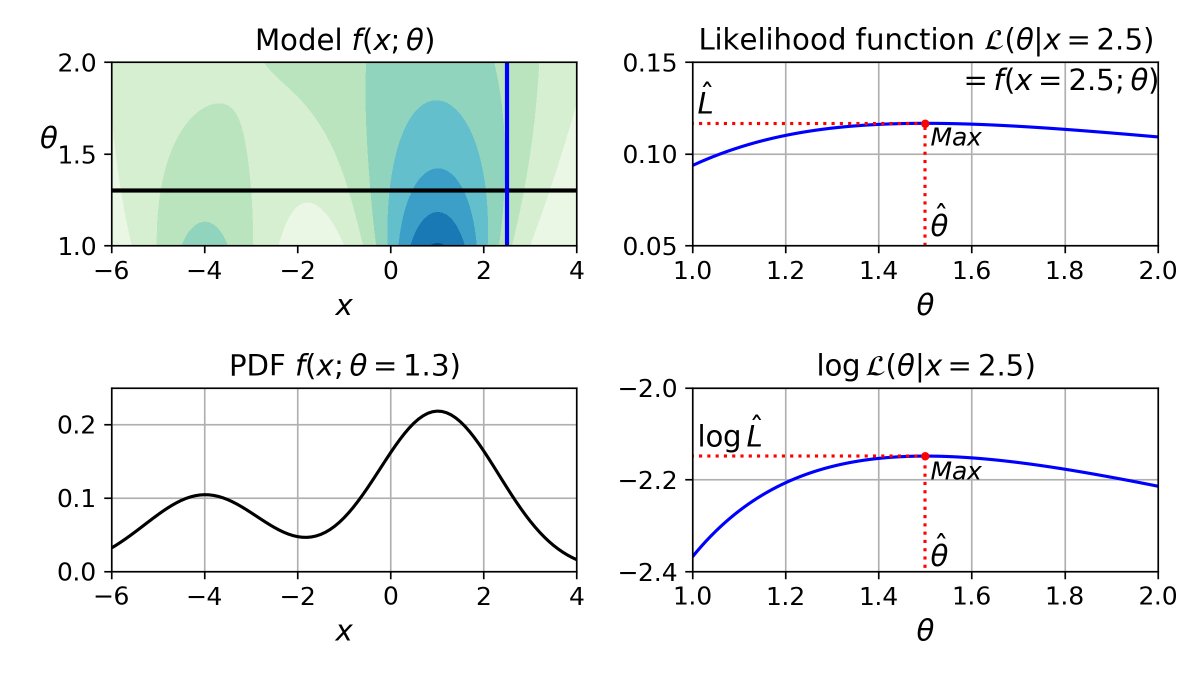 Consider a probabilistic model f(x; θ) (top left). If you set the model parameter θ (top left, black horizontal line), you get a probability distribution over x (lower left). In this case, x is a continuous variable, so we get a probability density function (PDF). 2/8
Consider a probabilistic model f(x; θ) (top left). If you set the model parameter θ (top left, black horizontal line), you get a probability distribution over x (lower left). In this case, x is a continuous variable, so we get a probability density function (PDF). 2/8